干货 | 算法工程师入门第二期——穆黎森讲增强学习(一)

雷锋网(公众号:雷锋网)按:本期地平线资深算法工程师、增强学习专家穆黎森将为大家带来增强学习简介(一),本讲内容主要涉及增强学习基本概念及Deep Q Learning的相关内容。

今天我很荣幸有机会在这里,跟大家分享增强学习(Reinforcement Learning,RL)这个话题。这次分享,我希望能达到三方面的目的:
第一,希望没有相关背景的同学能够对RL有一定的了解,所以我会介绍一些基础的概念。
第二,希望对有机器学习算法背景的同学,如果对增强学习感兴趣的话,能了解到RL近期的一些进展。
第三,对我而言也是对于相关知识的整理。
这次分享主要包括以下三个环节:
关于增强学习的一些基本概念;
Deep Q Learning。DQN这个工作成功地把深度学习应用在了RL领域,所以会单独介绍一下;
在Deep Q Learning之后,近期的一些进展。
基础概念
机器学习
首先,什么是增强学习,它和监督学习有什么不同?
他们都有学习这个词,那什么是机器学习呢?根据Tom M. Mitchell的表述:为了完成某个任务(Task)的计算机程序,如果随着某种形式的经验(Experience)的增加,在某个表现度量(Performance measure)的衡量下,表现越来越好,我们就可以说,这是一个机器学习的程序。
所以这里,机器学习的三个特征元素:T:Task, E: Experience, P: Performance measure。先举一个反例。
假设现在需要完成的任务是,根据下班的时刻,预测回家花在路上的时间。我们知道,高峰期会堵车,回家时间会长一些;如果加班到晚上,路上会更通畅一些。这时候,我写了一个程序来完成这个任务:f(t)=1.0 – 0.5 * (t-18) / 6
t 为时刻,取值[18,24];返回值表示小时数。很明显,只要输入确定,这个程序(算法)的输出就确定了;所以,是不具有学习的能力的。究其原因,是算法中没有任何可以改变的部分。所以,我可以写另外一个程序:f(t)=a – b * (t-18) / 6
其中,a,b是两个变量,如果我们的算法能让f(t)在执行了多次预测后,不断调整a,b的值,使之结果结果越来越接近真实的值,那么,这个算法是具有学习的能力的。 所以,通常机器学习的算法程序,其中需要有一部分是可以随着Experience而自动调整的。这些可改变的部分,通常属于算法模型(Model)的一部分。
这里引入模型(Model)的概念。对于比较复杂的任务,完美完成这个任务的真实的函数我们通常不知道,既不知道他的参数,甚至也不知道他的结构。那我们就对这个函数的结构做一个假设,叫做模型(Model),比如说我们假设它是一个用神经网络(neural network)可以去解决的问题,然后用这个模型来逼近我们想要的真实函数。这个Model里通常会有很多的参数,也就是可以改变的自由度。这些自由度就组成了一个空间,我们需要做的就是在这个空间里面去寻找,到底哪一个参数组合能让这个Model最接近我们想要的真实函数。
在很多机器学习的算法中,学习的过程,就是寻找模型的最优参数的过程。
监督学习
我们来看第一个任务的例子,图像分类(Image Classification)。

我们知道,如果有标注好的数据集,就可以用监督学习的方法来完成这个任务。那么在这里,机器学习的三个元素:
T: Task 是把每张图片标注一个合适的label;
E: Experience是很多已经标注好的图像的数据集;
P: Performance Measure 就是标注的准确度,比如Precision、Recall这些CV领域的衡量标准。
监督学习怎么解决这个问题呢?首先,建立一个模型(Model),model的输入是图像,输出是图像的分类标签。然后,对于标注好的图像,用另外一个函数去衡量model的输出与正确的输出之前的差距,这个函数通常被叫做损失函数(loss function)。于是,改进model的表现的问题,就转化成了一个优化问题:通过改变model的参数,让loss function值越来越接近极小值。优化问题(optimization)又是一个比较大的话题,就可以用各种各样的数值方法去求解。从优化问题的角度来讲,监督学习的特点就是loss function由model输出和正确输出之间的差别直接构造而来。
增强学习
我们来看第二个任务的例子,玩游戏。
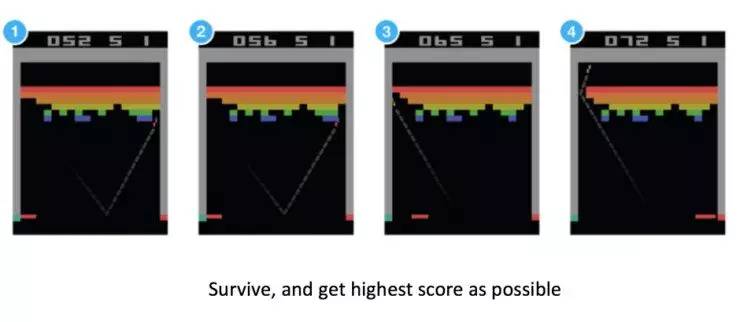
这个任务的目标是得到尽量高的分数。在这个任务里,通常不再有“标注好的数据”以供使用:在第一个局面下,应该往左;在第四个局面下,应该往右,等等。这种情况下,我们可以用增强学习的方法来完成这个任务。机器学习的三个元素:
T: Task是游戏结束时,得到尽量高的分数;
E: Experience 是不断的尝试玩这个游戏;
P: Performance measure 就是最后获取的分数。
可以看到上述两个例子之间的区别。相似的问题还有很多:

例如下围棋,或者很多棋牌类游戏到最后一刻决定输赢的时候,我才知道我是赢(得分+1),还是输(得分-1),但是中间也许并不是每时每刻都有一个直接的信号告诉我应该下在哪里;
例如驾驶,成功到达了目标,中间有没有发生事故或者违反交通规则,就算成功完成了这个任务(+1),中间也许并不是每时每刻都有一个专家来指导当前应该怎么前进;
例如机器人控制, 机械臂成功抓取到物体就算完成(+1),但是事先并不知道每个时间点,每种情况下,机械臂的每一个电机应该输入的电压是多少。
根据刚才的例子,我们提炼出增强学习的一般过程中,所涉及到的模块:
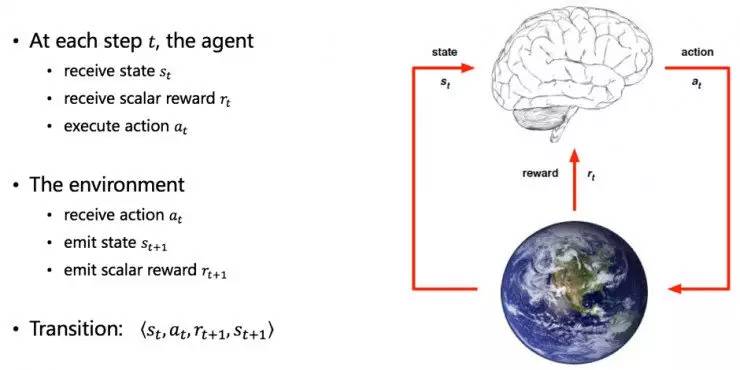
Agent,包括了我们需要学习的model,他是通过输入的状态(State)输出一个行为(Action),通过这个action和环境(Environment)去交互,收集到奖励(Reward);学习的目标是需要去最大化累积的回馈。
可以看到,在一般性的定义下:
T: Task就是为了执行某个任务,在某个特定环境下得到一个最优或者说比较优的策略。
E: Experience就是我不断地去和环境交互,所得到的交互结果,单次的交互我们把它叫做Transition,连续的交互序列也叫做Trajectory。一条完整的trajectory是从初始状态出发,到结束状态(如果有的话)为止。无结束状态的任务,trajectory可以无限延续;有结束状态的任务也被称为Episodic task。
P: Performance Measure: 在RL里,通常使用的Performance Measure叫做Discounted Future Reward。
Discounted Future Reward
Discounted Future Reward 定义如下:

也就是最后一行。我们希望Agent能给出一个策略(Policy):在某个state下,输出action,使得收到的Discounted Future Reward 最大化。
通常γ会选取一个小于1大于0的值。如果取0的话,相当于策略只用考虑当前一步能收集到的奖励而不顾及长期回报;如果取1的话,则不好处理持续(无限长)的决策序列问题。
Policy, Value, Transition Model
增强学习中,比较重要的几个概念:

Policy 就是我们的算法追求的目标,可以看做一个函数,在输入state的时候,能够返回此时应该执行的action或者action的概率分布。
Value,价值函数,表示在输入state,action的时候,能够返回在 state下,执行这个action能得到的Discounted future reward的(期望)值。
Transition model是说环境本身的结构与特性:当在state执行action的时候,系统会进入的下一个state,也包括可能收到的reward。
所以很显然,以上三者互相关联。如果能得到一个好的Policy function的话,那算法的目的已经达到了。 如果能得到一个好的Value function的话,那么就可以在这个state下,选取value值高的那个action, 自然也是一个较好的策略。如果能的到一个好的transition model的话,一方面,有可能可以通过这个transition model直接推演出最佳的策略;另一方面,也可以用来指导policy function或者value function 的学习过程。
所以,增强学习的方法,大体可以分为三类:

Value-based RL,值方法。显式地构造一个model 来表示值函数Q,找到最优策略对应的Q 函数,自然就找到了最优策略。
Policy-based RL,策略方法。显式地构造一个model来表示策略函数,然后去寻找能最大化discounted future reward的。
Model-based RL,基于环境模型的方法。先得到关于environment transition的model,然后再根据这个model去寻求最佳的策略。
以上三种方法并不是一个严格的划分,很多RL算法同时具有一种以上的特性。
Bellman Equation
根据以上R(Discounted Future Reward),Q的定义,我们可以得到Bellman Equation:
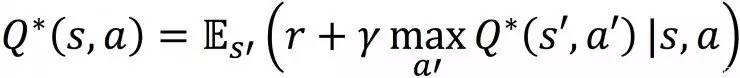
Bellman Equation 是RL中非常基础的一个公式。因为对于Value Based method 来说,Bellman Equation 给出了一个迭代改进Q函数的方法:
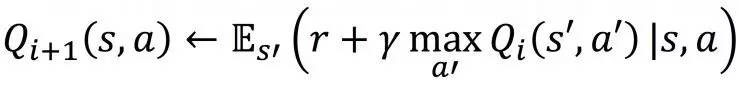
而对于Policy Based Method 来说, 通常需要通过采样的方式对Q值进行估计;在各种各样的估计方法中,Bellman Equation也扮演了重要的角色。
Value Based Method
这里给出一个值方法的算法的例子:Q learning

Policy Based Method
这里给出策略方法的一个例子:policy gradient

所谓策略梯度,是指当策略函数可微的时候,通过找到一个合适的loss function來使得策略函数的模型可以用基于梯度的优化方法来迭代改进。关于loss function的构造有很多种形式,上面的例子是比较基础的形式,这里就不展开了,不过其基本的效果是,让策略函数倾向于输出“更好的”action:对于随机策略来说,即意味着增大能获得更大的期望Q值的action的概率。
Deep Q Learning
回顾一下之前举的Q learning的例子。最早的Q-learning使用一个表格来表示Q函数:对于每一个state, action对,保存一个对应的Q值。Q learning的过程就是迭代修改这个表格的过程。可以发现,当state数量非常多,或者不再可枚举、维度非常高的情况下,表格就不适用了;需要用更经济的model来模拟这个表格。
深度神经网络(Deep Neural Network),在计算机视觉领域已经被证明是一个非常强大的函数拟合工具,可以用来表达非常复杂的视觉处理函数,来处理高维的图像输入。基于DNN的方法已经成为计算机视觉中很多问题的最好的解决方法。所以,是否能将更强的工具DNN,引入RL领域,来解决更困难的问题呢?
Deep Q learning 这个工作就是将DNN/CNN引入RL来作为Q函数的model。
DNN的loss function 定义如下:
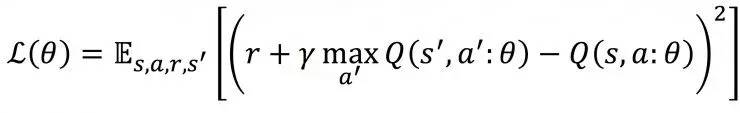
这个loss function也是由Bellman equation得出,其中
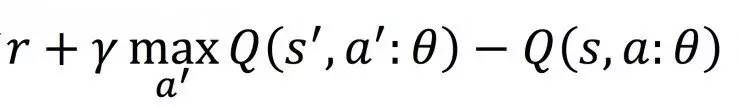
也被称为Temporal Difference,TD。可以看出,这也是一个迭代的过程:通过当前的Q函数的输出和环境中收集到的奖励r,来得到新的修正后的Q值。
新的挑战
但是,神经网络的引入,也引发了新的问题。
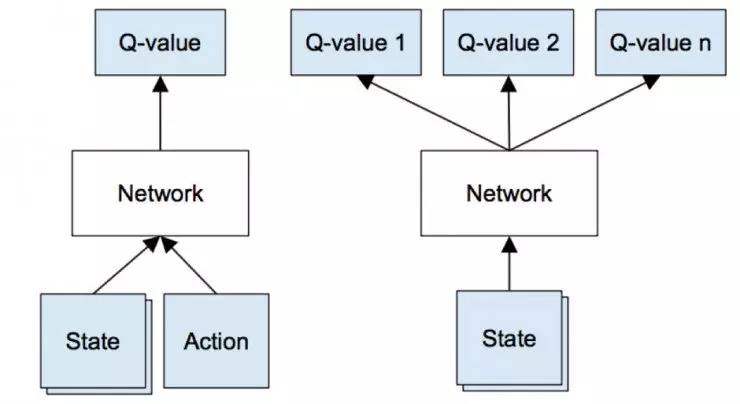
第一个问题是神经网络的计算代价较大,所以对函数的形式从上图左边所示调整为右边,一次计算就能得出这个state下所有action的Q值。
第二个问题是,在RL中,agent和environment交互所得到的transition序列的数据不是独立同分布的;而对于神经网络的训练来说,训练数据采样的独立同分布是非常有必要的。所以,这里引入了一个replay memory的机制,将transition保存到一定大小的replay memory中,然后从中重新采样。这样,样本之间的相关性就小很多了。
第三个问题是,由于新的Q值是由原来的Q值计算而来,更新后的神经网络又用来计算新一轮的Q值,对于神经网络来说,相当于不断拟合一个移动的目标值,可能会产生一种正反馈效应,让训练的过程变得发散。解决这个问题的手段是,增加一个目标网络target用来计算新的Q值,让这个目标网络隔一段时间更新成当前的网络参数,所以,target网络在两次更新之间保持不变,网络拟合目标的移动问题也得到了缓解。
在DQN这个工作中,使用了卷积神经网络(CNN)来处理图像的输入,最后输出游戏的动作指令;成功地实现了仅根据观察游戏的屏幕输出和奖励来学会玩游戏的过程。
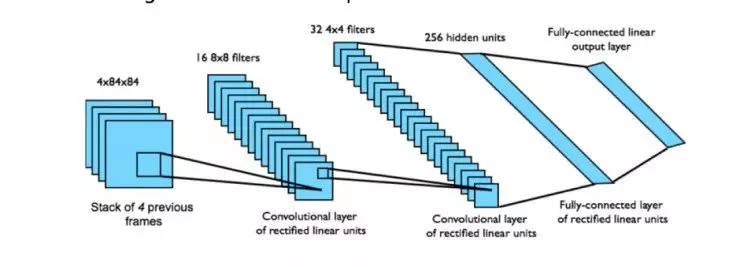
这里,相邻的4帧被合并到一起,作为一个state,这样,神经网络有机会从多帧抽取信息,比如屏幕上物体的运动速度。
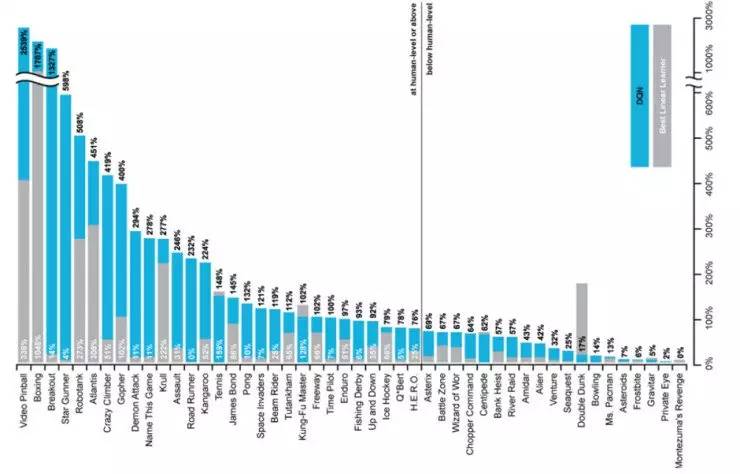
可以看到,在不少游戏上,DQN都达到了人类的操作水平。

媒体合作请联系:
邮箱:contact@dataunion.org




