放弃幻想,全面拥抱 Transformer(二):自然语言处理三大特征抽取器(CNN/RNN/TF)比较

AI 科技评论按:本文作者是张俊林老师,他是中国中文信息学会理事,中科院软件所博士,目前在新浪微博 AI Lab 担任资深算法专家。在此之前,张俊林老师曾在阿里巴巴任资深技术专家并负责新技术团队,也曾在百度和用友担任技术经理及技术总监等职务。同时他是技术书籍《这就是搜索引擎:核心技术详解》(该书荣获全国第十二届优秀图书奖)、《大数据日知录:架构与算法》的作者。本文首发于知乎,经作者许可,雷锋网 AI 科技评论进行转载。
本部分为下篇。点击查看本文上篇内容
华山论剑:三大特征抽取器比较
结合 NLP 领域自身的特点,上面几个部分分别介绍了 RNN/CNN/Transformer 各自的特性。从上面的介绍,看上去好像三大特征抽取器在 NLP 领域里各有所长,推想起来要是把它们拉到 NLP 任务竞技场角斗,一定是互有胜负,各擅胜场吧?
事实究竟如何呢?是三个特征抽取器三花齐放还是某一个一枝独秀呢?我们通过一些实验来说明这个问题。
为了更细致和公平地做对三者进行比较,我准备从几个不同的角度来分别进行对比,我原先打算从以下几个维度来进行分析判断:句法特征提取能力;语义特征提取能力;长距离特征捕获能力;任务综合特征抽取能力。上面四个角度是从 NLP 的特征抽取器能力强弱角度来评判的,另外再加入并行计算能力及运行效率,这是从是否方便大规模实用化的角度来看的。
因为目前关于特征抽取器句法特征抽取能力方面进行比较的文献很少,好像只看到一篇文章,结论是 CNN 在句法特征提取能力要强于 RNN,但是因为是比较早的文章,而且没有对比 transformer 在句法特征抽取方面的能力,所以这块很难单独比较,于是我就简化为对以下几项能力的对比:
语义特征提取能力;
长距离特征捕获能力;
任务综合特征抽取能力;
并行计算能力及运行效率
三者在这些维度各自表现如何呢?下面我们分头进行说明。
语义特征提取能力
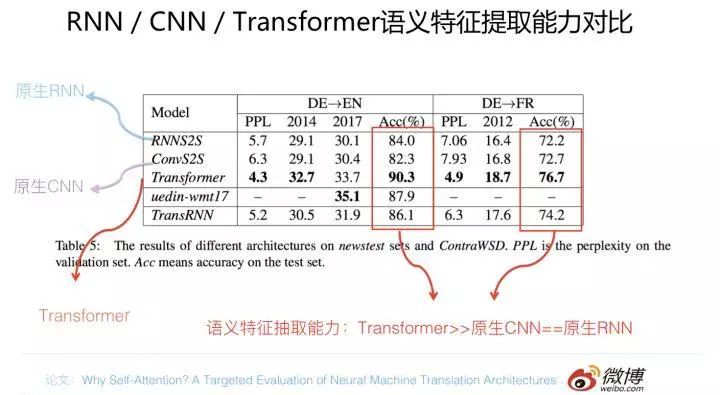
从语义特征提取能力来说,目前实验支持如下结论:Transformer 在这方面的能力非常显著地超过 RNN 和 CNN(在考察语义类能力的任务 WSD 中,Transformer 超过 RNN 和 CNN 大约 4-8 个绝对百分点),RNN 和 CNN 两者能力差不太多。
长距离特征捕获能力
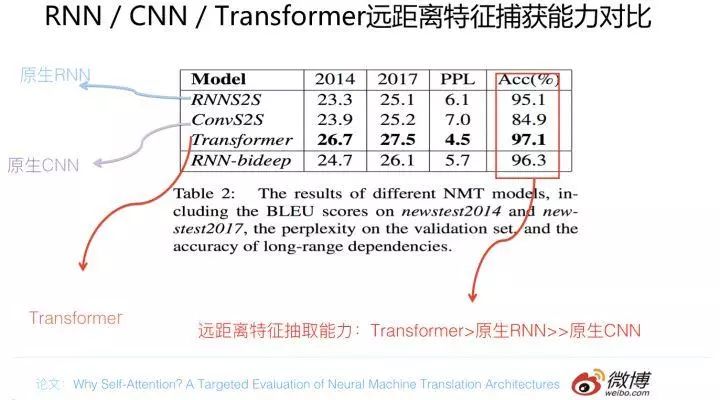
在长距离特征捕获能力方面,目前在特定的长距离特征捕获能力测试任务中(主语-谓语一致性检测,比如 we……..are…),实验支持如下结论:原生 CNN 特征抽取器在这方面极为显著地弱于 RNN 和 Transformer,Transformer 微弱优于 RNN 模型 (尤其在主语谓语距离小于 13 时),能力由强到弱排序为 Transformer>RNN>>CNN; 但在比较远的距离上(主语谓语距离大于 13),RNN 微弱优于 Transformer,所以综合看,可以认为 Transformer 和 RNN 在这方面能力差不太多,而 CNN 则显著弱于前两者。
那么为什么 CNN 在捕获长距离特征方面这么弱呢?这个我们在前文讲述 CNN 的时候就说过,CNN 解决这个问题是靠堆积深度来获得覆盖更长的输入长度的,所以 CNN 在这方面的表现与卷积核能够覆盖的输入距离最大长度有关系。如果通过增大卷积核的 kernel size,同时加深网络深度,以此来增加输入的长度覆盖。实验证明这能够明显提升 CNN 的 long-range 特征捕获能力。但是尽管如此,CNN 在这方面仍然显著弱于 RNN 和 Transformer。这个问题背后的原因是什么呢(因为上述主语-谓语一致性任务中,CNN 的深度肯定可以覆盖 13-25 这个长度了,但是表现还是很弱)?其实这是一个很好的值得探索的点。
对于 Transformer 来说,Multi-head attention 的 head 数量严重影响 NLP 任务中 Long-range 特征捕获能力:结论是 head 越多越有利于捕获 long-range 特征。在上页 PPT 里写明的论文出来之前,有个工作(论文:Tran. The Importance of Being Recurrent for Modeling Hierarchical Structure)的结论和上述结论不一致:它的结论是在」主语-谓语一致性」任务上,Transformer 表现是弱于 LSTM 的。如果综合这两篇论文,我们看似得到了相互矛盾的结论,那么到底谁是正确的呢?Why Self-attention 的论文对此进行了探索,它的结论是:这个差异是由于两个论文中的实验中 Transformer 的超参设置不同导致的,其中尤其是 multi-head 的数量,对结果影响严重,而如果正确设置一些超参,那么之前 Trans 的论文结论是不成立的。也就是说,我们目前仍然可以维持下面结论:在远距离特征捕获能力方面,Transformer 和 RNN 能力相近,而 CNN 在这方面则显著弱于前两者。
任务综合特征抽取能力
上面两项对比是从特征抽取的两个比较重要的单项能力角度来评估的,其实更重要的是在具体任务中引入不同特征抽取器,然后比较效果差异,以此来综合评定三者的综合能力。那么这样就引出一个问题:NLP 中的任务很多,哪些任务是最具有代表性的呢?答案是机器翻译。你会看到很多 NLP 的重要的创新模型都是在机器翻译任务上提出来的,这背后是有道理的,因为机器翻译基本上是对 NLP 各项处理能力综合要求最高的任务之一,要想获得高质量的翻译结果,对于两种语言的词法,句法,语义,上下文处理能力,长距离特征捕获等等更方面都需要考虑进来才行。这是为何看到很多比较工作是在机器翻译上作出的,这里给个背后原因的解释,以避免被质疑任务单一,没有说服力的问题。当然,我预料到那位「因为吃亏少…. 爱挑刺」的同学会这么质问我,没关系,即使你对此提出质疑,我依然能够拿出证据,为什么这么讲,请往后看。
那么在以机器翻译为代表的综合特征抽取能力方面,三个特征抽取器哪个更好些呢?
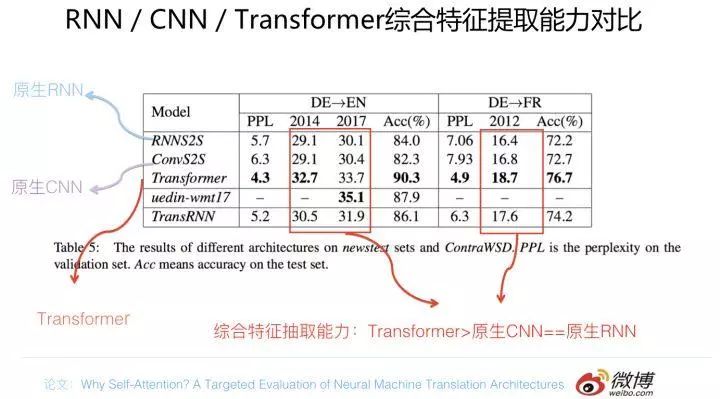
先给出一个机器翻译任务方面的证据,仍然是 why Self attention 论文的结论,对比实验结果数据参考上图。在两个机器翻译任务中,可以看到,翻译质量指标 BLEU 证明了如下结论:Transformer 综合能力要明显强于 RNN 和 CNN(你要知道,技术发展到现在阶段,BLEU 绝对值提升 1 个点是很难的事情),而 RNN 和 CNN 看上去表现基本相当,貌似 CNN 表现略好一些。
你可能觉得一个论文的结论不太能说明问题,那么我再给出一个证据,不过这个证据只对比了 Transformer 和 RNN,没带 CNN 玩,不过关于说服力我相信你不会质疑,实验对比数据如下:
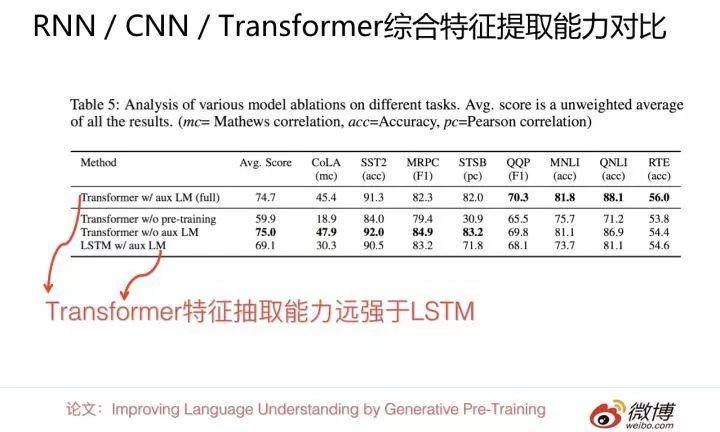
上面是 GPT 论文的实验结论,在 8 个不同的 NLP 任务上,在其它条件相同的情况下,只是把特征抽取器从 Transformer 换成 LSTM,平均下来 8 个任务得分掉了 5 个点以上。这具备足够说服力吗?
其实还有其它机器翻译方面的实验数据,篇幅原因,不一一列举了。如果你是个较真的人,实在还想看,那请看下一节,里面有另外一个例子的数据让来你服气。如果归纳一下的话,现在能得出的结论是这样的:从综合特征抽取能力角度衡量,Transformer 显著强于 RNN 和 CNN,而 RNN 和 CNN 的表现差不太多,如果一定要在这两者之间比较的话,通常 CNN 的表现要稍微好于 RNN 的效果。
当然,需要强调一点,本部分所说的 RNN 和 CNN 指的是原生的 RNN 和 CNN 模型,就是说你可以在经典的结构上增加 attention,堆叠层次等各种改进,但是不包含对本身结构特别大的变动,就是说支持整容,但是不支持变性。这里说的原生版本指的是整容版本,我知道你肯定很关心有没有变性版本的 RNN 和 CNN,我负责任地跟你说,有。你想知道它变性之后是啥样子?等会你就看到了,有它们的照片给你。
并行计算能力及运算效率
关于三个特征抽取器的并行计算能力,其实我们在前文分述三个模型的时候都大致提过,在此仅做个归纳,结论如下:
RNN 在并行计算方面有严重缺陷,这是它本身的序列依赖特性导致的,所谓成也萧何败也萧何,它的这个线形序列依赖性非常符合解决 NLP 任务,这也是为何 RNN 一引入到 NLP 就很快流行起来的原因,但是也正是这个线形序列依赖特性,导致它在并行计算方面要想获得质的飞跃,看起来困难重重,近乎是不太可能完成的任务。
而对于 CNN 和 Transformer 来说,因为它们不存在网络中间状态不同时间步输入的依赖关系,所以可以非常方便及自由地做并行计算改造,这个也好理解。
所以归纳一下的话,可以认为并行计算能力由高到低排序如下:Transformer 和 CNN 差不多,都远远远远强于 RNN。
我们从另外一个角度来看,先抛开并行计算能力的问题,单纯地比较一下三个模型的计算效率。可能大家的直观印象是 Transformer 比较重,比较复杂,计算效率比较低,事实是这样的吗?

上图列出了单层的 Self attention/RNN/CNN 的计算效率,首先要注意:上面列的是 Self attention,不是 Transformer 的 Block,因为 Transformer Block 里其实包含了好几层,而不是单层。我们先说 self attention,等会说 Transformer Block 的计算量。
从上图可以看出,如果是 self attention/CNN/RNN 单层比较计算量的话,三者都包含一个平方项,区别主要是:self attention 的平方项是句子长度,因为每一个单词都需要和任意一个单词发生关系来计算 attention,所以包含一个 n 的平方项。而 RNN 和 CNN 的平方项则是 embedding size。那么既然都包含平方项,怎么比较三个模型单层的计算量呢?首先容易看出 CNN 计算量是大于 RNN 的,那么 self attention 如何与其它两者比较呢。可以这么考虑:如果句子平均长度 n 大于 embedding size,那么意味着 Self attention 的计算量要大于 RNN 和 CNN;而如果反过来,就是说如果 embedding size 大于句子平均长度,那么明显 RNN 和 CNN 的计算量要大于 self attention 操作。而事实上是怎样?我们可以想一想,一般正常的句子长度,平均起来也就几十个单词吧。而当前常用的 embedding size 从 128 到 512 都常见,所以在大多数任务里面其实 self attention 计算效率是要高于 RNN 和 CNN 的。
但是,那位因为吃亏吃的少所以喜欢挑刺的同学会继续质问我:「哥,我想知道的是 Transformer 和 RNN 及 CNN 的计算效率对比,不是 self attention。另外,你能降低你脑袋里发出的水声音量吗?」。嗯,这个质问很合理,我来粗略估算一下,因为 Transformer 包含多层,其中的 skip connection 后的 Add 操作及 LayerNorm 操作不太耗费计算量,我先把它忽略掉,后面的 FFN 操作相对比较耗时,它的时间复杂度应该是 n 乘以 d 的平方。所以如果把 Transformer Block 多层当作一个整体和 RNN 及 CNN 单层对比的话,Transformer Block 计算量肯定是要多于 RNN 和 CNN 的,因为它本身也包含一个 n 乘以 d 的平方,上面列出的 self attention 的时间复杂度就是多出来的计算量。这么说起来,单个 Transformer Block 计算量大于单层 RNN 和 CNN,没毛病。
上面考虑的是三者单层的计算量,可以看出结论是:Transformer Block >CNN >RNN。如果是考虑不同的具体模型,会与模型的网络层深有很大关系,另外还有常见的 attention 操作,所以问题会比较复杂,这里不具体讨论了。
说完非并行情况的三者单层计算量,再说回并行计算的问题。很明显,对于 Transformer 和 CNN 来说,那个句子长度 n 是可以通过并行计算消掉的,而 RNN 因为序列依赖的问题,那个 n 就消不掉,所以很明显,把并行计算能力考虑进来,RNN 消不掉的那个 n 就很要命。这只是理论分析,实际中三者计算效率到底如何呢?我们给出一些三者计算效率对比的实验结论。
论文「Convolutional Sequence to Sequence Learning」比较了 ConvS2S 与 RNN 的计算效率,证明了跟 RNN 相比,CNN 明显速度具有优势,在训练和在线推理方面,CNN 比 RNN 快 9.3 倍到 21 倍。论文「Dissecting Contextual Word Embeddings: Architecture and Representation」提到了 Transformer 和 CNN 训练速度比双向 LSTM 快 3 到 5 倍。论文「The Best of Both Worlds: Combining Recent Advances in Neural Machine Translation」给出了 RNN/CNN/Transformer 速度对比实验,结论是:Transformer Base 速度最快;CNN 速度次之,但是比 Transformer Base 比慢了将近一倍;Transformer Big 速度再次,主要因为它的参数量最大,而吊在车尾最慢的是 RNN 结构。
总而言之,关于三者速度对比方面,目前的主流经验结论基本如上所述:Transformer Base 最快,CNN 次之,再次 Transformer Big,最慢的是 RNN。RNN 比前两者慢了 3 倍到几十倍之间。
综合排名情况
以上介绍内容是从几个不同角度来对 RNN/CNN/Transformer 进行对比,综合这几个方面的实验数据,我自己得出的结论是这样的:单从任务综合效果方面来说,Transformer 明显优于 CNN,CNN 略微优于 RNN。速度方面 Transformer 和 CNN 明显占优,RNN 在这方面劣势非常明显。这两者再综合起来,如果我给的排序结果是 Transformer>CNN>RNN,估计没有什么问题吧?那位吃亏….. 爱挑刺的同学,你说呢?
从速度和效果折衷的角度看,对于工业界实用化应用,我的感觉在特征抽取器选择方面配置 Transformer base 是个较好的选择。
三者的合流:向 Transformer 靠拢
上文提到了,Transformer 的效果相对原生 RNN 和 CNN 来说有比较明显的优势,那么是否意味着我们可以放弃 RNN 和 CNN 了呢?事实倒也并未如此。我们聪明的科研人员想到了一个巧妙的改造方法,我把它叫做「寄居蟹」策略(就是上文说的「变性」的一种带有海洋文明气息的文雅说法)。什么意思呢?我们知道 Transformer Block 其实不是只有一个构件,而是由 multi-head attention/skip connection/Layer Norm/Feed forward network 等几个构件组成的一个小系统,如果我们把 RNN 或者 CNN 塞到 Transformer Block 里会发生什么事情呢?这就是寄居蟹策略的基本思路。
那么怎么把 RNN 和 CNN 塞到 Transformer Block 的肚子里,让它们背上重重的壳,从而能够实现寄居策略呢?
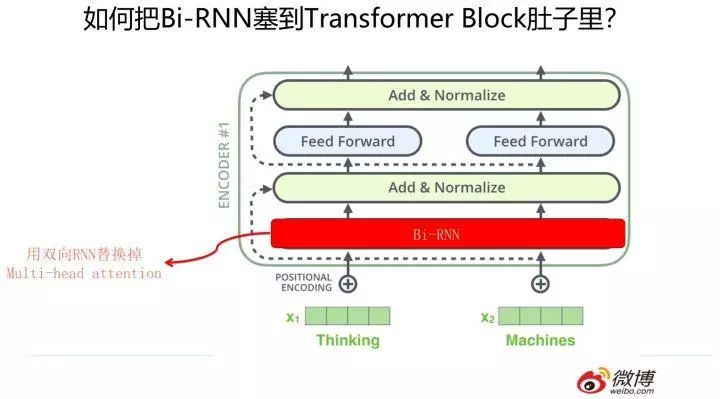
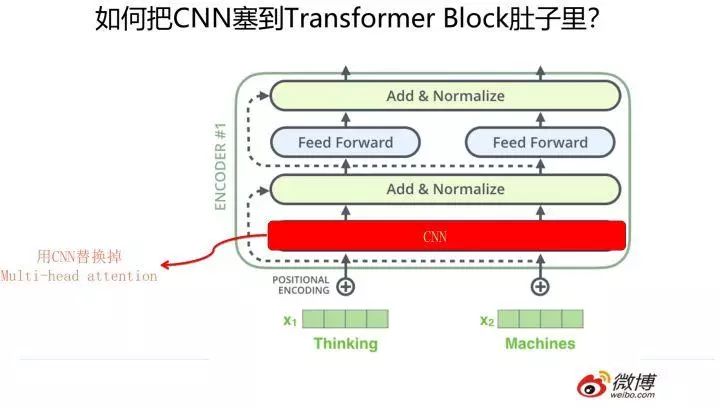
其实很简单,参考上面两张 PPT,简而言之,大的方向就是把 self attention 模块用双向 RNN 或者 CNN 替换掉,Transformer Block 的其它构件依然健在。当然这只是说明一个大方向,具体的策略可能有些差异,但是基本思想八九不离十。
那么如果 RNN 和 CNN 采取这种寄居策略,效果如何呢?他们还爬的动吗?其实这种改造方法有奇效,能够极大提升 RNN 和 CNN 的效果。而且目前来看,RNN 或者 CNN 想要赶上 Transformer 的效果,可能还真只有这个办法了。

我们看看 RNN 寄居到 Transformer 后,效果是如何的。上图展示了对原生 RNN 不断进行整容手术,逐步加入 Transformer 的各个构件后的效果。我们从上面的逐步变身过程可以看到,原生 RNN 的效果在不断稳定提升。但是与土生土长的 Transformer 相比,性能仍然有差距。
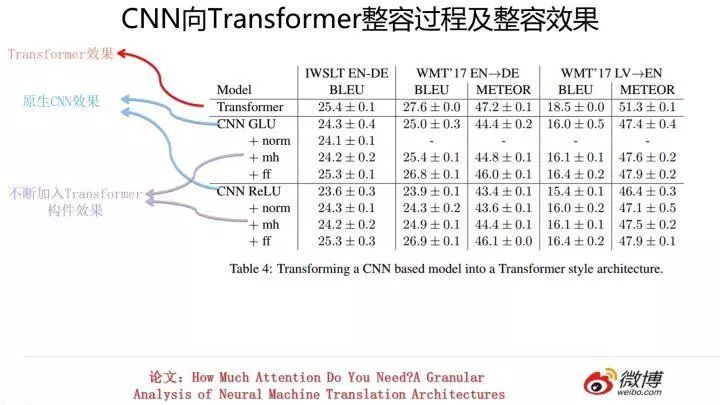
类似的,上图展示了对 CNN 进行不断改造的过程以及其对应效果。同样的,性能也有不同幅度的提升。但是也与土家 Transformer 性能存在一些差距。
这说明什么?我个人意见是:这说明 Transformer 之所以能够效果这么好,不仅仅 multi-head attention 在发生作用,而是几乎所有构件都在共同发挥作用,是一个小小的系统工程。
但是从上面结果看,变性版本 CNN 好像距离 Transformer 真身性能还是比不上,有些数据集合差距甚至还很大,那么是否意味着这条路也未必走的通呢?Lightweight convolution 和 Dynamic convolutions 给人们带来一丝曙光,在论文「Pay Less Attention With LightweightI and Dynamic Convolutions」里提出了上面两种方法,效果方面基本能够和 Transformer 真身相当。那它做了什么能够达成这一点呢?也是寄居策略。就是用 Lightweight convolution 和 Dynamic convolutions 替换掉 Transformer 中的 Multi-head attention 模块,其它构件复用了 Transformer 的东西。和原生 CNN 的最主要区别是采用了 Depth-wise separable CNN 以及 softmax-normalization 等优化的 CNN 模型。
而这又说明了什么呢?我觉得这说明了一点:RNN 和 CNN 的大的出路在于寄生到 Transformer Block 里,这个原则没问题,看起来也是他俩的唯一出路。但是,要想效果足够好,在塞进去的 RNN 和 CNN 上值得花些功夫,需要一些新型的 RNN 和 CNN 模型,以此来配合 Transformer 的其它构件,共同发挥作用。如果走这条路,那么 RNN 和 CNN 翻身的一天也许还会到来。
尽管如此,我觉得 RNN 这条路仍然不好走,为什么呢,你要记得 RNN 并行计算能力差这个天生缺陷,即使把它塞到 Transformer Block 里,别说现在效果还不行,就算哪天真改出了一个效果好的,但是因为它的并行能力,会整体拖慢 Transformer 的运行效率。所以我综合判断 RNN 这条路将来也走不太通。
2019 来自未来的消息:总结
很多年前的小学语文课本上有句话,是这么说的:「张华考上了北京大学;李萍进了中等技术学校;我在百货公司当售货员:我们都有光明的前途」。我们小的时候看到这句话,对此深信不疑,但是走到 2019 的今天,估计已经没有父母愿意跟他们的孩子说这句话了,毕竟欺骗孩子是个挺不好的事情。如果套用这句话来说明 NLP 的三大特征抽取器的前途的话,应该是这样的:「Transformer 考上了北京大学;CNN 进了中等技术学校,希望有一天能够考研考进北京大学;RNN 在百货公司当售货员:我们都有看似光明的前途。」
我们把上文的所有证据都收集起来进行逻辑推理,可以模仿曹雪芹老师,分别给三位 NLP 界佳丽未来命运写一句判词。当然,再次声明,这是我个人判断。
进退维谷的 RNN
为什么说 RNN 进退维谷呢?有几个原因。
首先,如果靠原生的 RNN(包括 LSTM,GRU 以及引入 Attention 以及堆叠层次等各种你能想到的改进方法,可以一起上),目前很多实验已经证明效果比起 Transformer 有较大差距,现在看基本没有迎头赶上的可能,所以原生的 RNN 从效果来讲是处于明显劣势的。
其次,原生的 RNN 还有一个致命的问题:并行计算能力受限制太严重。想要大规模实用化应用?目前看希望渺茫。我们前面说过,决定了 RNN 本身的根本特质是:T 时刻隐层节点对前向输入及中间计算结果的序列依赖,因为它要线形序列收集前面的信息,这是 RNN 之所以是 RNN 的最主要特点。正是它的这个根本特质,使得 RNN 的并行计算能力想要获得根本解决基本陷入了一个两难的境地:要么仍然保持 RNN 序列依赖的根本特性,这样不论怎么改造,因为这个根本还在,所以 RNN 依旧是 RNN,所谓「我就是我,是不一样的烟火」,但是如果这样,那么其并行能力基本无法有力发挥,天花板很低;当然除此外,还有另外一条路可走,就是把这种序列依赖关系打掉,如果这样,那么这种打掉序列依赖关系的模型虽然看上去仍然保留了部分 RNN 整形前的样貌,其实它骨子里已经是另外一个人了,这已经不是你记忆中的 RNN 了。就是说,对 RNN 来说,要么就认命接受慢的事实,躲进小楼成一统,管他春夏与秋冬,仅仅是学术界用来发表论文的一种载体,不考虑大规模实用化的问题。要么就彻底改头换面变成另外一个人,如果真走到这一步,我想问的是:你被别人称为高效版本的 RNN,你自己好意思答应吗?这就是 RNN 面临的两难境地。
再次,假设我们再乐观一点,把对 RNN 的改造方向定位为将 RNN 改造成类似 Transformer 的结构这种思路算进来:无非就是在 Transformer 的 Block 里,把某些部件,当然最可行的是把 Multi-head self attention 部件换成 RNN。我们就算退一步讲,且将这种大幅结构改造的模型也算做是 RNN 模型吧。即使这样,已经把自己整形成长得很像 Transformer 了,RNN 依然面临上述原生 RNN 所面临的同样两个困境:一方面即使这种连变性削骨都上的大幅度整容版本的 RNN,效果虽然有明显提升,但是仍然比不过 Transformer;另外,一旦引入 RNN 构件,同样会触发 Transformer 结构的并行计算能力问题。所以,目前 Transformer 发动机看上去有点带不动 RNN 这个队友。
综合以上几个因素,我们可以看出,RNN 目前处于进退两难的地步,我觉得它被其它模型替换掉只是时间问题,而且好像留给它的时间不多了。当然,这是我个人意见。我说这番话的时候,你是不是又听到了水声?
我看到网上很多人还在推 RNN 说:其实还是 RNN 好用。我觉得这其实是一种错觉。之所以会产生这个错觉,原因来自两个方面:一方面是因为 RNN 发展历史长,所以有大量经过优化的 RNN 框架可用,这对技术选型选择困难症患者来说是个福音,因为你随手选一个知名度还可以的估计效果就不错,包括对一些数据集的前人摸索出的超参数或者调参经验;而 Transformer 因为历史太短,所以各种高效的语言版本的优秀框架还少,选择不多。另外,其实我们对 Transformer 为何有效目前还不是特别清楚,包括相关的各种数据集合上的调参经验公开的也少,所以会觉得调起来比较费劲。随着框架越来越多,以及经验分享越来越充分,这个不再会是问题。这是一方面。另外一方面,很多人反馈对于小数据集 RNN 更好用,这固然跟 Transformer 的参数量比较多有关系,但是也不是没有解决办法,一种方式是把 Block 数目降低,减少参数量;第二种办法是引入 Bert 两阶段训练模型,那么对于小数据集合来说会极大缓解效果问题。所以综合这两方面看,RNN 貌似在某些场合还有优势,但是这些所谓的优势是很脆弱的,这其实反映的是我们对 Transformer 整体经验不足的事实,随着经验越来越丰富,RNN 被 Transformer 取代基本不会有什么疑问。
一希尚存的 CNN
CNN 在 14 年左右在 NLP 界刚出道的时候,貌似跟 RNN 比起来表现并不算太好,算是落后生,但是用发展的眼光看,未来的处境反而看上去比 RNN 的状态还要占优一些。之所以造成这个奇怪现象,最主要的原因有两个:一个是因为 CNN 的天生自带的高并行计算能力,这对于延长它的生命力发挥了很大作用。这就决定了与 Transformer 比起来,它并不存在无法克服的困难,所以仍然有希望;第二,早期的 CNN 做不好 NLP 的一个很大原因是网络深度做不起来,随着不断借鉴图像处理的新型 CNN 模型的构造经验,以及一些深度网络的优化 trick,CNN 在 NLP 领域里的深度逐步能做起来了。而既然深度能做起来,那么本来 CNN 做 NLP 天然的一个缺陷:无法有效捕获长距离特征的问题,就得到了极大缓解。目前看可以靠堆深度或者结合 dilated CNN 来一定程度上解决这个问题,虽然还不够好,但是仍然是那句话,希望还在。
但是,上面所说只是从道理分析角度来讲 CNN 的希望所在,话分两头,我们说回来,目前也有很多实验证明了原生的 CNN 在很多方面仍然是比不过 Transformer 的,典型的还是长距离特征捕获能力方面,原生的 CNN 版本模型仍然极为显著地弱于 RNN 和 Transformer,而这点在 NLP 界算是比较严重的缺陷。好,你可以说:那我们把 CNN 引到 Transformer 结构里,比如代替掉 Self attention,这样和 Transformer 还有一战吧?嗯,是的,目前看貌似只有这条路是能走的通的,引入 depth separate CNN 可以达到和 Transformer 接近的效果。但是,我想问的是:你确认长成这样的 CNN,就是把 CNN 塞到 Transformer Block 的肚子里,你确认它的亲朋好友还能认出它吗?
当然,我之所以写 CNN 一希尚存,是因为我觉得把 CNN 塞到 Transformer 肚子里这种方案,对于篇章级别的 NLP 任务来说,跟采取 self attention 作为发动机的 Transformer 方案对比起来,是具有极大优势的领域,也是适合它的战场,后面我估计会出现一些这方面的论文。为什么这么讲?原因下面会说。
稳操胜券的 transformer
我们在分析未来 NLP 的三大特征抽取器哪个会胜出,我认为,起码根据目前的信息来看,其实 Transformer 在很多战场已经赢了,在这些场地,它未来还会继续赢。为什么呢?上面不是说了吗,原生的 RNN 和 CNN,总有一些方面显著弱于 Transformer(并行计算能力或者效果,或者两者同时都比 Transformer 弱)。那么他们未来的希望,目前大家都寄托在把 RNN 和 CNN 寄生在 Transformer Block 里。RNN 不用说了,上面说过它的进退维艰的现状。单说 CNN 吧,还是上一部分的那句话,我想问的是:你确认长成这样的 CNN,就是把 CNN 塞到 Transformer Block 的肚子里,你确认它的亲朋还能认出它吗?
目前能够和 Transformer 一战的 CNN 模型,基本都已经长成 Transformer 的模样了。而这又说明了什么呢?难道这是 CNN 要能战胜 Transformer 的迹象吗?这是一道留给您的思考题和辩论题。当然,我不参加辩论。
Transformer 作为一个新模型,并不是完美无缺的。它也有明显的缺点:首先,对于长输入的任务,典型的比如篇章级别的任务(例如文本摘要),因为任务的输入太长,Transformer 会有巨大的计算复杂度,导致速度会急剧变慢。所以估计短期内这些领地还能是 RNN 或者长成 Transformer 模样的 CNN 的天下(其实目前他俩这块做得也不好),也是目前看两者的希望所在,尤其是 CNN 模型,希望更大一些。但是是否 Transformer 针对长输入就束手无策,没有解决办法呢?我觉得其实并不是,比如拍脑袋一想,就能想到一些方法,虽然看上去有点丑陋。比如可以把长输入切断分成 K 份,强制把长输入切短,再套上 Transformer 作为特征抽取器,高层可以用 RNN 或者另外一层 Transformer 来接力,形成 Transformer 的层级结构,这样可以把 n 平方的计算量极大减少。当然,这个方案不优雅,这个我承认。但是我提示你一下:这个方向是个值得投入精力的好方向,你留意一下我这句话,也许有意想不到的收获。(注:上面这段话是我之前早已写好的,结果今天(1 月 12 日)看见媒体号在炒作:「Transforme-XL,速度提升 1800 倍」云云。看了新闻,我找来 Transformer-XL 论文看了一下,发现它解决的就是输入特别长的问题,方法呢其实大思路和上面说的内容差不太多。说这么多的意思是:我并不想删除上面内容,为避免发出来后,那位「爱挑刺」同学说我拷贝别人思路没引用。我决定还是不改上面的说法,因为这个点子实在是太容易想到的点子,我相信你也能想到。)除了这个缺点,Transformer 整体结构确实显得复杂了一些,如何更深刻认识它的作用机理,然后进一步简化它,这也是一个好的探索方向,这句话也请留意。还有,上面在做语义特征抽取能力比较时,结论是对于距离远与 13 的长距离特征,Transformer 性能弱于 RNN,说实话,这点是比较出乎我意料的,因为 Transformer 通过 Self attention 使得远距离特征直接发生关系,按理说距离不应该成为它的问题,但是效果竟然不如 RNN,这背后的原因是什么呢?这也是很有价值的一个探索点。
我预感到我可能又讲多了,能看到最后不容易,上面几段话算是送给有耐心的同学的礼物,其它不多讲了,就此别过,请忽略你听到的哗哗的水声。





