春节充电系列:李宏毅2017机器学习课程学习笔记02之Regression
【导读】我们在上一节的内容中已经为大家简介了台大李宏毅老师的机器学习课程内容,本节我们开始跟大家聊一聊其中的具体技术。今天我们要介绍的就是回归分析(regression),回归分析是机器学习重要的技术之一,被广泛应用于预测问题(如,股票市场预测、推荐系统等)。本文将主要介绍回归分析的问题,包括:损失函数、梯度下降、过拟合、正则化等。希望通过简明的介绍能让大家直观地掌握这些回归分析中最关键的问题。
春节充电系列:李宏毅2017机器学习课程学习笔记01之简介
课件网址:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17_2.html
视频网址:
https://www.bilibili.com/video/av15889450/index_1.html

李宏毅机器学习笔记—Regression
▌1.简介
Regression广泛应用于股票市场预测,自动驾驶汽车,推荐系统中

▌2. polemon进化后cp值预测
文中通过预测pokemon进化后的cp值来举例,进化后的cp值可能和许多因素有关
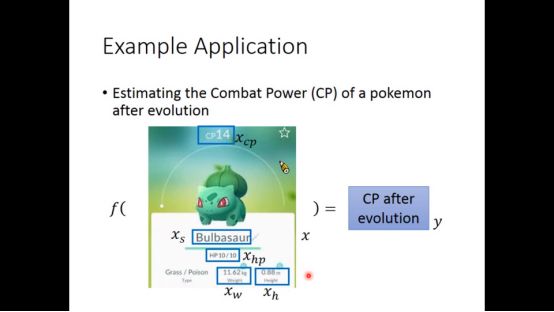
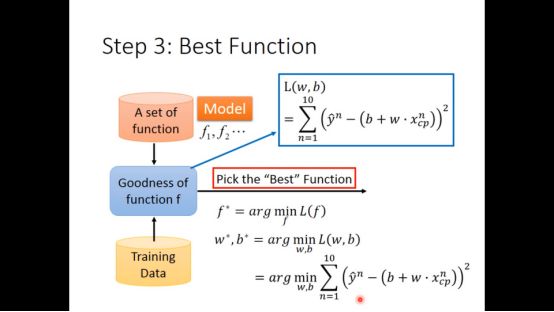
第一步为确定model,即函数集,根据pokemon固有的特征,建立方程来预测,线性方程有两个参数:w,b,我们最开始认为进化后的cp值只和进化前的cp值有关
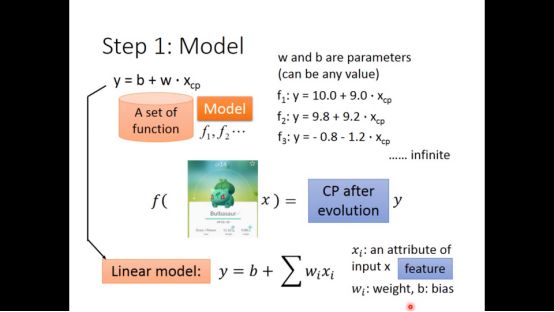
文中给出了10组训练集,x即是pokemon,y为其进化后真实cp值
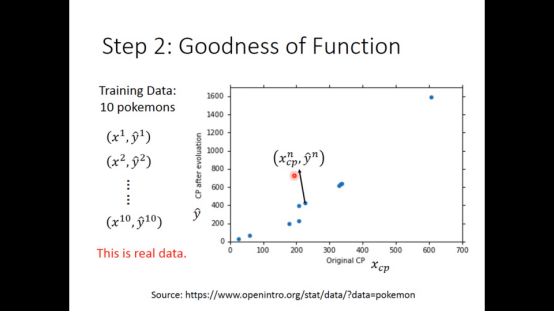
定义了一个loss function来评价该函数的好坏

通过minimize loss function,选出最佳的w,b来得到最好的函数
▌3.Gradient descent
因为loss function为可微分的函数,所以采用梯度下降法来得到最佳的w,b,注意到 Linear regression 没有local minimal.因为loss function是凸函数
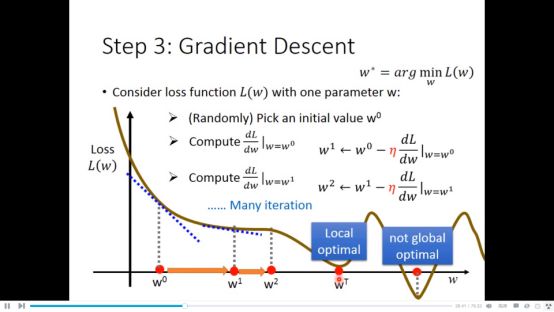
通过loss function分别对w,b做偏微分,我们可以得到


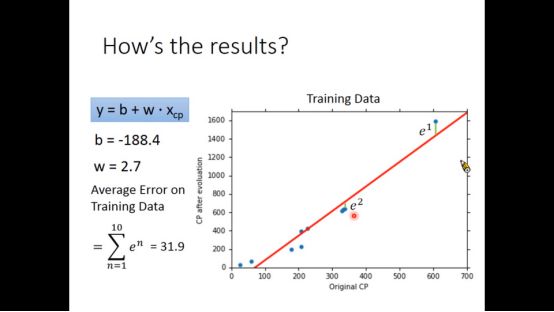
于是我们得到最终的结果,损失函数值为31.9
用test data进行验证,得到loss function的值为35.0,大于在训练集的错误率
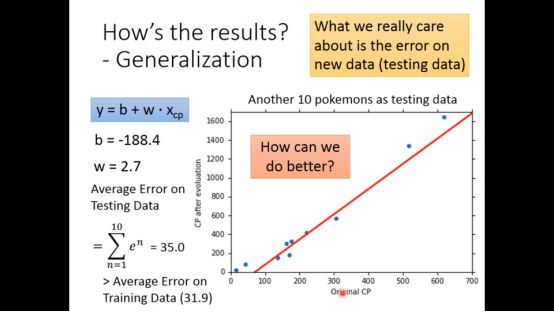
貌似不是很理想,再试图用更复杂的函数试试,即二次函数,结果显示更好
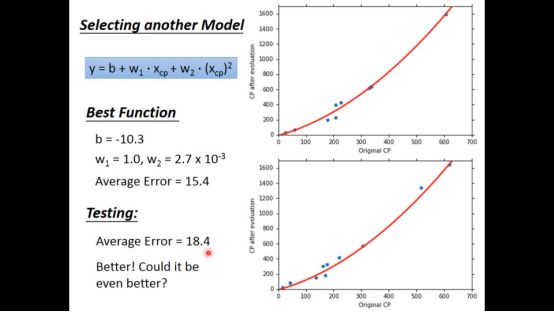
再试试三次函数,结果比二次函数更好
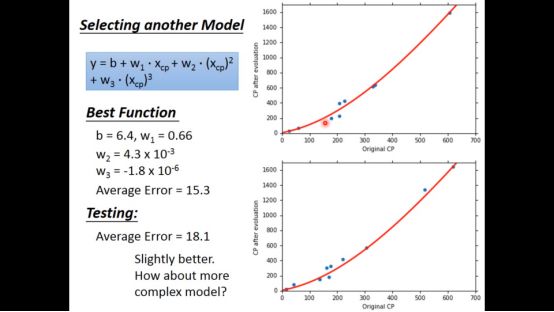
再试试4次函数,令人惊讶的是training error比以前更小,但testing erro比以前更大
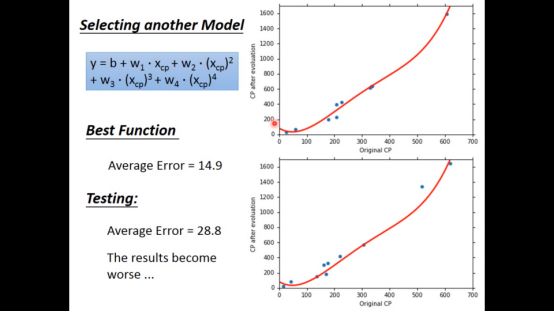
五次函数就更糟糕了
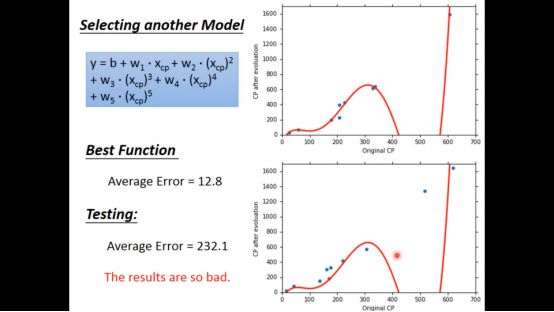
▌4. Overfitting
这一切的原因是overfitting,因为参数过多,导致函数能够完美拟合训练集,但对于测试集就差别很大了。

之前我们只考虑了进化前的cp值,但进化后的cp值可能和其他因素有关,可能都需要考虑,但无脑讲所有因素加入其中极有可能overfitting。
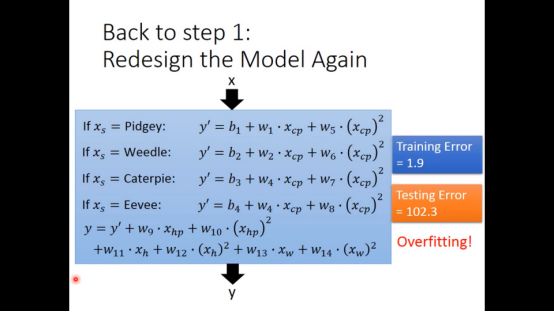
▌5. Regularization
为了解决这个问题,我们采用regularizaition的方法,目的是为了得到更平滑的loss function,即让w的值变小,使得loss function受x的影响小,具体形式如下图所示

从下图可以看出,入越大,training data error越大,越倾向于考虑入本来的值,更少考虑error。
入越大,test data可能比较小,我们喜欢比较平滑的function,但不喜欢太平滑的function,比如水平线,什么都干不成。
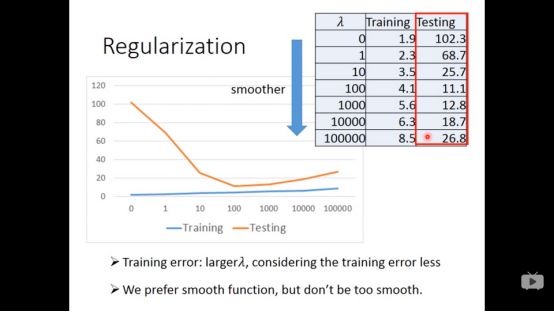
于是我们需要调参数,注意regularizaiton不需要考虑b,b和函数平滑无关。
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“LHY2017” 就可以获取 2017年李宏毅中文机器学习课程下载链接~
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!