CVPR 2018 | 逆视觉问答任务:一种根据回答与图像想问题的模型
选自arXiv
作者:Feng Liu等人
机器之心编译
参与:李诗萌、路
一般而言,视觉问答都是输入图像和问题,并期望机器能给出合理的回答。而最近东南大学的研究者提出一种反视觉问答的模型,即给定回答与图像期待机器能提出合理的问题。他们将问题生成视为一个多模态动态推断过程,提出可以逐渐通过部分已生成问题和答案调整其注意力焦点的 iVQA 模型。
随着传统的目标检测和目标识别方法的发展,很多问题已经得到了解决,人们对于解决更具挑战性的问题的兴趣也在激增,这些问题需要计算机视觉系统更好的「理解」能力。图像描述 [31]、可视化问答 [2]、自然语言对象检索 [20] 和「可视化图灵测试」[11] 等都存在要求丰富的视觉理解、语言理解以及知识表征和推理能力的多模态 AI 挑战。随着对这些挑战的兴趣不断增加,人们开始审视能够解决这些问题的基准和模型。发现意想不到的相关性、提供找到答案的捷径的神经网络,到底是针对这些挑战取得的进展,还是只是最新的类似于聪明的汉斯 [29,30] 或波将金村 [12] 这样的矫饰结果呢?
最近对 VQA 模型和基准的分析结果显示,VQA 模型的成功很大程度上是根据所给问题中的数据集偏差和线索所做出的预测结果,这些预测结果几乎与图像内容的理解无关。例如,现有的 VQA 模型不会像人类一样在回答问题的时候「回头」看同一个地方 [6];针对不同图像的同一问题,它们给出的答案是相同的 [1];在根本没有给出图像的情况下该模型也能表现得很好 [2,17]。此外,VQA 模型的预测结果至多依赖问题的前几个单词 [1],模型的成功很大程度上取决于能否利用标签偏差 [13]。
本文采取了不同的方法,并且探索了逆 VQA 任务是否能针对多模态智能提供有趣的基准。逆 VQA(iVQA)任务是输入一组图像和答案,然后提出(输出)一个合适的适用于图像内容和答案的问题。如图 1 所示,我们推测 iVQA 是一个有趣挑战的原因如下:(i)iVQA 模型利用问题偏差比 VQA 通过回答偏差得到高分所利用的问题偏差少(问题偏差越少,就越难利用问题对答案进行分类)。(ii)与 VQA 中的问题相比,它们自己的答案在 iVQA 中提供了非常稀疏的线索。因此,在 iQVA 中,仅从答案推导问题的机会比在 QVA 中从问题推导答案更少。也就是说,iQVA 任务更依赖于对图像内容的理解。(iii)从知识表征和推理的角度看,iVQA 可以提供测试更复杂的推理策略(如反事实推理)的机会。

图 1. iVQA 任务图示:输入答案和图像,以及本论文提出的模型生成的提问排序。
尽管与 VQA 密切相关,但现有的 VQA 模型无法解决 iVQA 问题。这是因为从答案中得到的可参考信息比从问题中得到的更少。此外,虽然答案一般都是由短语或几个单词组成的短句子,但是 iVQA 模型生成的问题应该是由较长单词序列组成的完整句子。iVQA 的关键在于,随着下一个单词的产生,模型有选择地、动态地参与图像的不同区域。这种动态的注意力机制必须以回答和已经生成的部分句子为条件。为此,研究者提出了一种基于动态多模态注意力的新 iVQA 模型,这种模型可以生成不同的、语法正确且内容相关的的问题,这些问题都能匹配所输入的答案。
之前主要使用标准机器翻译指标评估问题生成方法,例如 BLEU、METEOR 等。这些自动指标与人类对问题生成的判断相关,但它们只能从这些模型成功或失败的条件和原因等角度来简单地判断问题生成模型。本文第一次提出具有替代性和互补性的基于排名的评价指标,给定图像和答案,该指标基于 iVQA 模型对替代干扰项中的标注问题进行排序。当使用这种模型时,通过控制干扰项可以更好地理解不同模型的成功和失败。其次,本论文对 iVQA 一对多的性质进行了人工评估,即多个可能的问题都有一样的答案。令人欣慰的是,人工评估的得分与我们提出的新的排序指标是高度相关的。
本文的贡献如下:(1)为高等多模态视觉语言理解的挑战引入新颖的 iVQA 问题。(2)提出了基于 iVQA 模型的多模态动态注意力机制。(3)针对 iVQA 提出了基于问题排序的评估方法论,这有助于判断不同模型的长处和短处。(4)作为 VQA 模型的对偶问题,本文表明 iVQA 有助于提升 VQA 的性能。
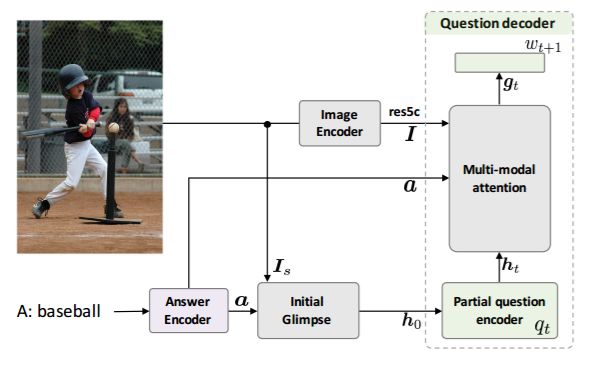
图 2:iVQA 模型的整体架构
iVQA 模型的架构如图 2 所示。这个深度网络有三个子网络:一个图像编码器、一个答案编码器以及一个问题解码器。这两个编码器为解码器提供输入以产生与答案和图像内容相匹配的问句。多模态注意力模块(稍后会进行详细介绍)也是个重要的组件,该组件在给定两个编码器的输出和部分问题编码器输出的情况下,动态地引导注意图像的不同部分。

图 3:iVQA 的定性结果。括号内的数字越大,意味着置信度越高。紫色是根据注意力生成的问题,在图 5 中会进行详细说明。
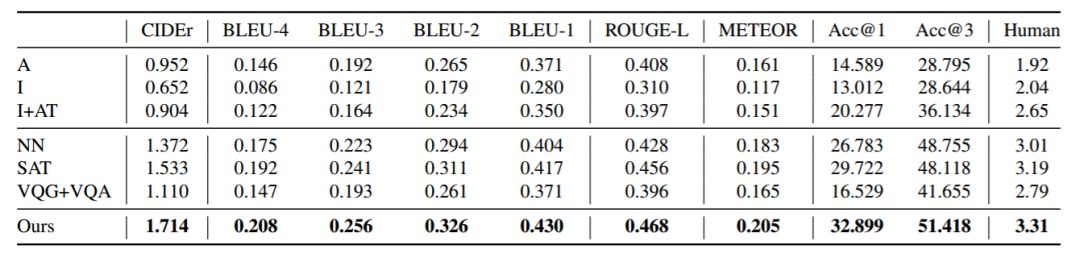
表 1:问题生成在测试集中性能的概览。
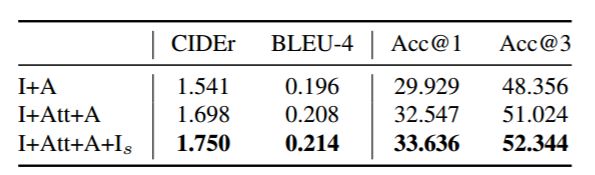
表 2:关键的模型组件在验证集上的消融研究(Ablation study)的结果。

图 5:本文所述模型产生的动态注意力图。输入答案:「领结」(顶部)、「沙发」(底部)。因为答案不同,所以在生成输出问题时,模型会生成完全不同的聚焦图。
论文:iVQA: Inverse Visual Question Answering

论文链接:https://arxiv.org/pdf/1710.03370.pdf
摘要:我们提出了视觉问答的逆问题(iVQA),并研究了将其作为视觉语言理解基准的适用性。iVQA 任务的目的是生成与所给图像和答案相关的问题。由于与问题相比答案所含信息更少,且问题可学习的偏差更少,因此与 VQA 模型相比,iVQA 模型需要更好地理解图像才能成功。本文将问题生成视为一个多模态动态推断过程,提出可以逐渐通过部分已生成问题和答案调整其注意力焦点的 iVQA 模型。在评估部分,除了现有的语言指标之外,我们提出了一个新的排序指标。该指标比较了干扰列表中真实问题的等级,这样可以对不同算法的缺点和误差来源进行研究。实验结果表明,本文提出的模型可以生成多样、语法正确、内容相关且与所给答案相匹配的问题。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




