在等吴恩达深度学习第5课的时候,你可以先看看第4课的笔记

大数据文摘作品
编译:党晓芊、元元、龙牧雪
等待吴恩达放出深度学习第5课的时候,你还能做什么?今天,大数据文摘给大家带来了加拿大银行首席分析师Ryan Shrott的吴恩达深度学习第4课学习笔记,一共11个要点。在等待第5门课推出的同时,赶紧学起来吧!
这两天,听说大家都被一款叫做“旅行青蛙”的游戏刷屏了,还有许多人在票圈喊着“养男人不如养蛙”。

在这个“云养蛙”的佛系游戏里,只有两种状态:蛙儿子在家和不在家。蛙儿子在家的时候,你只能一心盼他出门,啥也干不了。蛙儿子出门了,你也不知道他要多久才能回家,只能等着他回来——还是啥也干不了。
当然,青蛙出门在外的日子里,他偶尔会给等待中的你寄张明信片回来。
还有什么等待比等青蛙旅行回家还漫长吗?
有的。那就是等吴恩达的deeplearning.ai放出第5门课。

自从去年8月吴恩达的深度学习系列课程在Coursera上线(戳蓝字看大数据文摘相关测评《票圈被吴恩达新开的深度学习课程刷屏?到底如何,我们帮你做了个测评》、《免费!你们要的吴恩达深度学习课程【汉化】视频来了!》),这门Sequence Models课程一直处于coming soon的状态,上线日期从去年底一直跳票到今年一月。
在漫长的等待过程中,已经有不少童鞋学完了这一系列的前4门课,大数据文摘也发布过前3课的学习笔记《我从吴恩达深度学习课程中学到的21个心得:加拿大银行首席分析师“学霸“笔记分享》。
今天,我们再次给大家带来了这位国际友人的吴恩达深度学习第4课学习笔记,一共11个要点。边学习边等待的过程,又何尝不是一种幸福呢。同时,课程笔记里还有狗粮放出,请大家注意接收!
***
我最近学完了吴恩达在Coursera上关于计算机视觉的课程。吴恩达的课程非常精彩,他详细解释了很多用来优化计算机视觉的复杂的概念。我最喜欢的是关于神经风格迁移的部分(见第十二课),这个方法可以让你用任意内容的绘画创造出莫奈风格的艺术作品。请看下面的例子:

这篇文章中,我将会讨论我在课程中学到的12个关键点。请注意,这个课程是deeplearning.ai所发布的深度学习系列课程的第四部分。
第一课:为什么计算机视觉能够发展迅速
大数据以及算法开发将会使智能系统的测试误差逐渐趋近于贝叶斯最优误差。这个结果将会导致人工智能的表现全方位超越人类,其中包括自然识别方面的工作。像TensorFlow这样的开源软件,就可以帮助你用迁移学习的方法迅速实现其任何物体的探测器。用迁移学习的方法你只需要大约100-500个训练实例就可以得到很好的结果。手动标记100个实例的工作量并不太,所以你可以很快得到一个最小化可用模型。
第二课:卷积是如何工作的?
吴恩达解释了如何实现卷积算符并展示了如何用它检测物体边缘。他同时还解释了其他的过滤器,比如说索贝尔过滤器(Sobel filter),这种过滤器在图像边缘中部采用更大的比重。然后,吴恩达解释了这些过滤器的比重并不是靠人为设计的,而是依靠类似于梯度下降的这样的爬山算法由计算机自行训练出来的。
第三课:为什么要用卷积?
吴恩达透彻的解释了卷积适用于图像识别的原因。其中有两个具体的原因。第一个是参数共享。大体的想法是如果一个特征探测器对于图像的某一部分很有效,这个探测器很可能对图像的其他部分也有效。比如说,一个边缘探测器可能对图像的很多部分都有用。特征分享的方法能够降低系统参数的数量,同时能够带来稳健的平移不变性(translation invariance)。平移不变性是一个概念,意思是比如说有一张猫的图片,即使是经过了移动和旋转,依旧是一只猫的图片。
第二个原因被称作稀疏连结性,即每个输出层仅仅由很小一部分输入结点计算得到(更具体一些,输入的数量是过滤器数量的平方)。用这个方法可以极大的减少网络中参数的数量,提高训练速度。
第四课:为什么使用填充(Padding)?
填充通常用来保持输入的数量(也就是说,使得输入输出的维度相同)。用这个方法也可以保证在进行训练时,来自图片边缘的贡献和来自中心的贡献相当。
第五课:为什么使用最大池化层(Max Pooling)?
实证研究证明,最大池化层对于CNN非常有效。通过对图像向下取样,我们减少了参数数量,同时也确保图像特征在图像尺度变化或者方向变化时保持不变。
第六课:经典网络架构
吴恩达展示了3种经典的神经网络架构,包括LeNet-5, AlexNet 和VGG-16。他所展示的主要观点是一个有效的神经网络通常是通道的数目不断上升,宽度和高度不断下降。
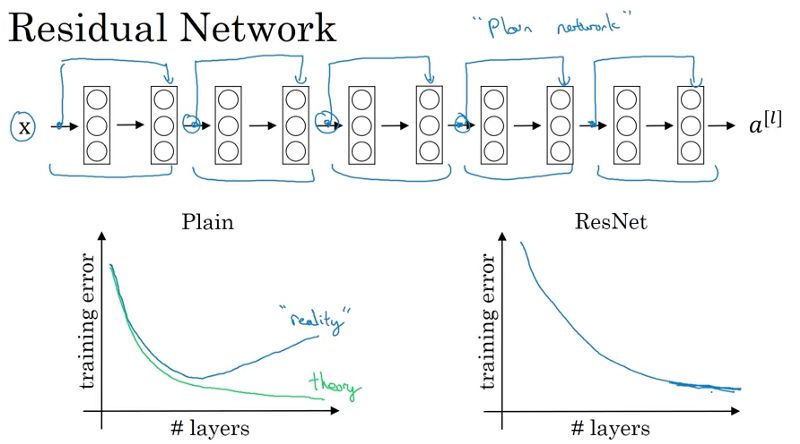
第七课:为什么ResNets 有效?
对于一般的神经网络,由于梯度的消失和爆炸,训练误差并不会随着网络层数的增加而单调递减。然而对于ResNets而言,可以通过向前跳跃性连接,让你在训练一个很大的神经网络时,误差单调下降,性能单调递增。
第八课:使用迁移学习!
如果从头开始训练一个像inception这种结构巨大的神经网络,即使在GPU上训练也可能需要好几周的时间。你可以下载经过预训练得到的权重,然后只重新训练最后的softmax层(或者最后几个层)。这个会极大缩短训练时间。这种方法有效的原因是前几层所训练的特征很可能是诸如边界或者弯曲线条之类的所有图像的共同特征。
第九课:如何在计算机视觉竞赛中获胜
吴恩达解释说,你需要独立的训练多个神经网络然后取结果的平均值,来获得更好的结果。一些数据增强的技术,比如说随机裁剪图片,沿水平垂直轴翻转图像可以帮助提升模型表现。总之,你一开始应该使用开源软件库和预训练模型,然后根据自己要解决的问题不断细化模型,调整参数。
第十课:如何实现对象检测
首先,吴恩达解释了从图片中检测标志性物体的思路。基本上来说,这些标志性物体将成为最终输出结果的一部分。通过一些有效的卷积操作,你会得到一个输出值,表示一个物体出现在某个区域的概率和区域的位置。同时,他解释了如何通过交集并集商评估对象检测器的有效性。最后,吴恩达结合所有构成要素,解释了著名的YOLO算法。
第十一课:如何实现面部识别
面部识别是一个单样本学习(one-shot learning)问题,因为你有可能只能根据一张示例图片来辨别一个人。解决问题的方法是使用相似性函数,这个函数可以给出两个图像之间的相似程度。所以,如果两张图像是同一个人,你希望这个函数输出一个较小的数值;不同人的两张图像则输出较大的数值。
吴恩达给出的第一个解决方案被称作siamese网络。它的基本思路是将两张不同的图片输入到同一个神经网络然后比较结果。如果输出相似性很高,那么很有可能是同一个人。神经网络训练的目标就是如果两个输入的图片是同一个人,那么输出的结果距离相对很小。
对于第二种解决方案,他给出了一个三元损失方法(triplet loss method)。这个方法是,从三张图片(Anchor (A), Positive (P) and Negative (N))训练得到一个神经网络,使得 A与P 的结果相似程度远远高于A与N的结果相似程度。

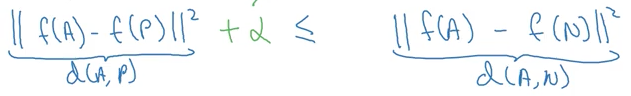
注意,此图中有狗粮!(为什么说这是狗粮?请看大数据文摘此前报道《吴恩达CNN新课上线!deeplearning.ai 4/5解锁,6日开课》)
第十二课:如何用神经风格迁移(Neural Style Transfer)的方法创造艺术作品
吴恩达解释了如何结合风格和内容创造新的图画。示例如下。神经风格迁移方法的核心在于充分理解神经网络中每一个卷积层对应的具体的视觉表征。实际表明,网络当中前几层通常学习简单的特征,比如图像边缘。后几层通常学习一些复杂的对象,比如脸,脚,汽车等。

为了创建一个神经风格转移图画,你只需要定义一个结合风格和内容相似性的凸函数作为损失函数。具体而言,这个函数可以写成:
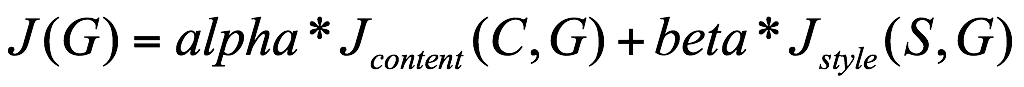
在这个方程中,G是被创造出的图像,C是图像内容,S是图像风格。简单的采用梯度下降法来对损失函数就生成图像求最小值。
基本步骤如下:
1. 随机生成G。
2. 使用梯度下降方法最小化J(G),通过这个等式: G:=G-dG(J(G))
3. 重复第二步。
结论:
完成这门课程之后,你会对大量计算机视觉方面的文献有一个直观的认识。同时课后作业让你有机会自己实现部分算法。完成这门课程后,你不会很快成为一个计算机视觉方面的专家,但是它可能会开启你计算机视觉相关的想法和事业。
你也学完了吴恩达深度学习系列课的前4门课吗?还是仍停留在第一课第一讲?欢迎留言和我们分享。
原文链接:
https://www.kdnuggets.com/2017/12/ng-computer-vision-11-lessons-learnied.html
【今日机器学习概念】
Have a Great Defination

线下课程推荐|机器学习和人工智能方向
新年新目标,稀牛喊你找工作啦!
✪ 高频面试考点
✪ 行业项目经验
✪ 简历修改完善
✪ 面试注意事项
VIP小班授课,定制化服务,2018春招Offer触手可即!
志愿者介绍
回复“志愿者”加入我们







