CVPR 2019 | 夺取6项冠军的旷视如何筑起算法壁垒
机器之心原创
作者:Tony
走进今年 CVPR 的工业展区,映入眼帘的是熟悉的 MEGVII 字眼和以蓝色为主基调的展位,蓝白相间的 booth roof 甚是亮眼,这多少让记者有些惊讶。旷视,这家来自中国的计算机视觉独角兽公司,竟然「霸占」了全世界顶尖学术会议的 C 位。
CVPR,全称 IEEE 国际计算机视觉与模式识别会议,在计算机视觉领域是和 ECCV、ICCV 并称的三大顶尖会议。今年的 CVPR 于当地时间 6 月 16 日在美国加州长滩开幕,前后共 5 天,吸引了超过 9200 多名参会者、284 家赞助商和 104 家展商。论文方面,来自全球的 14,104 位作者提交了 5000 多篇论文。
不远千里来到长滩会议中心的旷视研究员,在今年的 CVPR 上满载而归:拿下 6 个挑战赛世界冠军,包括自动驾驶、细粒度识别等等,数量位列今年国内参会公司之首;首次在 CVPR 举办研讨会和挑战赛,吸引了超过 300 多支队伍注册参加;14 篇论文入选了今年的 CVPR,比去年多出 6 篇,其中 1 篇入选口头报告(Oral Presentation,5.6% 接收率)。
参加 CVPR 对以算法为核心的旷视有重要的战略意义。2019 年伊始,在成立八年之际,旷视宣布了从品牌到战略的全面升级,并且确立了以算法为核心基因,围绕计算视觉及相关传感技术开发感知、控制、优化算法,包括但不限于人脸识别、手势识别、文字识别、物体检测、视频分析、三维重建、智能传感与控制等机器学习技术。
一方面,学术会议的同行评议,是考验旷视技术的试金石;另一方面,旷视也在借此机会吸引人才,鼓励学术界思考中国计算机视觉行业的特殊需求,并回馈研究社区。
旷视首席科学家和研究院院长孙剑告诉机器之心,「在一次和姚期智先生(也是旷视学术委员会主席)的座谈上,姚先生说的非常好:『发表论文、参加学术会议,其实是有人对你的工作鼓掌,激励你继续前行。』」
6 项冠军背后的算法优势
挑战赛可以看成是技术预演的过程,处于研究和产品之间的环节。通过挑战赛,研究员可以打造更好的集成架构、优化算法、测试极端情况,在挑战赛上验证过的技术有助于加快产品落地。
今年,旷视横扫了 6 个挑战赛项目,涵盖自动驾驶、细粒度识别、终端图像处理、3D 物体识别等众多领域,且含金量都很高,分别是:
1.自动驾驶方向
WAD nuScenes 3D Detection Challenge
WAD Domain Adaption Detection Challenge
WAD Domain Adaption Tracking Challenge
2.细粒度图像识别
FGVC iNaturalist
FGVC Herbarium
3.图像恢复和增强
NTIRE Real Image Denoising Challenge
以 iNaturalist 为例,这是细粒度图像识别里的标杆性比赛,要求参赛团队在上千种动植物子类别中实现图像识别,被看作是该领域的 ImageNet。iNaturalist 所属的细粒度视频分类(FGVC)研讨会,在 CVPR 上已经举办过六届。
旷视的参赛团队来自南京研究院,细粒度图像分析是其基础研究方向之一,他们也涉猎小样本、深度学习、物体检测、图卷积等领域。南京研究院的负责人魏秀参告诉机器之心,今年 iNaturalist 的难度相比往年有所提升,主要体现在三个方面:
首先,数据集不仅涵盖了一千多个动植物品类,而且有些动植物类别之间的差别普通人根本看不出,比如你知道下图哪张是「白腹蓝彩鹀」,哪张是「靛彩鹀」吗?这些问题只有植物专家或者动物专家才能回答。

上图是靛彩鹀,下图是白腹蓝彩鹀
其次,这是一个长尾分布的数据。所谓的长尾分布指的是大约 20% 的类别包含 80% 的图像,而 80% 的类别只覆盖 20% 的数据,所以整个数据集呈现指数递减趋势,这对解决实际问题带来了很大的挑战性。
再者,除了识别动植物,在具体的一个类别,还需要识别动植物不同的发育期状态。比如说一些两栖动物可能会有一些变态反应,不同的状态需要进行精细的甄别。
魏秀参介绍说,此次参加挑战赛的模型集成了最前沿细粒度技术成果,包括 Coarse-to-fine hierarchical classification、iSQRT、Class-Balanced Focal Loss 等;同时,团队也提出「后验概率重校准」技术,即通过先验知识对模型输出的后验概率进行校准,极大提高拥有较少训练图像的长尾类别的识别准确率。最终结果,旷视在 iNaturalist 挑战赛上比第二、三名领先了一个身位。
在另一个细粒度图像识别的比赛 Herbarium Challenge(植物标本挑战赛)中,参赛团队需要从植物标本中鉴定开花植物物种(Melastomes),数据来自纽约植物园。旷视击败了去年的冠军、今年的第二名大连理工。
多说一个细节:在细粒度图像识别的挑战赛上获胜的模型使用了旷视自研的 Brain++ AutoML 技术。旷视内部采用了 One-shot 神经架构搜索的方法,兼顾了性能、效率、灵活性,使得 Brain++ AutoML 可以在实际模型生成中实现快速落地和调用。
这是旷视南京研究院第一次参加 CVPR 的挑战赛。从 2017 年组建至今,南京研究院希望将此机会将多年积累的技术放到国际舞台上比一比。魏秀参后来透露,挑战赛的胜利提升了团队的自信心和凝聚力。
相比于在 iNaturalist 挑战赛上的突破,旷视研究院检测组负责人俞刚带队获得自动驾驶挑战赛三项冠军更像是「常规操作」。在去年 CVPR 上,俞刚带队就获得了自动驾驶识别挑战赛实例视频分割(Instance-level Video Segmentation)的冠军。今年,旷视分别在 BDD100K & D²-City 目标检测迁移学习挑战赛、D²-City & BDD100K 目标跟踪迁移学习挑战赛以及 nuScenes 3D 检测上获得冠军。

nuScenes 3D 检测是此次自动驾驶挑战赛的一个亮点。nuScenes 是今年自动驾驶公司 Aptiv 发布的一个全新数据集,除了包括每段 20 秒的 1000 个场景以及 140 万幅图像外,该数据集使用了新的 3D 方法来整合物体检测,并且发布了 39 万个激光雷达扫描输出。尽管旷视目前并未明确涉猎自动驾驶业务,但俞刚表示,旷视希望通过 3D 和 2D 的结合,提前布局以应对未来精度敏感的产品落地。
在这项挑战赛中,旷视设计了一个多尺度、多任务的模型,借助新型检测网络,结合均衡采样等策略,极大提高了模型的检测精度,尤其是在小物体上。最终,旷视模型比官方基准(45.3%)高出 18 个点,达到 63.3%,比第二名也高出 8.8 个点,击败了包括香港中文大学在内的顶尖团队。
另外两个 D²-City & BDD100K 的场景迁移挑战赛,看重的是算法的检测和泛化能力。D²-City 是滴滴发布的大型数据集,而 BDD100K 则是去年加州伯克利大学发布的开源数据集。前者是国内数据,后者是美国路况,场景差异巨大,这就考验了算法在不同场景的迁移能力。
首次主办挑战赛,大型数据集助推科研发展
除了作为参赛者的身份外,旷视也首次在 CVPR 举办了研讨会和挑战赛——DIW 物体检测挑战赛(Detection In the Wild Challenge Workshop)。一家创业公司回馈社区,加速技术推进。这样的做法确实令人惊喜。
国内的技术公司在过去一直扮演着模仿和追赶的角色,但在人工智能时代,这些企业正逐步掌握话语权。众多在工业界发现的问题学术界鲜有涉猎,只有在数据量庞大、场景多元的中国才能被挖掘出来,这些问题的解决将对整个研究领域带来巨大的推动作用,但需要有公司抛砖引玉。这就是旷视正在做的事情。
旷视为物体检测任务引入了两个新的基准挑战赛:Objects365 和 CrowdHuman。Objects365 用于解决 365 个物体类别的大规模检测问题。挑战赛设置了两个方向:60 万训练图像上的所有 365 个物体类别、以及用于在训练图像的子集上处理 100 个具有挑战性的类别。而 CrowdHuman 是为人群人体检测问题而设计,数据集包含了 34 万人类实例。
本质上,旷视希望通过挑战赛的形式,由数据层面出发推动算法性能,拉高技术的上限达到实际产品需要的水准。俞刚负责此次挑战赛的筹备,他告诉机器之心,此次挑战赛总共有 300 多个队伍报名注册,有 70 多个队伍给出了实验结果。参赛的前几名选手的结果比旷视内部的基准都高了很多,这给旷视带来了许多创新思路。

DIW Workshop 现场
夜摄 Demo 展示:底层架构加快产品转化
自 2016 年起,CVPR 专门辟出一块区域用作工业展区,允许科技公司展示技术产品,增加和学界的交流。旷视今年带来了 4 个 demo:动作控制街头霸王对打、单摄视频虚化、夜摄超画质以及 SLAM 机器人。
夜摄超画质的 demo 位于旷视 CVPR 展台的一角,有一个用纸箱搭建的暗光环境,纸箱内摆放了各种玩偶作为拍摄对象。用来测试的机型是刚刚搭载旷视夜摄技术的 Oppo Reno 10。

旷视超画质样张展示(右),遇到有多点灯光等人工照明的城市风光场景时,旷视超画质技术都能给用户带来非凡的夜拍体验
经过测试,机器之心记者发现该 demo 体现了两个特点:一是拍照速度快,和传统夜摄功能要求握住手机拍摄几秒不同,Oppo Reno 10 的夜摄拍照和平时拍照的速度差异不大;二是图像细节逼真,因为纸箱里有毛线团,在暗光环境里手机依然能清晰地呈现出一根根毛线的细节。
目前,高端手机在正常光线下拍照下的成像差距不大,只有在极端情况才能体现差异,比如夜摄。去年谷歌发布的 Pixel 3 和今年华为发布的 P30 都依靠优秀的夜摄能力收获了一票用户。
但旷视的视觉专家王珏告诉机器之心,谷歌和华为背后所使用的图像降噪方法依然有缺点。传统的图像降噪是用多帧降噪来弥补夜间进光量不足的问题,归根结底是图像噪声和信号比太高,通过照片叠加可以增强信号去掉噪声,但弊端是需要拍多张并且保持手机不动,这需要用户等上 3-4 秒的时间。手一抖就容易在照片出现拖影,也就是摄影界俗称的「鬼影」。
王珏团队想到了针对原始图像的神经网络方法。这条路过去几乎没有人走过,不仅仅是由于学界对原始图像的图像降噪还处于早期阶段,体量巨大的神经网络模型如何在手机端上快速运行是另一大挑战。
一个看似简单的手机夜摄业务,中间有许多不为人知的细节打磨。这个过程,既有研究思路上的创新:比如旷视研究员从上世纪 70、80 年代的一些经典论文中研究了噪声的统计规律和模拟的方法,研究了成像模式以后,数据生成的流程就被极大地简化。
同时,也依赖于旷视内部多年来的技术积累。王珏透露,公司内部有一个 Model Zoo 的「武器库」,这个平台存储了许多模型,基于不同的平台、功耗要求、运算速度。研究团队基于自身业务的需求,只要从 Model Zoo 中挑选几十个模型架构加以微调,就可以极大地加快开发速度。最终模型的大小只有 2.5G,整个拍照曝光时间控制在 300 毫秒左右。
项目落地之余,王珏也带领团队「顺便」参加了 CVPR 的去噪挑战赛—NTIRE 2019 Real Image Denoising Challenge - Track 1: Raw-RGB,获得了冠军。团队在研讨会上分享完技术细节后,台下的来自谷歌和三星的研究员都对旷视如何能将模型做到这么小、在终端跑地那么快表示好奇。

王珏透露,这里面有旷视的底层系统化人工智能框架「旷视 Brain++」和人工智能数据管理平台「旷视 Data++」的功劳。旷视从 2014 年开始就在开发 Brain++Engine,在 TensorFlow 还未出世、Caffe 和 Theano 等机器学习框架不适用自身业务的年代,旷视希望通过「旷视 Brain++」打造一套端到端的算法引擎,打通从数据到部署的算法全要素、全流程生产。王珏说,他们的模型一旦训练完之后,Brain++Engine 可以做到一键打包在手机上封装,实现终端优化和加速。
「旷视 Data++」是另一个旷视自研的数据标注和管理平台。这可以节省研究员大量的时间,加速研究效率。前文提到的 Objects365 物体检测数据集就是「旷视 Data++」提供的。
研究思路:应用导向和前沿探索双管齐下
此次旷视入选 CVPR 的 14 篇论文,涉及了行人重识别、场景文字检测、全景分割、图像超分辨率、语义分割、时空检测等技术方向。除了应用导向的工作以外,也探索了一些前沿学术问题。
孙剑是这样总结的,「我们研究的的问题分两类: 直接和产品相关的技术问题,间接和产品相关的基础问题。」
「前者因为有「旷视 Brain++」这个系统,可以很高效的将研发出来的技术或者算法模型直接应该到产品上去。」
「后者的关键在于两方面。一方面是选题,既不能搞短期的小修小补,也不能搞漫无边际的发散式研究,这是个认识和判断问题;另一方面是选题后的坚持和变通。基础研究的一个很大特性是成功的可预测性低,这就要求既要我们坚持大方向,也要懂得适时的变通,修正目标或路线,这其实是个平衡问题。」
旷视目前的业务主线分为三块:以手机为核心的个人设备大脑场景,以城市传感器为核心的城市大脑场景,以及包含智能制造、智能物流、智能零售的供应链大脑场景。
以旷视研究院物体检测组为例,此次入选 CVPR 的 4 篇论文主要来自个人设备大脑和城市大脑的场景需求,将产品中遇到的问题抽象出一些概念和细节,当成研究问题去解决。
比如,来自旷视研究院检测组的论文《Shape Robust Text Detection with Progressive Scale Expansion Network》提出了一种新颖的渐进式尺度可拓展网络 PSENet 模型,针对场景文字检测中任意形状文本问题。
旷视的文字检测技术有很多应用落脚点,比如车牌检测、证件照检测。这篇论文主要讨论了场景文本检测领域的两个挑战:其一,边界框在定位任意形状的文字时的性能很差,精度很低;其二,对于场景中两个彼此接近、互相干扰的文本,现有技术可能会产生误检。论文提出的 PSENet 模型能够为每个文本实例生成不同比例的核 (kernel),并将最小比例的 kernel 逐步扩展生成完整形状比例的 kernel,以适应不同大小的文本实例。
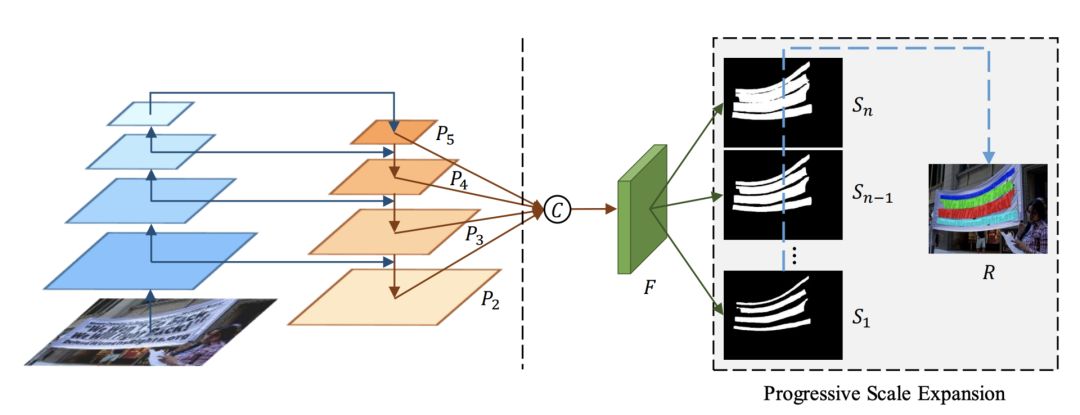
PSENet 模型的 pipeline
另一篇来自检测组的论文《TACNet: Transition-Aware Context Network for Spatio-Temporal Action Detection》,在时空动作检测研究领域针对时间维度问题提出了网络——TACNet(上下文转换感知网络),可以改善时空动作检测性能。这篇论文的应用落脚点是动作行为检测,针对城市管理领域的产品设计。以老人的意外摔倒为例,一个月可能都没有发生一次意外,用人工检测视频里的摔倒行为成本很高,但是算法可以有效地检测动作行为。
这篇论文的主要贡献是定义真实行为和非真实行为的边界。TACNet(上下文转换感知网络)可以将类似于真实行为的模糊状态样本定义为「转换状态 (transitional states)」,简单来说是将视频不重要的部分弱化,而将注意力放在真正产生动作行为上。
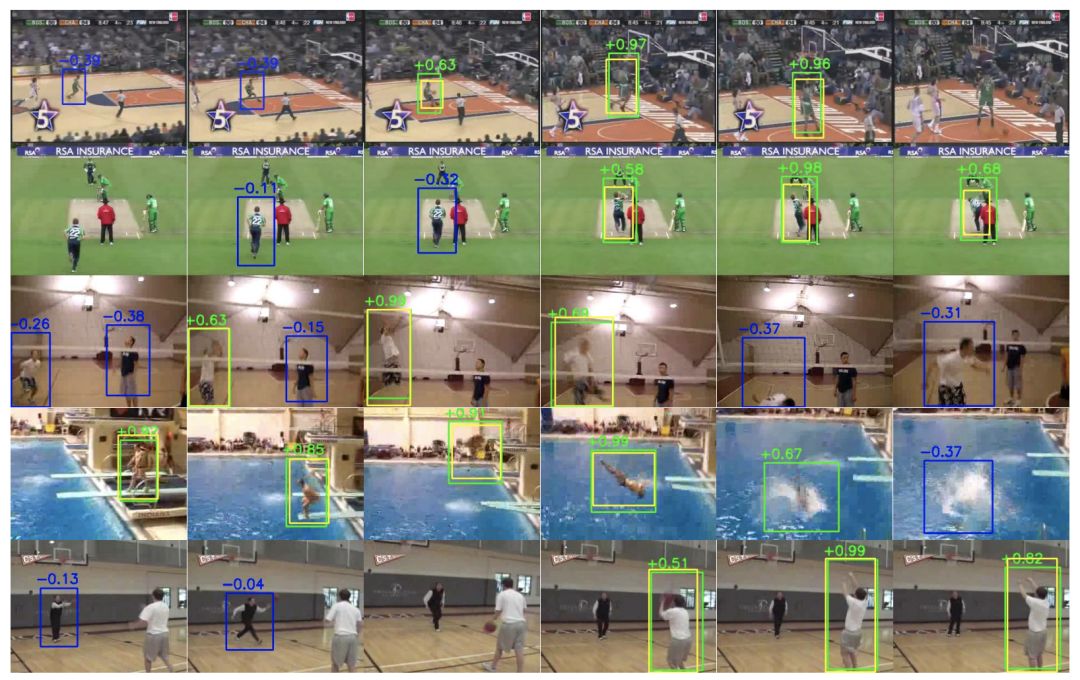
转换状态是蓝框,活动状态是绿框,黄框是 ground truth。
同时,旷视也在放眼未来做长期的预演。国内计算机视觉公司竞争进入白热化,头部公司之间的在已有技术上的差距并不明显,要形成差异,必须着眼于计算机视觉的未来,提前筑起技术优势壁垒。
旷视入选此次 CVPR 的论文中,关于 3D 点云结构的研究和图像超分辨率研究属于前沿探索。以物体检测为例,尽管目前大部分的计算机视觉工作都是围绕 2D,但 2D 检测本身存在天花板。其网络结构主要是一个金字塔形状,图像越卷积下去越小,特征图谱丢失的信息越多,对检测的最终结果有很大的影响。
除了调整 2D 网络结构做优化之外,旷视认为研究 3D 检测,与 2D 信息形成互补是一个趋势。点云所提供的形状信息对物体检测和定位带来有效的帮助,和 2D 信息的纹理颜色等特征互补。
在论文《Modeling Local Geometric Structure of 3D Point Clouds using Geo-CNN》中,旷视提出了 Geo-CNN 模型,将深度卷积神经网络应用于 3D 点云数据局部区域中点的几何结构建模。
图像超分辨率的论文《Zoom in with Meta-SR: A Magnification-Arbitrary Network for Super-Resolution》来自旷视研究院基础模型组,负责人张祥雨说,这篇研究背后的思路是基于权重预测,这是他个人非常看好的一个研究方向。他们提出了一种称为 Meta-SR 的新方法,具体来说,Meta-SR 可以通过将任意缩放因子作为输入来动态地预测每个 upscale 滤波器的权重,并使用这些权重来生成其他任意大小的高分辨率图像 (HR)。
基础模型组在旷视研究院内负责公司中长期的研究项目,着重在前沿探索,包括权重预测、自动化机器学习(AutoML)、边界框标注都是张祥雨的关注重点。
结语:旷视的技术信仰
这是旷视第五次参加 CVPR 了。过去,中国公司参加学术会议更多是为了刷存在感,互相之间比拼论文数量非要争个高低。但在今年 CVPR 上,记者能看到这家创业公司身上成长的痕迹:
论文课题和产品落地之间有更紧密的联系。写论文的目的不是为了刷学术业绩,而是将科研结果转化成产品竞争力。通过学术会议获得同行认可,并最终带来实际的商业价值。
旷视研究院算法总监范浩强告诉机器之心,「旷视始终相信,要坚持产品导向,为产品找技术,用学界标杆作为产品定义的牵引。」
成长是一个过程,旷视经历过起步的艰辛,也走过不少弯路。俞刚曾经回忆,过去检测组的成员都只能复现前沿的论文,他一直鼓励研究员不要去抄代码,自己去摸索论文细节来复现。经过几年的积累,团队开始主攻算法的自主研发,赢了几个挑战赛后,团队也找到了方向和信心。
王珏对夜摄项目落地的感触特别深,加入旷视之前,王珏是 Adobe 的首席科学家,在计算机视觉计算机图形学和人机交互有着卓越的学术贡献。在旷视,王珏的目标是为开拓新的市场和业务线,提供强有力的技术支持,这需要王珏去适应角色的转变,从一个研究者到一个项目管理者。
「你怎么才能把研究做成一件可以预测的事情,工程追求的一种可控性,研究充满了不确定性。在这两者之间实际上是有矛盾的。经过这个项目,我们现在就很从容,整个团队得到锻炼,我们也知道怎么和客户打交道。」
「我始终相信两点:中国不缺乏聪明人,中国有世界上最好的发展机会,」孙剑补充道。「我们就是要把一帮聪明人聚起来,齐心协力,贯彻『发展就是硬道理』。」
今年的 CVPR 已经落下帷幕,但旷视的故事还将继续。
本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



