图文并茂带你了解成分句法分析
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要7分钟
跟随小博主,每天进步一丢丢



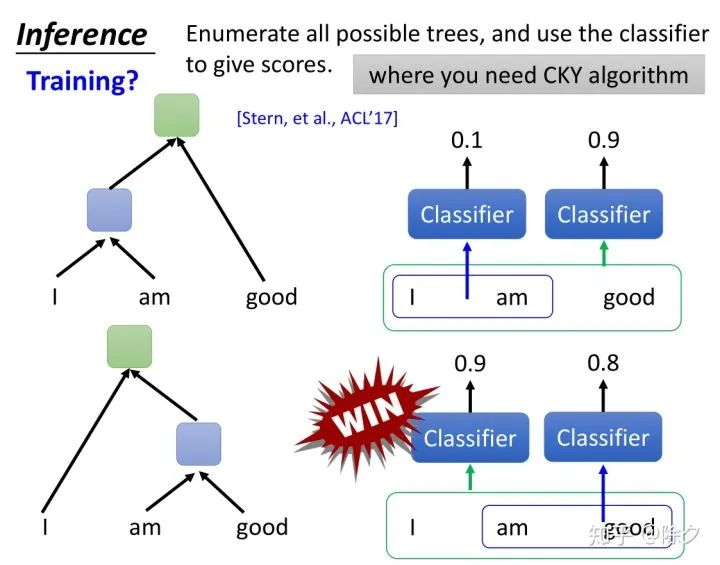

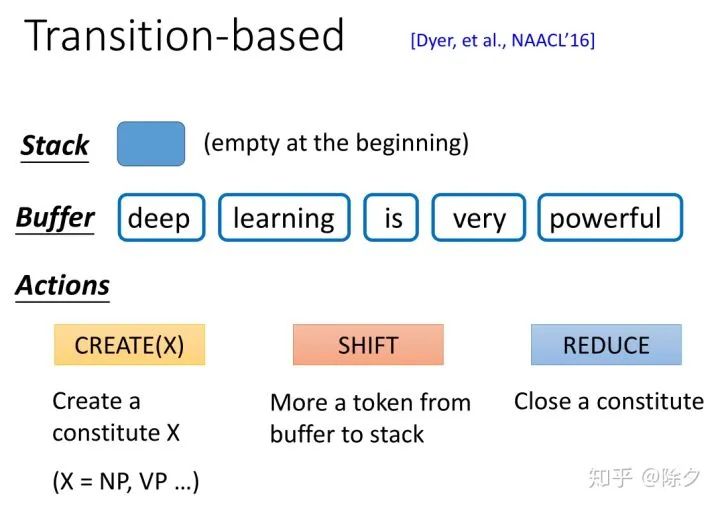
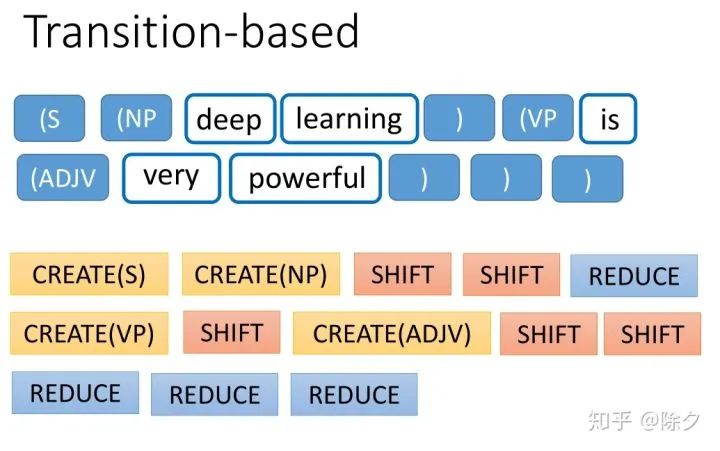
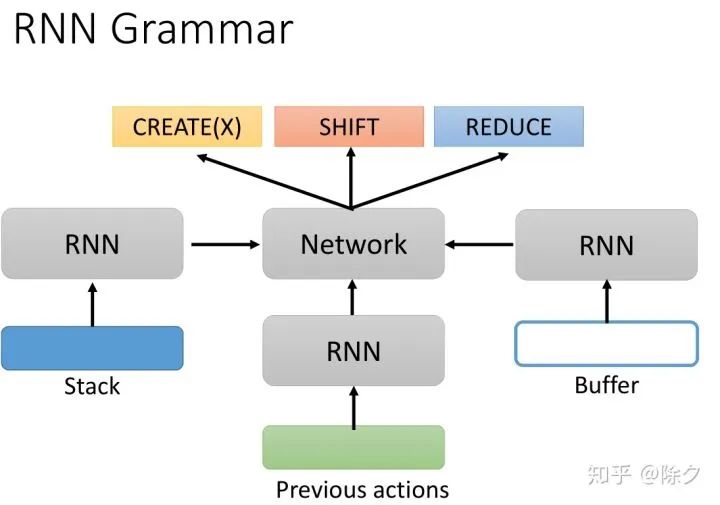



登录查看更多
相关内容

Arxiv
10+阅读 · 2019年9月5日
Arxiv
6+阅读 · 2019年8月21日
Arxiv
4+阅读 · 2017年11月27日




相关VIP内容
相关资讯
相关论文
Arxiv
10+阅读 · 2019年9月5日
Arxiv
6+阅读 · 2019年8月21日
Arxiv
4+阅读 · 2017年11月27日