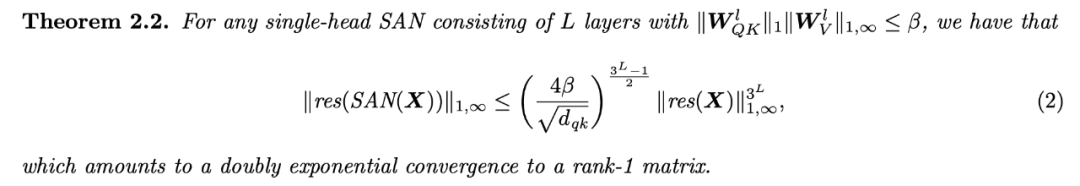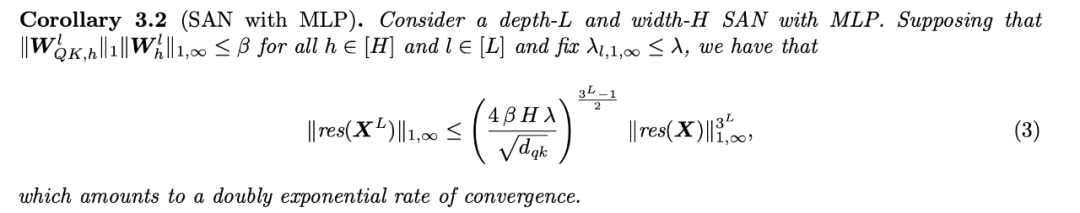基于注意力的架构为什么那么有效?
近期谷歌等一项研究认为注意力并没有那么有用,它会导致秩崩溃,而网络中的另两个组件则发挥了重要作用:
「跳过连接」有效缓解秩崩溃,「多层感
知器」能够降低收敛速度。
此外,该研究还提出了一种理解自注意力网络的新方式——路径分解。
基于注意力的架构在机器学习领域已经非常普遍,但人们对其有效性原因的理解仍然有限。
最近,来自谷歌和瑞士洛桑联邦理工学院(EPFL)的研究者提出了一种理解自注意力网络的新方式:将网络输出分解为一组较小的项,每个项包括一系列注意力头的跨层操作。基于该分解,研究者证明自注意力具备强大的「token uniformity」归纳偏置。
也就是说,如果没有跳过连接(skip connection)或多层感知器(MLP),其输出将双指数级收敛至秩 1 矩阵。另外,跳过连接和 MLP 还可以阻止输出的衰退。该研究在不同 Transformer 变体上的实验证实了这一收敛现象。
![]()
注意力机制最初旨在更好地学习长程序列知识,在 Transformer 网络中得到了有效使用。之后,基于注意力的架构逐渐渗透到多个机器学习应用领域,如自然语言处理、语音识别和计算机视觉。因此,开发一些工具,来理解 Transformer 和注意力的内在工作机制是非常重要的,这既可以帮助理解现有的模型,又能为未来设计更高效的模型做准备。
该研究对此类网络的操作和归纳偏置提供了新的见解。研究者惊讶地发现
纯自注意力网络(SAN)——即不具备跳过连接(skip connection)和多层感知器(MLP)的 Transformer,会损失一部分表达能力
,其损失程度与网络深度成双指数级关联。具体而言,研究者证明网络输出以三次方收敛速度收敛至秩 1 矩阵。
![]()
研究者利用随机矩阵的特性部分地推导出收敛界限,但其结果超出了想象。利用特殊堆叠自注意力模块的级联效应,研究者发现这类网络的收敛速度比标准理论所描述的快指数级。
此外,尽管之前有研究考虑了单个自注意力矩阵的秩,但该研究认为其结果首次说明了整个网络收敛至秩 1 矩阵的条件。
注意力机制不给力,Transformer 凭什么那么有效呢?
问题来了:如果 Transformer 的自注意力机制不给力,又是什么赋予了它优秀的能力呢?
该研究分析了三个重要组件:跳过连接、MLP 和层归一化,结果表明,跳过连接能够有效地缓解秩崩溃(rank collapse),MLP 则通过增加利普希茨常数来降低收敛速度。
![]()
研究者通过证明在类 Transformer 的 SAN 架构变体上的收敛行为的上下界,描述了这些反作用力。研究结果揭示了跳过连接此前不为人知的重要作用,它的作用可不只是促进优化和梯度流动。
![]()
在分析过程中,研究者提出了一种
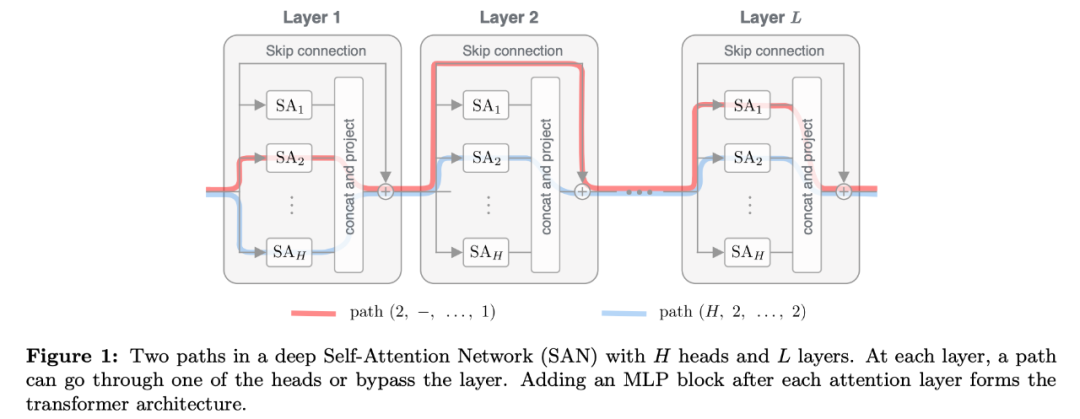
新的路径分解
方式来研究自注意力网络。他们将 SAN 分解为弱耦合路径的线性组合,每一条「路径」对应一个深度单头 SAN。
![]()
直观来看,我们可以将原始网络中每一层的自注意力头看作不同的 gateway,一条路径遵循一系列 gateway 选择,每层一个 gateway(参见图 1)。结合秩崩溃分析,该研究结果表明
具备跳过连接的深度 SAN 类似于多个弱相依浅层网络的集成
。
![]()
系统研究了 Transformer 的构造块,揭示自注意力与其反作用力(跳过连接和 MLP)之间的对抗影响。这揭示了跳过连接在促进优化之外的重要作用。
提出一种通过路径分解来分析 SAN 的新方法,发现 SAN 是多个浅层网络的集成。
在多个常见 Transformer 架构上进行实验,从而验证其理论。
该研究首次在多个知名 Transformer 架构中测试了秩崩溃现象,用图示的方式表示一些 Transformer 变体的归纳偏置,并测试了路径有效性。
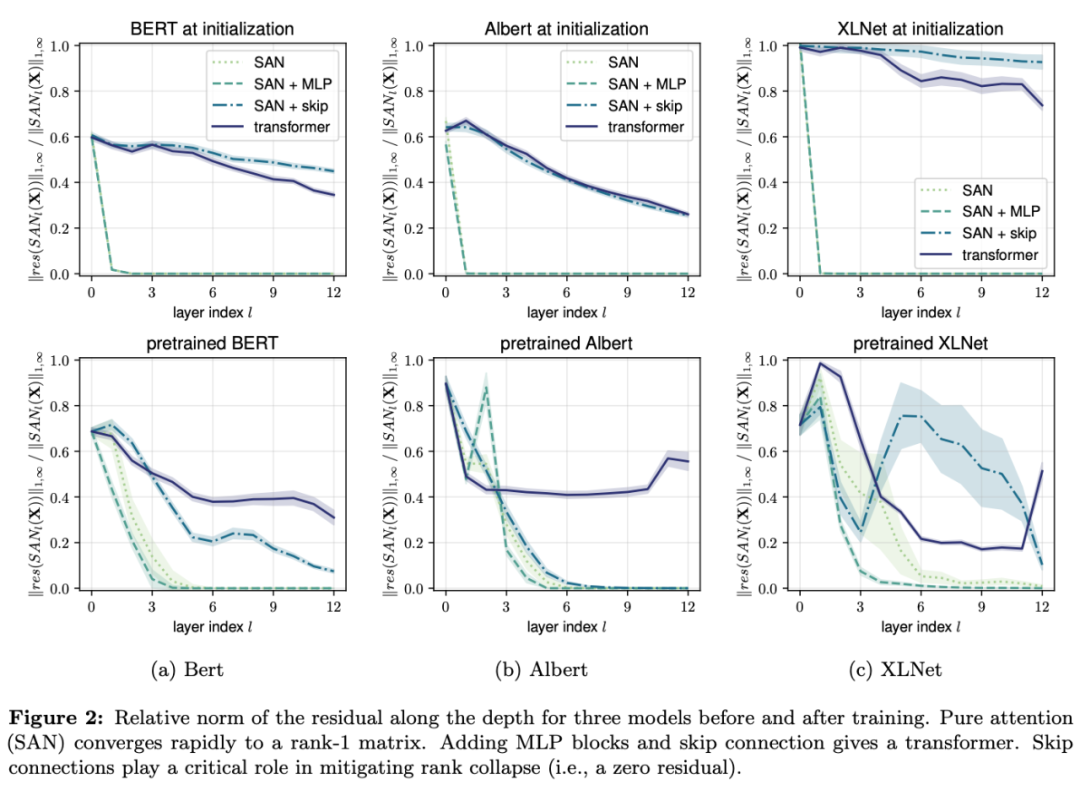
为了验证其理论预测,研究者检查了三个知名 Transformer 架构的残差,分别是 BERT、Albert 和 XLNet。下图 2 绘制了网络训练前后每个层输出的相对残差:
![]()
![]()
该实验确认,移除跳过连接后,所有网络均出现快速秩崩溃。尽管 MLP 在缓解收敛方面似乎没太大帮助,但研究者注意到这一观察未必准确反映 Transformer 的运作原理:移除跳过连接会导致 MLP 输入出现极大的分布偏移。研究者希望网络重新训练会降低收敛速度。
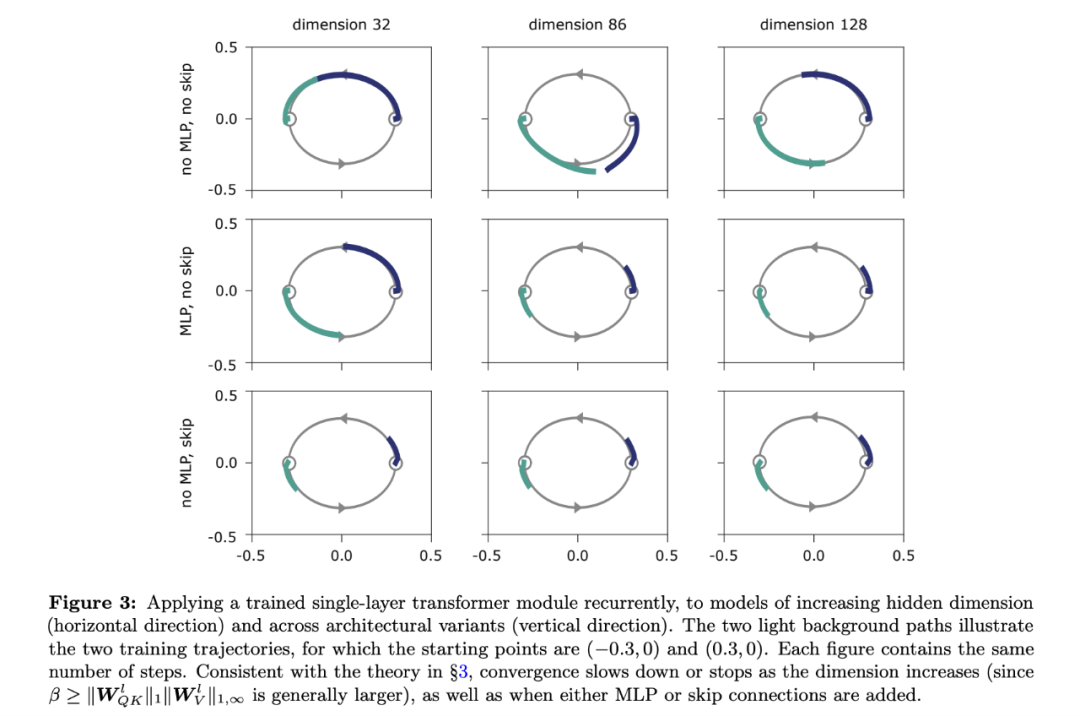
为了实验验证 Transformer 架构不同组件的归纳偏置,研究者探索了循环使用单层 Transformer 来预测简单 2D 环状序列的行为。研究者训练网络直到它能够以接近 0 的损失记住环状轨迹上的下一步。下图 3 展示了模型在推断时预测的轨迹:
![]()
SAN 可被视作多个不同长度(从 0 到 L)路径的集成,每一个路径包含不同的自注意力头序列。该研究对具备跳过连接的 SAN 进行的分析表明,路径有效性会随着路径长度的增加而降低,即使涉及的非线性运算数量增加了。为了验证这一假设,研究者将不同长度的路径分隔开,并评估其预测能力。
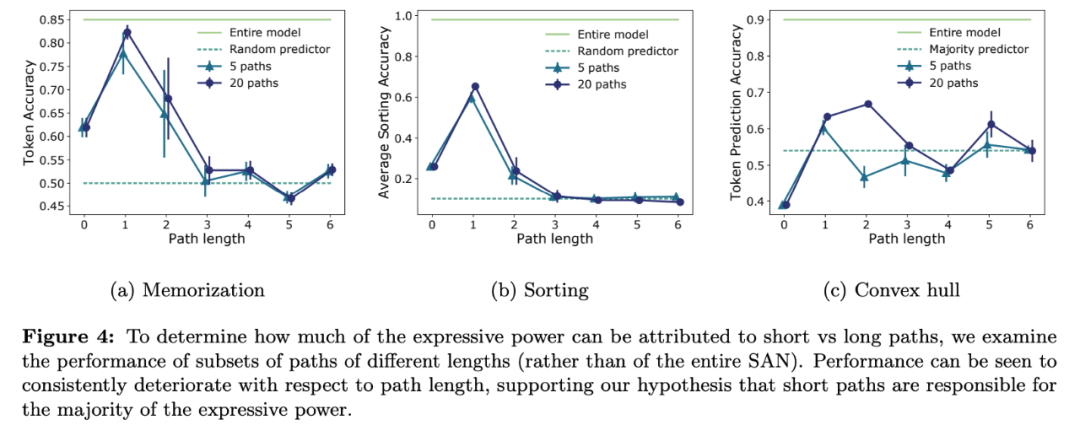
下图 4 展示了在序列记忆(Sequence memorization)、学习分类(Learning to sort)和凸包预测(Convex hull prediction)三项任务中的性能。研究者测试了不同的子集,并报告了五次重复试验的均值和标准差。至于推断,研究者还绘制了朴素分类器和整个训练模型(路径分解前)的准确率。
![]()
从上图中可以看到,短路径具备较强的预测能力,长度为 1 的路径在记忆、分类和凸包任务中分别获得了超过 0.8、0.6、0.65 的准确率。而较长路径的输出准确率并不比随机猜测好多少。由于凸包任务中存在类别不均衡现象,研究者使用多数类预测器来获取随机基线。尽管凸包任务中长短路径的准确率差异没那么大,但研究者观察到长路径的方差明显更大,这表明其比随机猜测好不了太多。长度为 0 的路径方差很小,但未获得和任务相关的有用信息(很可能是因为它们没有穷尽全局信息)。
2021 AI 100 Connect Webinar:AI+大消费专场
3月18日,科百科技产品方案部总监孙祥明、云拿科技智慧零售产品负责人李宛书将分别以「信物融合,让天下没有难种的作物」、「智慧零售:以 AI+IoT 驱动零售门店数字化转型 」为主题带来智慧农业和智慧零售行业的一手解读。
扫码添加机器之心小助手,加入直播群。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com