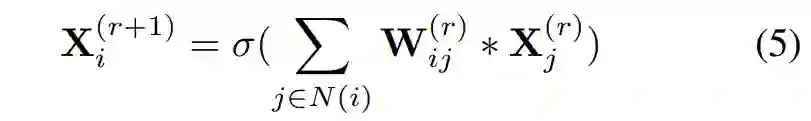作者:尤佳轩、Jure Leskovec、何恺明、Saining Xie
机器之心编译
参与:小舟、杜伟
神经网络的图结构和预测性能之间有怎样的关系?
近日,斯坦福尤佳轩、Jure Leskovec 联合 FAIR 何恺明、Saining Xie 等人的论文提出了一种神经网络的新型的图表示法。
该表示法有助于对神经网络的架构和预测性能有更深层的理解。
这篇论文已经被 ICML 2020 收录。
神经网络通常用神经元之间的连接图来表示。尽管神经网络被广泛使用,但目前对神经网络图结构与其预测性能之间关系的理解却非常少。
近日,在斯坦福联合 FAIR 提出的一项研究中,研究者
系统地探讨了神经网络图结构对其预测性能的影响,并提出了一种新的基于图的神经网络表示,他们称之为 relational 图
。其中,神经网络计算层按照图结构与信息交换的轮数(rounds)对应。
论文一作为斯坦福大学计算机科学系博士三年级学生尤佳轩(Jiaxuan You),其导师为斯坦福大学计算机科学副教授、Pinterest 首席科学家 Jure Leskovec。
![]()
论文地址:https://arxiv.org/pdf/2007.06559.pdf
relational 图的最佳区域(sweet spot)在于能够大大提升神经网络的预测性能;
神经网络的预测性近似为 relational 图的聚类系数和平均路径长度的平滑函数;
该研究的结果在许多不同的任务和数据集上是一致的;
relational 图的最佳区域能够得到高效地确定;
性能顶级的神经网络具有与真实生物神经网络相似的图结构;
为神经网络的架构设计与理解提供了一种新方向。
为了探索神经网络的图结构,研究者首先提出了 relational 图表示法及其实例化的概念,并演示了该表示方法如何在一个统一的框架下发现各种神经网络的架构。在深度学习环境中用图作为语言是一个不错的选择,这将为后续的研究奠定基础。
研究者从图的角度重新审视神经网络的定义,他们定义了图 G = (V, ε),其中节点集 V = {v_1, ..., v_n},边集 E ⊆ {(v_i , v_j )|v_i , v_j ∈ V}。该研究假设每个节点 v 都有一个节点特征标量(或向量)x_v。
当图 G 与神经元之间的消息交换联系起来时,它就被称为 relational 图。具体而言,消息交换通过一个消息函数和一个聚合函数来定义,其中消息函数的输入是节点特征,输出消息;聚合函数的输入是消息集,输出是更新后的节点特征。
在每轮消息交换中,每个节点向它的相邻点传递消息并聚合从所有相邻点传入的消息。每条消息在边上通过消息函数 f(·)传递,然后通过聚合函数 AGG(·)在每个节点聚合。
假设进行 R 轮消息交换,那么节点 v 的第 r 轮消息交换可表示为:
![]()
需要注意的一点是,这种定义消息交换的方式适用于任何图。为了简单起见,该论文中仅考虑无向图。公式 1 提供了消息交换的通用定义。
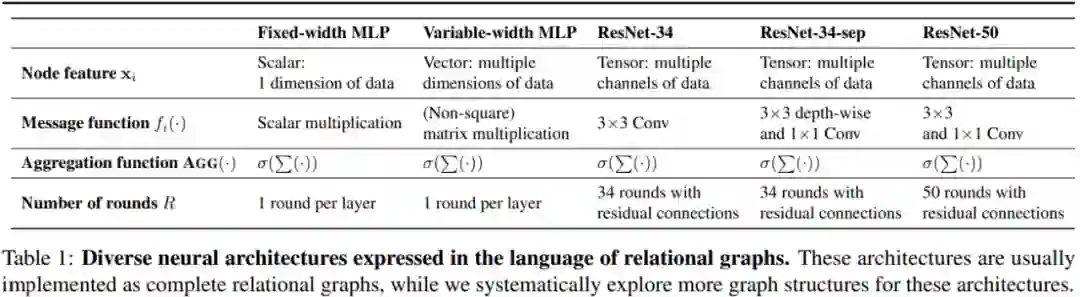
下表 1 则给出了该通用消息交换定义在几种神经架构中的实例化结果:
![]()
表 1:用 relational 图语言表达的几种神经架构。
多层感知器(MLP)由多层计算单元(神经元)组成,其中每个神经元对标量输入(scalar input)和输出执行加权求和,然后进行一些非线性处理。
假设 MLP 的第 r 层将 X^(r)作为输入,将 X^(r+1)作为输出,那么神经元的计算方式如下:
![]()
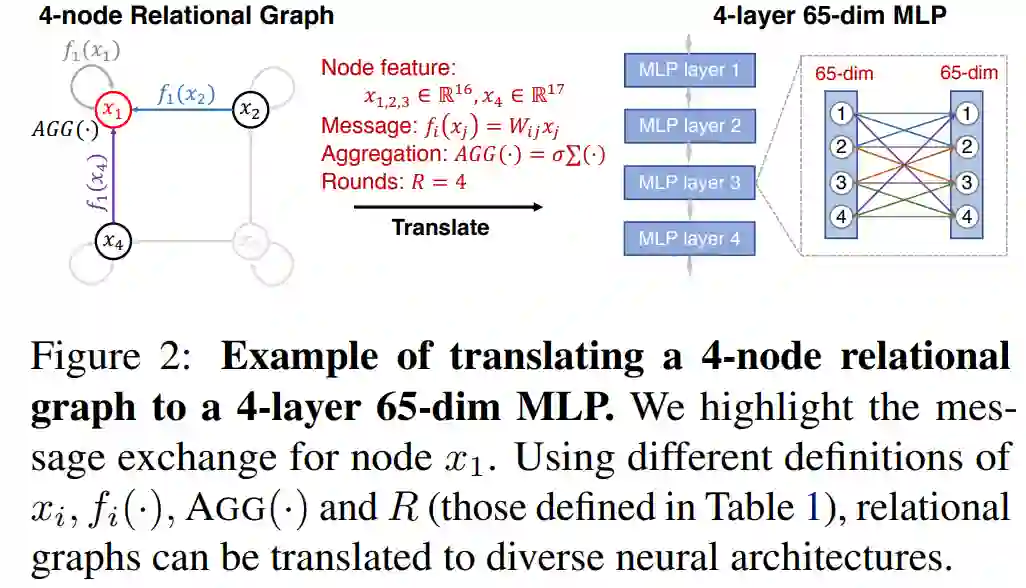
下图给出了将 4 节点 relational 图转化为 4 层 65 维 MLP 的实例:
![]()
此外,考虑一种特殊情况,所有层的输入和输出 x^(r), (1 ≤ r ≤ R)都有相同的特征维数。在这种情况下,一个固定宽度的全连接 MLP 层能用一张完全 relational 图表达,其中每个节点 x_i 和其他所有节点 {x_1,...,x_n} 都相连。
另外,固定宽度的全连接 MLP 层有特殊的消息交换定义,其中消息函数是
![]() ,聚合函数是
,聚合函数是
![]() 。
。
这些讨论表明,
固定宽度的 MLP 可以被视为具有特殊消息交换函数的完全 relational 图
。因此,固定宽度的 MLP 是一般模型族中的一种特例,它对应的消息函数、聚合函数以及 relation 图结构都有所不同。
基于此,研究者能够使用完全 relational 图以及任何通用 relational 图 G 来泛化固定宽度的 MLP。基于公式 1 中消息交换的通用定义,得出以下公式 3:
![]()
上文公式 3 中的图视点奠定了将固定宽度的 MLP 表示为 relational 图的基础。接下来,研究者探讨了如何进一步将 relational 图泛化为通用神经网络。
通用神经网络有一个要考虑的关键点是整个网络中层的宽度不一。所以,为了用可变的层宽表示神经网络,研究者用 CONCAT 方法将节点特征从标量 x^(r)_i 扩展为向量 X^(r)_i,即
![]() ,并且将消息函数 f_i(·) 从标量乘法泛化至矩阵乘法。
研究者进一步将 relational 图的应用泛化至卷积神经网络上,其中输入变成了图像张量 X^(r)。同样用到了 CONCAT 方法,并使用卷积运算符泛化了消息交换定义:
,并且将消息函数 f_i(·) 从标量乘法泛化至矩阵乘法。
研究者进一步将 relational 图的应用泛化至卷积神经网络上,其中输入变成了图像张量 X^(r)。同样用到了 CONCAT 方法,并使用卷积运算符泛化了消息交换定义:
![]()
其中 * 代表卷积运算符,W^(r)_ij 表示卷积滤波器。
最后,研究者又将 relational 图泛化至设计更复杂的现代神经架构。比如,为了表示 ResNet,他们保持层之间的残差连接不变。
在实验部分,研究者首先探讨了 CIFAR-10 数据集上 MLP 的图结构,然后又进一步研究了 ImageNet 数据集上更大更复杂的分类任务。对于所有的架构,该研究均使用上表 1 中概述的相应定义将每个采样的 relational 图实例化。
具体而言,对于 CIFAR-10 MLP 实验,研究者研究了 3942 张 64 节点的采样 relational 图。而对于 ImageNet 实验,由于计算成本高,他们从 3942 张图中均匀地采集子样本 52 张图。
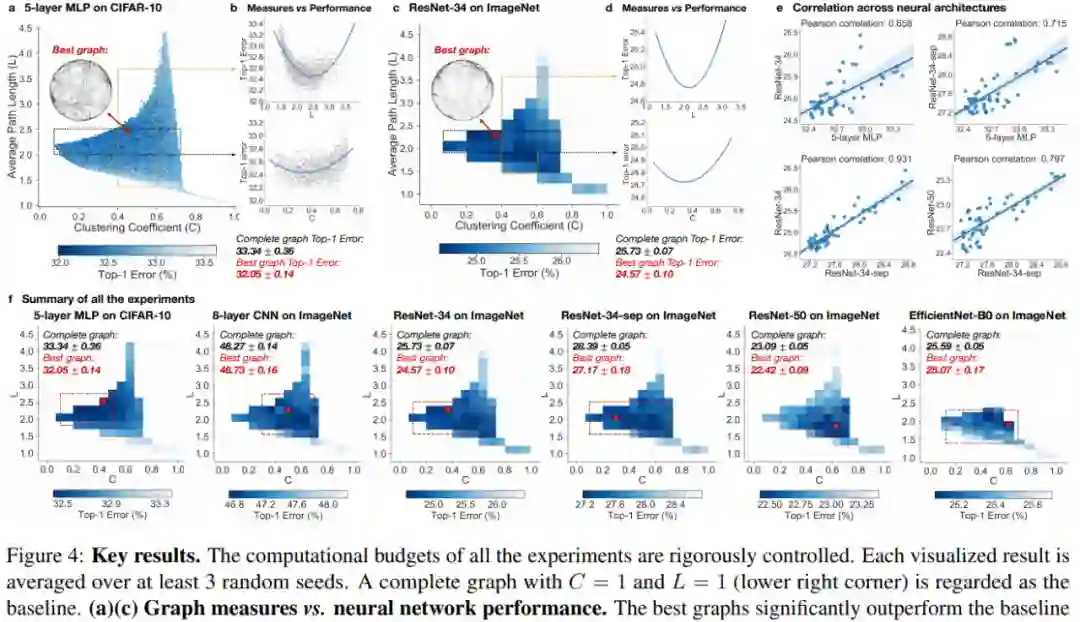
对于不同任务和架构上所有采样的 relational 图,研究者收集 top-1 误差,记录每个样本图的图指标(graph measure),并将这些结果显示为图指标与预测性能的热图,如下图 4 所示:
![]()
主要实验结果。严格控制所有实验的计算预算,每个可视化结果平均至少 3 个随机种子。右下角的 C=1,L=1 的完全图作为基线。图中红色矩形突出显示了最佳区域。
值得注意的是,研究者发现性能最佳的图倾向于在 C 和 L(图 4(f)中的红色矩形区域)定义的空间中聚类出最佳区域。具体而言,研究者按照以下步骤确定最佳区域:
对图 4(a)中的 3942 张图进行下采样并将其聚合为 52 个 bin 的粗粒度区域,其中每个 bin 记录对应区域图的性能;
找出平均性能最佳的 bin(图 4(f)中的红叉);
对每个 bin 做单尾 t - 检验,与性能最佳的 bin 进行对比,并将没有比性能最佳的 bin 差很多(p 值 0.05 为阈值)的 bin 记录下来。覆盖这些 bin 的面积最小的矩形被视为最佳区域。
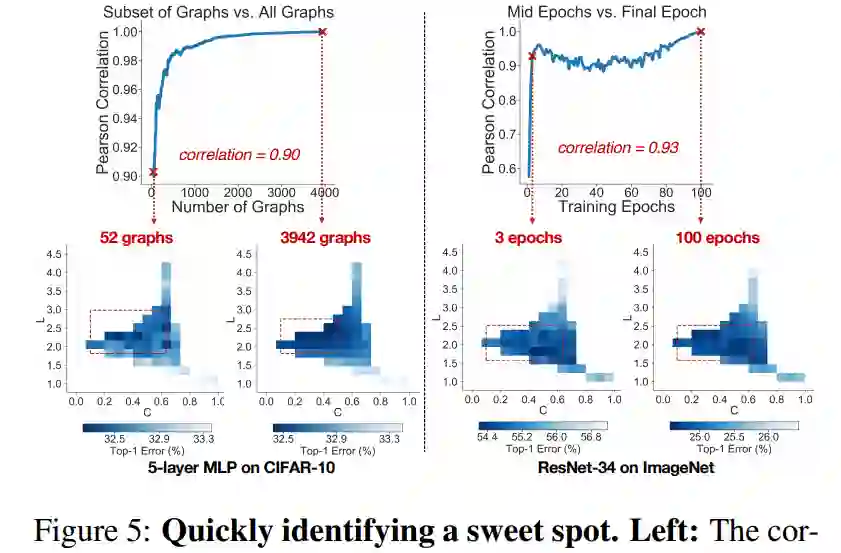
在下图 5(左)中,研究者计算了使用全部 3942 张图和使用子样本 52 张图计算的 52bin 值之间的相关性,图 5(右)计算了子样本 52 张 relational 图中,部分训练模型的验证 top-1 误差和完全训练 100 epoch 模型的验证 top-1 误差之间的相关性:
![]()
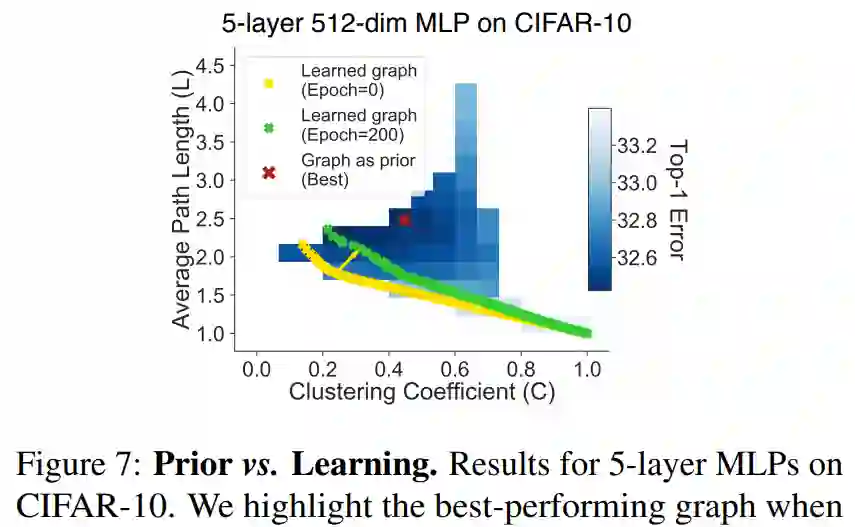
目前,研究者将 relational 图表示用作结构先验(structural prior),也就是说,在整个训练过程中,他们将图结构硬连接(hard-wire)在神经网络上。
![]()
最后,该研究表明,网络科学、神经科学等其他理科学科中完善的图技术和方法有助于理解和设计深度神经网络。研究者认为,在未来需要解决更复杂场景任务的研究中,这可能是一种卓有成效的发展方向。
Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 模型。SageMaker完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。
现在,企业开发者可以免费领取1000元服务抵扣券,轻松上手Amazon SageMaker,快速体验5个人工智能应用实例。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

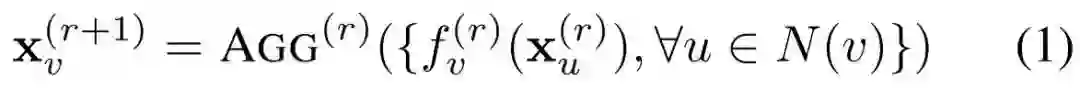
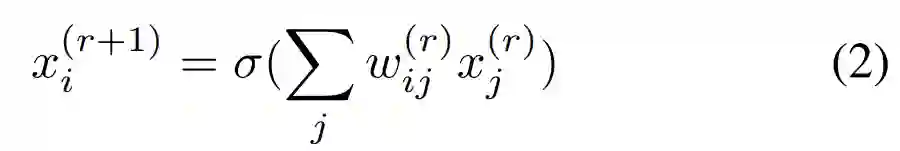
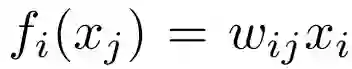 ,聚合函数是
,聚合函数是
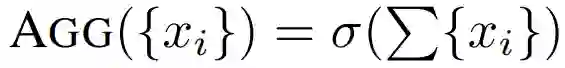 。
。
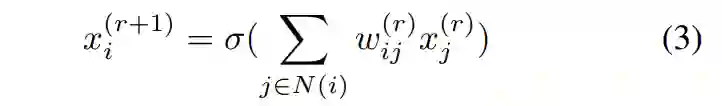
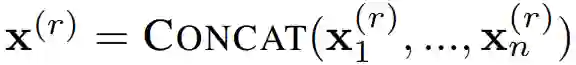 ,并且将消息函数 f_i(·) 从标量乘法泛化至矩阵乘法。
,并且将消息函数 f_i(·) 从标量乘法泛化至矩阵乘法。