论文浅尝 | 将结构预测作为增广自然语言间的翻译任务
笔记整理 | 叶宏彬,浙江大学计算机博士生

论文地址:https://openreview.net/pdf?id=US-TP-xnXI
摘要:我们提出了一个新的框架,即增强自然语言之间的翻译(Translation-between-Augmented Natural Languages,TANL)来解决许多结构化预测语言任务,包括联合实体和关系提取、嵌套命名实体识别、关系分类、语义角色标注、事件提取、共指消解和对话状态跟踪。我们没有训练特定于任务的区分分类器来解决这个问题,而是将其框架化为一个增强自然语言之间的翻译任务,从中可以很容易地提取与任务相关的信息。我们的方法可以在所有任务上匹配或优于任务特定模型,特别是在联合实体和关系提取(CoNLL04、ADE、NYT和ACE2005数据集)、关系分类(FewRel和TACRED)和语义角色标记(CoNLL-2005和CoNLL2012)方面取得了最新的成果。我们在为所有任务使用相同的体系结构和超参数,甚至训练单个模型同时解决所有任务(多任务学习)的情况下实现了这一点。最后,我们表明,由于更好地使用了标签语义,我们的框架还可以在低资源情况下显著提高性能。
动机
结构化预测是指输出空间由结构化对象组成的推理任务,例如表示实体及其关系的图。在自然语言处理中,结构化预测涉及到实体和关系提取、语义角色标注和共指消解等广泛的问题。例如,如图1,我们展示了两个结构预测任务(联合实体和关系提取以及共指消解任务):

图1 结构预测任务示例
大多数方法通过在诸如BERT之类的预训练变换编码器的基础上,对各种类型的关系或属性使用特定于任务的鉴别器来处理结构化预测。然而,这有两个局限性。首先,有区别的分类器不能很容易地利用预先训练的模型可能已经具有的关于任务标签的语义的潜在知识。例如,知道一个人可以写一本书将大大简化学习作者关系在上述例子。然而,判别模型通常是在不知道标签语义的情况下训练的(它们的目标是类号),从而防止了这种正迁移。第二,由于判别模型的结构适合于特定的任务,因此很难训练单个模型来解决多个任务,或者在不改变判别器的特定于任务的组件的情况下从一个任务微调模型到另一个任务(转移学习)。因此,作者想解决的主要问题是:能否设计一个框架来解决不同的问题。
方法
在本文中,作者提出了一个 text-to-text的模型来解决这个问题,通过将其框架化为增强自然语言(TANL)之间的翻译任务。图2显示了在三个不同的结构化预测任务的情况下,如何在的框架内处理前面的示例。增广语言的设计使得在输入中对结构化信息(如相关实体)进行编码,并将输出文本解码为结构化信息变得容易。实验表明,开箱即用的Transformer模型可以很容易地学习这种增强的语言翻译任务。事实上,作者成功将框架应用于广泛的结构化预测问题,在许多数据集上获得了最新的结果。在所有任务上都使用相同的体系结构和超参数,任务之间的唯一区别是增强的自然语言格式。这与以前使用特定任务区分模型的方法不同。输入和输出格式的选择是至关重要的:通过使用尽可能接近自然语言的格式的注释。嵌套实体和任意数量的关系也可以巧妙地处理,作者实现了一个对齐算法,将从输出句子中提取的结构信息与输入句子中相应的标记进行鲁棒匹配。
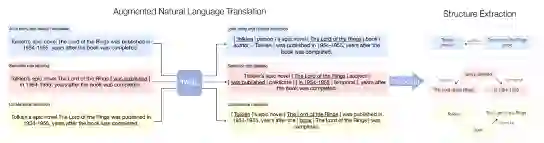
图2 增强自然语言框架
以联合实体和关系抽取任务为例,如图3。给定一个句子,这个任务的目的是提取一组实体和一组实体对之间的关系。每个预测的实体和关系必须分配给一个实体或关系类型。为此任务设计的增强自然语言所需的输出复制了输入语句,并使用可解码为结构化对象的模式对其进行扩充,由一个实体和一些可能的关系组成的每个组都由特殊标记[]括起来。一系列分隔的标记以“X=Y”格式描述实体类型和关系列表,其中X是关系类型,Y是另一个实体(关系的尾部)。此外文中也列出了命名实体识别、关系分类、语义角色标注、共指消解、事件提取、对话状态跟踪这些任务各自的表示形式。

图3 联合实体和关系抽取任务
面对嵌套实体和多重关系这一特殊情况,如图4。嵌套模式允许我们表示实体的层次结构。在ADE数据集中的以下示例中,实体“lithium toxicity”属于disease类型,并且具有drug类型的子实体“lithium”。“lithium toxicity”实体涉及多种关系:一种是与“acyclovir”实体的effect类型,另一种是与“lithium”实体的effect类型。一般来说,输出中的关系可以以任何顺序出现。

图4 嵌套实体和多重关系
解码结构化对象过程中。一旦模型生成了一个扩充自然语言格式的输出句子,就对该句子进行解码以获得预测的结构化对象,如下几点:
1.移除所有特殊标记并提取实体类型和关系,以生成干净的输出。如果生成的句子的一部分格式无效,则该部分将被丢弃。
2.使用基于动态规划(DP)的Needleman-Wunsch对齐算法在令牌级别匹配输入语句和清洁的输出语句。然后,我们使用这种对齐来识别与原始输入语句中的实体相对应的标记。该过程提高了模型对潜在不完美生成的鲁棒性。
3.对于输出中提出的每个关系,搜索与预测尾部实体完全匹配的最近实体。如果这样的实体不存在,则丢弃关系。
4.丢弃其预测类型不属于依赖于数据集的类型列表的实体或关系。
实验
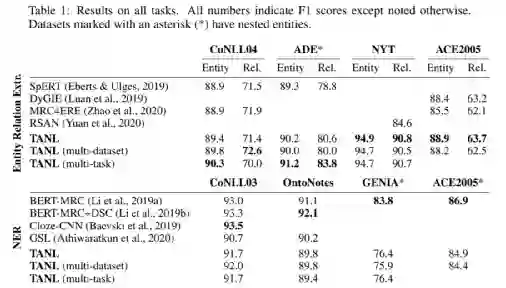
总结与讨论
1.本文的统一文本到文本的结构化预测方法可以在一个简单的框架内处理所有需要考虑的任务,并在低资源环境下提供额外的好处。与文献中常见的传统模型不同,TANL是生成性的,因为它在增强的自然语言中从输入转换为输出。这些扩充语言是灵活的,可以被设计来处理各种各样的任务。这给融入知识图谱工作带来了启发。
2.生成模型,特别是序列到序列模型,已经成功地应用于许多自然语言处理问题,如机器翻译、文本摘要等。这些任务涉及从一种自然语言输入到另一种自然语言输出的映射。然而,序列建模在结构化预测中的应用却很少受到重视。这可能是因为人们认为,生成方法过于不受约束,而且生成与结构化对象相对应的精确输出格式不是一种可靠的方法,或者它可能会在区分性模型方面增加不必要的复杂性。作者证明这是完全相反的。生成方法可以很容易地处理不同的任务,即在同一时间,可以输出适合每个任务的特定结构,并且格式错误的情况也很少,给生成任务带来更多的拓展空间。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


