ICCV2017 | 一文详解GAN之父Ian Goodfellow 演讲《生成对抗网络的原理与应用》(附完整PPT)

当地时间 10月 22 日到10月29日,两年一度的计算机视觉国际顶级会议 International Conference on Computer Vision(ICCV 2017)在意大利威尼斯开幕。Google Brain 研究科学家Ian Goodfellow在会上作为主题为《生成对抗网络(Generative Adversarial Networks)》的Tutorial 最新演讲, 介绍了GAN的原理和最新的应用。本文对Ian Goodfellow的演讲PPT进行了解读。
本文授权转自专知(Quan_zhuanzhi)
「对抗生成网络之父」Ian Goodfellow 在 ICCV 2017 上的 tutorial 演讲是聊他的代表作生成对抗网络(GAN/Generative Adversarial Networks),这几年,他每到大会就会讲 GAN,毕竟对抗生成网络之父的头衔在呢,这块也是这几年机器学习、计算机视觉等方向的研究热点之一。

Ian Goodfellow 是世界上最重要的 AI 研究者之一,他在 OpenAI(谷歌大脑的竞争对手,由 Elon Must 和 Sam Altman 创立)工作过不长的一段时间,今年3月重返 Google Brain, 加入Google Brain,其正在建立了一个探索“生成模型”(generative models)的新研究团队。

生成模型的概念大家应该都很熟悉,大概有两种玩法:
密度(概率)估计:就是说在不了解事件概率分布的情况下,先假设随机分布,然后通过数据观测来确定真正的概率密度是怎样的。
样本生成:这个就更好理解了,就是手上有一把训练样本数据,通过训练后的模型来生成类似的「样本」。
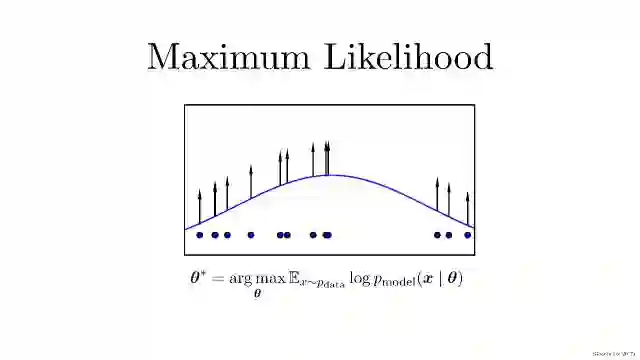
在生成模型这一过程中,首先需要提到概率领域一个方法:最大似然估计。现实生活中,我们可能并不知道每个 P(概率分布模型)到底是什么,我们已知的是我们可以观测到的源数据。所以,最大似然估计就是这种给定了观察数据以评估模型参数(也就是估计出分布模型应该是怎样的)的方法。
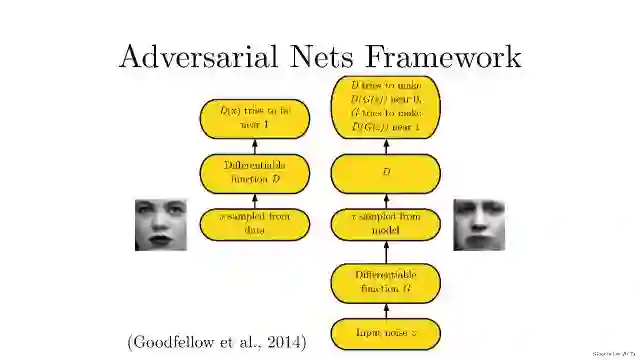
我们在理解生成对抗模型(GAN),首先要知道生成对抗模型拆开来是两个东西:一个是判别模型,一个是生成模型。就需要提及Ian Goodfellow在2014发表的文章。
文章标题:Generative Adversarial Networks
文章链接:https://arxiv.org/abs/1406.2661
具体如下:
简单打个比方就是:两个人比赛,看是 A 的矛厉害,还是 B 的盾厉害。比如,我们有一些真实数据,同时也有一把乱七八糟的假数据。A 拼命地把随手拿过来的假数据模仿成真实数据,并揉进真实数据里。B 则拼命地想把真实数据和假数据区分开。
这里,A 就是一个生成模型,类似于卖假货的,一个劲儿地学习如何骗过 B。而 B 则是一个判别模型,类似于警察叔叔,一个劲儿地学习如何分辨出 A 的骗人技巧。
如此这般,随着 B 的鉴别技巧的越来越牛,A 的骗人技巧也是越来越纯熟。
一个造假一流的 A,就是我们想要的生成模型!

我们现在能使用GANs做什么,这几年各种围绕关于GANs的研究应用很多很多。
学习训练数据的分布
在更多的情况是,我们会面临缺乏数据的情况,我们可以通过生成模型来补足。比如,用在半监督学习中
多标签预测(同时完成real/fake, 样本类别等的预测)
根据环境需要生成相应数据(比如,看到一个美女的背影,猜她正面是否会让你失望……)
可以模拟预测未来数据(用于具有时序关系的图像)
解决模型推断问题
学习不错的embedding(特征表示)信息

以保密为文化传统的苹果一贯不喜欢对外公布自己的研究成果。但2016年在机器学习的顶级大会NIPS上,苹果AI团队的负责人RussSalakhutdinov宣布,公司已经允许自己的AI研发人员对外公布论文成果。这则消息刚刚宣布没多久,苹果就发表了自己的第一篇论文,题目叫做《通过对抗训练从模拟与无监督图像中学习》,论文描述了如何利用计算机生成的图像而不是真实图像改进算法识别图像能力的训练。此举一方面可以提高苹果在AI界的存在感,同时如果其研究成果出色的话,也能在学术界赢得同行认可,并吸引到AI方面的人才。苹果第一篇AI论文一经投放,便在2017年7月22日,斩获CVPR 2017最佳论文。

谷歌新论文使用生成对抗网络的无监督像素级域适应, 发表在CVPR 2017:Unsupervised Pixel-Level Domain Adaptation WithGenerative Adversarial Networks
对于许多任务而言,收集标注良好的数据集去训练现代的机器学习算法是极其昂贵
的。渲染合成数据倒是一个吸引人的选择,本文的方法能以无监督的方式学习一个像素空间中从一个域到另一个域的变换。基于生成对抗网络(GAN)的方法能够使源域(source-domain)图像看起来就像是来自目标域(target domain)的一样。这个模型不仅能生成看似可信的样本,而且表现还极大超越了许多当前最佳的无监督域适应情况。

开始介绍面临缺乏数据的情况,我们可以通过生成模型来补足。

内容识别填充( Content-aware fill ,是 photoshop 的一个功能)是一个强大的工具,设计师和摄影师可以用它来填充图片中不想要的部分或者缺失的部分。在填充图片的缺失或损坏的部分时,图像补全和修复是两种密切相关的技术。有很多方法可以实现内容识别填充,图像补全和修复。在这篇博客中,我会介绍 RaymondYeh 和 Chen Chen 等人的一篇论文,“基于感知和语境损失的图像语义修补(Semantic Image Inpainting with Perceptual and ContextualLosses)”。论文在2016年7月26号发布于 arXiv 上,介绍了如何使用 DCGAN 网络来进行图像补全。

体验一下半监督学习。

将产生式对抗网络(GAN)拓展到半监督学习,通过强制判别器来输出类别标签。我们在一个数据集上训练一个产生式模型 G 以及 一个判别器 D,输入是N类当中的一个。在训练的时候,D被用于预测输入是属于 N+1的哪一个,这个+1是对应了G的输出。这种方法可以用于创造更加有效的分类器,并且可以比普通的GAN 产生更加高质量的样本。
文章标题:Semi-Supervised Learning with Generative Adversarial Networks;
文章链接:https://arxiv.org/abs/1606.01583。
文章标题:Improved Techniques for Training GANs
文章链接:https://arxiv.org/abs/1606.03498

开始介绍多标签预测(同时完成real/fake, 样本类别等的预测);

Next video frame prediction(未来帧预测) 主要完成的任务是根据视频中已有帧的相关数据预测某一帧所对应的下一帧数据,例如图中所示的人物头像数据(文章主要利用大量未标注数据)。通过GAN对其之前数据规律的学习,合成其未发生的下一帧数据。这可以使我们通过海量数据的学习,达到预测未来未发生事件的效果。
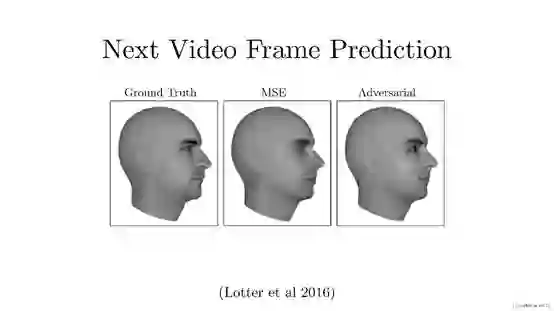
图中所示3张人物头像数据,图1为原始图像,图2是通过传统图像合成方式所得图像,图3为通过GAN生成的图像。通过图2和图3的对比可以发现通过GAN合成的图像边缘模糊情况大大减轻,图像分辨率有所提高,纹理与原图也更接近。这是Lotter 等人在2016年提出了一种新颖的“PredNet”结构。文章标题:Deep Predictive CodingNetworks for Video Prediction and Unsupervised Learning。 网址链接:https://arxiv.org/abs/1605.08104。

这个工作是Yann LeCun组的Michael Mathieu等人 2015年提出的。
文章标题:Deep multi-scale videoprediction beyond mean square error
网址链接:https://arxiv.org/abs/1511.06434
主要是用对抗式训练进行视频预测的,研究解决了一个非常重要的问题,那就是,当你训练一个神经网络(或者其他任何模型)来预测未来,如果要预测的东西有多种可能性时,一个网络以传统的方式进行预测(比如,用最小平方),将会预测出所有可能性的平均值。在视频的例子中,有很多模糊的混乱。对抗式训练能让系统产出其想要的任何东西,只要是在鉴别器喜欢的任何数据库内就可以,这解决了在不确定条件下进行预测的“模糊”难题。

下面介绍根据环境需要生成相应数据。

在自动生成任务中,在线时尚科技公司 Vue.ai 开发了一种或将取代模特的自动生成试装照片的系统,该系统使用GAN技术,可以控制所需模特照片的体型、肤色、身高、鞋子等等,不仅是模特,摄影师和工作室都可以不需要了,对于电商和零售业来说是好消息。这项技术由 Vue.ai 的 Anand Chandrasekaran 和 Costa Colbert 开发,使用了生成对抗网络(GAN)的机器学习方法。这个系统由两个AI组成:一个生成器(generative)和一个评论家(critic),生成器试图生成一张看起来很好的图像,而批评家则决定这张图像是否看起来足够好。

跳过两部分,直接讲如何得到数据的embedding(特征表示)信息。

在特征表示学习这块,Radford 等人在2015年提出了DCGAN。
文章标题:Unsupervised Representation Learning with DeepConvolutional Generative Adversarial Networks
网址链接:https://arxiv.org/abs/1511.06434
这篇文章,主要是想从大量无标签数据集中学习可重复使用的特征表示。在计算机视觉的背景下,实际上,可以利用不限数量的无标签图像和视频来学习一个好的中间表示,这个表示可以用在大量有监督的学习任务上,例如图像分类。提出一种方法,可以建立好的图像表示,通过训练对抗生成网络(GAN),并且反复利用生产网络和辨别网络的一部分作为有监督任务的特征提取。熟悉卷积神经网络(CNN)的同学对此应该不会陌生,这其实就是一个反向的 CNN。
熟悉NLP 的同学可能发现了,这就很像 word2vec 里面的:king- man + woman = queen。做个向量/矩阵加减并不难,难的是把加减后得到的向量/矩阵还原成「图义」上代表的图片。在 NLP 中,word2vec 是把向量对应到有意义的词。在这里,DCGAN 是把矩阵对应到有意义的图片。即:戴墨镜的男人 - 不戴墨镜的男人 + 不戴墨镜的女人= 戴墨镜的女人

在样本生成这一过程,生成对抗网络实现这些需要多久?

Odena等人在2016年提出了Auxiliary Classifier GANs(AC-GANs),
文章标题:Conditional Image Synthesis with Auxiliary Classifier GANs
网址链接:https://arxiv.org/abs/1610.09585
主要提出AC-GAN模型,在D又新加了分类器,在输出样本真假的同时输出类别,在D的输出部分添加一个辅助的分类器来提高条件GAN的性能。针对任务,提出这种新的Inception Accuracy的评价方法,并引入了MS-SSIM用于判断模型生成图片的多样性。
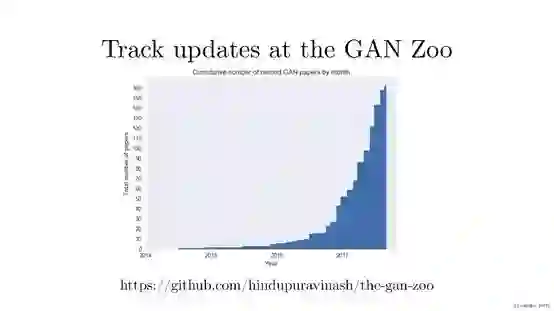
这是Github上的关于Gan方法的相关list
https://github.com/hindupuravinash/the-gan-zoo
我们能看到每周都会有新的GAN论文出来,很难跟踪所有的文章,更不用说研究人员使用一些令人难以置信的创造性的方式来命名这些生成对抗性网络!由这个图,我们知道这两年特别是2017年相关GAN命名的文章增长很迅速。

这个报告结束了,这次主要是宏观层面介绍了GAN的一些应用,以及最新的一些方法。
Ian Goodfellow《生成对抗网络(Generative Adversarial Networks)》演讲PPT下载
链接: https://pan.baidu.com/s/1qY5bHGK
AI科技大本营目前招聘资深AI采编。AI时代,和我们一起做最贴近AI的媒体!详细职位要求和简历投递方式请见☟☟☟(向下滑动详情)。
要求:
1.熟悉AI领域,对大公司、AI大牛的动态有极强敏感性,且有深度剖析的楞劲儿。
2.英语能力六级以上,看得懂文章,做得了编译,听得懂外文,做得了采访。
3.对AI相关的技术有一定的理解,能追踪最新的技术热点。
4.写稿、编译速度快,快速成稿能力非常重要。
5.语言能力强,行文流畅,写作风格不僵化不生硬。
6.相关媒体经验2年以上。
7.有过重磅深度稿件者优先。
8.对自己极高的要求,工作有极大热情,对成长有极强的动力。
9.时刻保持谦虚,能随时调整状态,跟团队目标紧密配合。
有意者,请将简历投至puge@ai100.ai,标题注明:姓名+手机号+AI采编。有疑问请加微信greta1314。

☞点击阅读原文,查看详细课程信息。



