简单聊聊压缩网络
秋雨伴随着寒风冰冷的飘落,告知大家初冬已经离我们不远!虽然今夜不能欣赏圆月和家人团聚,但是我们的心永远在一起。在此,也衷心祝福大家中秋节快乐,祝愿大家心想事成,万事如意!
今天主要和大家分享的是比较火热的话题——压缩网络!
自从深度学习(Deep Learning)开始流行,已经在很多领域有了很大的突破,尤其是AlexNet一举夺得ILSVRC 2012 ImageNet图像分类竞赛的冠军后,卷积神经网络(CNN)的热潮便席卷了整个计算机视觉领域。CNN模型火速替代了传统人工设计特征和分类器,不仅提供了一种端到端的处理方法,还大幅度地刷新了各个图像竞赛任务的精度,更甚者超越了人眼的精度(LFW人脸识别任务)。CNN模型在不断逼近计算机视觉任务的精度极限的同时,其深度和尺寸也在成倍增长。
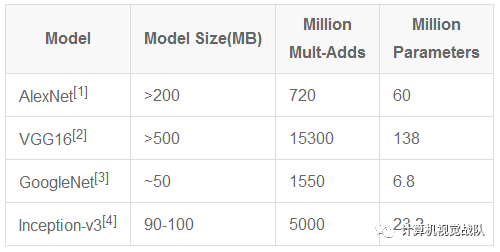
[1] ImageNet Classification with Deep Convolutional Neural Networks
[2] Very Deep Convolutional Networks for Large-Scale Image Recognition
[3] Going Deeper with Convolutions
[4] Rethinking the Inception Architecture for Computer Vision
但是这样的发展就会发生一个很尴尬的趋势,就是越来越深,越来越大的网络模型无法在生活中的移动平台上使用,根本不能实现移动设备的使用,无法将训练好的模型移植或嵌入到移动端之中。一般都通过云端传输数据或者通过网络传输,但是数据的庞大对于带宽的占有也是一个很大的问题,而且这样的设施费用特别昂贵,所以这样的实施离我们期望的还差很远。在这样的情形下,网络模型迷你化、小型化和加速成了亟待解决的问题。
其实早期就有学者提出了一系列CNN模型压缩方法,包括权值剪值(prunning)和矩阵SVD分解等,但压缩率和效率还远不能令人满意。近年来,关于模型小型化的算法从压缩角度上可以大致分为两类:从模型权重数值角度压缩和从网络架构角度压缩。另一方面,从兼顾计算速度方面,又可以划分为:仅压缩尺寸和压缩尺寸的同时提升速度。
Deep Compression
《Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding》
该文章获得了ICLR 2016的最佳论文奖,同时也具有里程碑式的意义,引领了CNN模型小型化与加速研究方向的新狂潮,使得这一领域近两年来涌现出了大量的优秀工作与文章。
算法
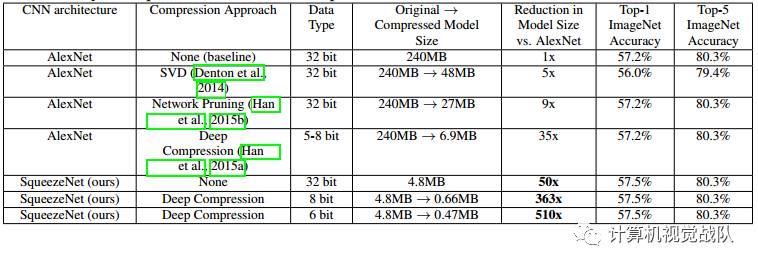
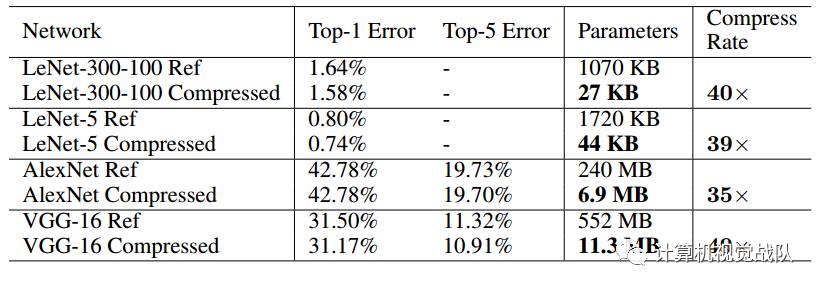
Deep Compression是属于“权值压缩派”的。该文章均出自S.Han团队,该方法与SqueezeNet结合,更是能达到极佳的压缩效果。这一实验结果如下表所示并得到了验证。
Deep Compression的算法流程包含三步,如下图所示:
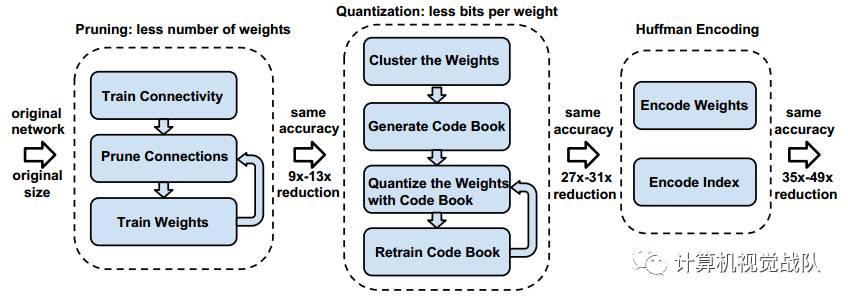
1)网络剪枝
网络剪枝已经被广泛研究于压缩CNN模型。在早期工作中,网络剪枝已经被证明可以有效地降低网络的复杂度和过拟合。如下图所示,一开始通过正常的网络训练学习连接;然后剪枝小权重的连接(即所有权值连接低于一个阈值就从网络里移除);最后再训练最后剩下权值的网络为了保持稀疏连接。剪枝减少了AlexNet和VGG-16模型的参数分别为9倍和13倍。
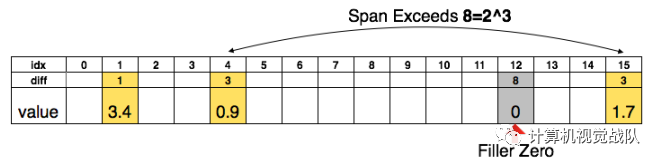
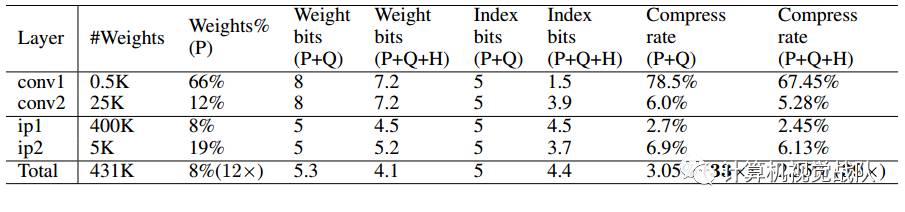
为了进一步压缩,本文存储不同索引而不是绝对的位置,然后进行编码,8 bits用于卷基层,5 bits用于全连接层。当需要的不同索引超过所需的范围,就用补零的方案解决,如图2中,索引出现8,用一个零填补。
2)Trained quantization and weight sharing
网络量化和权值共享会进一步压缩剪枝的网络,通过减少所需的bits数量去表示每一个权值。本文限制有效权值的数量,其中多个连接共享一个相同权值,并去存储,然后微调这些共享的权值。
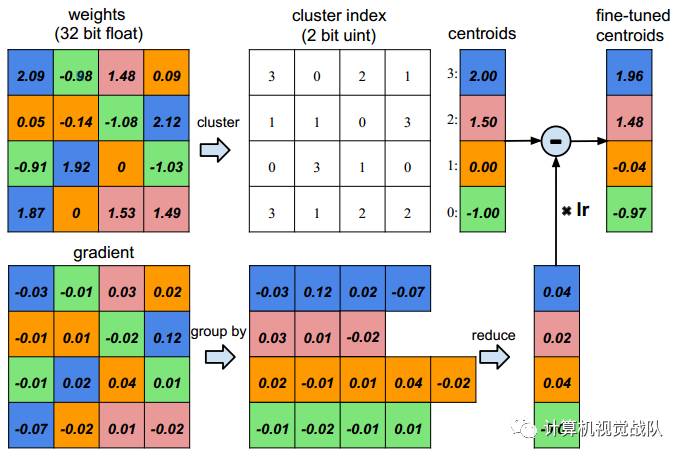
假设有4个输入神经元和4个输出神经元,权值就是一个矩阵。在上图的左上角是一个权值矩阵,在左下角是一个梯度矩阵。权值被量化到4 bits(用4种颜色表示),所有的权值在相同的通道共享着相同的值,因此对于每一个权值,只需要保存一个小的索引到一个共享权值表中。在更新过程中,所有的梯度被分组,相同的颜色求和,再与学习率相乘,最后迭代的时候用共享的质心减去该值。
为了计算压缩率,给出个簇,本文只需要 bits去编码索引,通常对于一个神经网络有个连接且每个连接用 bits表达,限制连接只是用个连接共享权值将会导致一个压缩率:
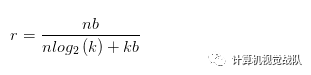
例如在上图中,有一个的初始权值,但只有4个共享权值。原始的需要存储16个权值,每个需要32bits,现在只需要存储4个有效权值(蓝色,绿色,红色和橙色),每个有32bits,一共有16个2-bits索引,得到的压缩率为16*32/(4*32+2*16)=3.2。
模型存储
前述的剪枝和量化都是为了实现模型的更紧致的压缩,以实现减小模型尺寸的目的。
对于剪枝后的模型,由于每层大量参数为0,后续只需将非零值及其下标进行存储,文章中采用CSR(Compressed Sparse Row)来进行存储,这一步可以实现9x~13x的压缩率。
对于量化后的模型,每个权值都由其聚类中心表示(对于卷积层,聚类中心设为256个,对于全连接层,聚类中心设为32个),因此可以构造对应的码书和下标,大大减少了需要存储的数据量,此步能实现约3x的压缩率。
最后对上述压缩后的模型进一步采用变长霍夫曼编码,实现约1x的压缩率。
实验结果
MobileNet
MobileNet是由Google提出的针对移动端部署的轻量级网络架构。考虑到移动端计算资源受限以及速度要求严苛,MobileNet引入了传统网络中原先采用的group思想,即限制滤波器的卷积计算只针对特定的group中的输入,从而大大降低了卷积计算量,提升了移动端前向计算的速度。
卷积分解
MobileNet借鉴factorized convolution的思想,将普通卷积操作分成两部分:
Depthwise Convolution
每个卷积核滤波器只针对特定的输入通道进行卷积操作,如下图所示,其中M是输入通道数,DK是卷积核尺寸:
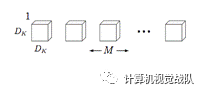
Depthwise convolution的计算复杂度为 DKDKMDFDF,其中DF是卷积层输出的特征图的大小。
Pointwise Convolution
采用1x1大小的卷积核将depthwise convolution层的多通道输出进行结合,如下图,其中N是输出通道数:
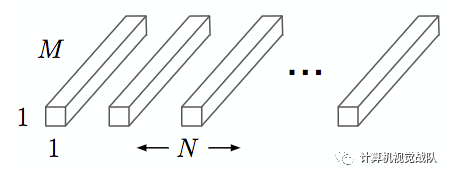
Pointwise Convolution的计算复杂度为 MNDFDF。上面两步合称depthwise separable convolution。标准卷积操作的计算复杂度为DKDKMNDFDF。因此,通过将标准卷积分解成两层卷积操作,可以计算出理论上的计算效率提升比例:
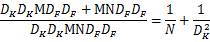
对于3x3尺寸的卷积核来说,depthwise separable convolution在理论上能带来约8~9倍的效率提升。
模型架构
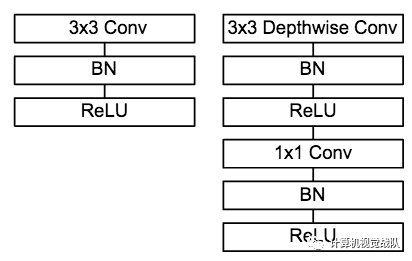
MobileNet的卷积单元如上图所示,每个卷积操作后都接着一个BN操作和ReLU操作。在MobileNet中,由于3x3卷积核只应用在depthwise convolution中,因此95%的计算量都集中在pointwise convolution 中的1x1卷积中。而对于caffe等采用矩阵运算GEMM实现卷积的深度学习框架,1x1卷积无需进行im2col操作,因此可以直接利用矩阵运算加速库进行快速计算,从而提升了计算效率。
实验结果
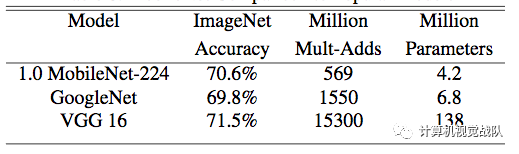
上表显示,MobileNet在保证精度不变的同时,能够有效地减少计算操作次数和参数量,使得在移动端实时前向计算成为可能。
ShuffleNet
ShuffleNet是Face++今年提出了一篇用于移动端前向部署的网络架构。ShuffleNet基于MobileNet的group思想,将卷积操作限制到特定的输入通道。而与之不同的是,ShuffleNet将输入的group进行打散,从而保证每个卷积核的感受野能够分散到不同group的输入中,增加了模型的学习能力。
设计思想
卷积中的group操作能够大大减少卷积操作的计算次数,而这一改动带来了速度增益和性能维持在MobileNet等文章中也得到了验证。然而group操作所带来的另一个问题是:特定的滤波器仅对特定通道的输入进行作用,这就阻碍了通道之间的信息流传递,group数量越多,可以编码的信息就越丰富,但每个group的输入通道数量减少,因此可能造成单个卷积滤波器的退化,在一定程度上削弱了网络了表达能力。
网络架构
在此篇工作中,网络架构的设计主要有以下几个创新点:
提出了一个类似于ResNet的BottleNeck单元
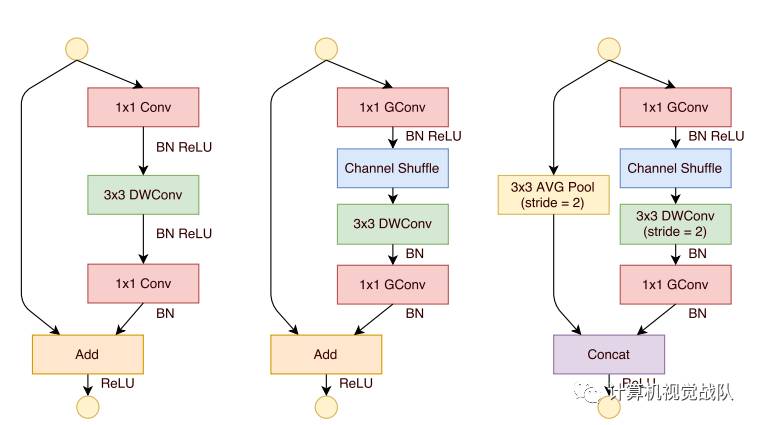
借鉴ResNet的旁路分支思想,ShuffleNet也引入了类似的网络单元。不同的是,在stride=2的单元中,用concat操作代替了add操作,用average pooling代替了1x1stride=2的卷积操作,有效地减少了计算量和参数。单元结构如图10所示。
提出将1x1卷积采用group操作会得到更好的分类性能
在MobileNet中提过,1x1卷积的操作占据了约95%的计算量,所以作者将1x1也更改为group卷积,使得相比MobileNet的计算量大大减少。
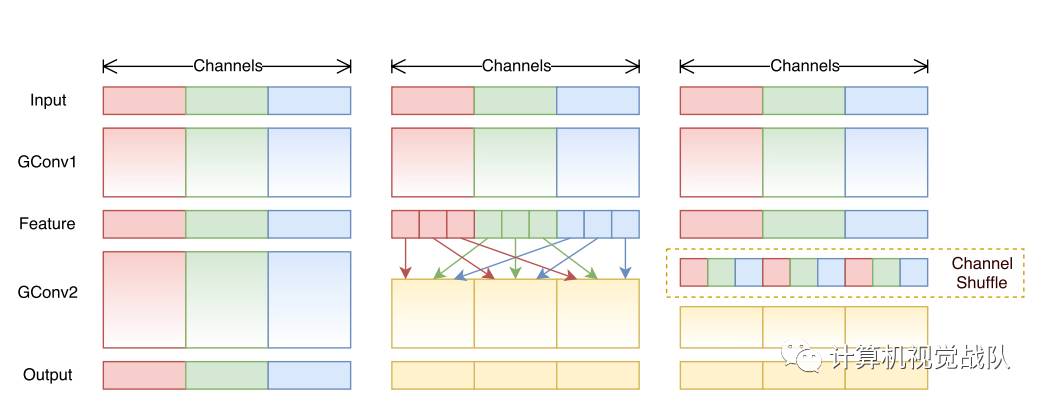
提出了核心的shuffle操作将不同group中的通道进行打散,从而保证不同输入通道之间的信息传递。
ShuffleNet的shuffle操作如下图所示。
实验结果
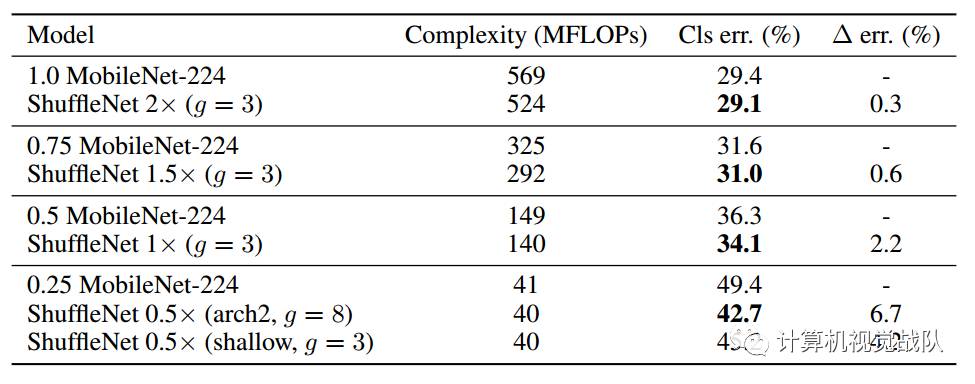
上表显示,相对于MobileNet,ShuffleNet的前向计算量不仅有效地得到了减少,而且分类错误率也有明显提升,验证了网络的可行性。
速度考量
作者在ARM平台上对网络效率进行了验证,鉴于内存读取和线程调度等因素,作者发现理论上4x的速度提升对应实际部署中约2.6x。作者给出了与原始AlexNet的速度对比,如下表。

结束语(总结)
一、网络修剪
网络修剪,采用当网络权重非常小的时候(小于某个设定的阈值),把它置0,就像二值网络一般;然后屏蔽被设置为0的权重更新,继续进行训练;以此循环,每隔训练几轮过后,继续进行修剪。
二、权重共享
对于每一层的参数,我们进行k-means聚类,进行量化,对于归属于同一个聚类中心的权重,采用共享一个权重,进行重新训练。需要注意的是这个权重共享并不是层之间的权重共享,这是对于每一层的单独共享。
三、增加L2权重
增加L2权重可以让更多的权重,靠近0,这样每次修剪的比例大大增加。
四、从结构上,简化网络计算
这些需自己阅读比较多相关文献,才能设计出合理,速度更快的网络,比如引入fire module、NIN、除全连接层等一些设计思想,这边不进行具体详述。


