CVPR2018 | 直接建模视觉智能体?让「小狗」动起来~
选自arXiv
作者:Kiana Ehsani 等
机器之心编译
参与:Pedro、路
近日,来自华盛顿大学和艾伦人工智能研究所的研究者在 arXiv 上发布论文,介绍了其处理计算机视觉任务的新方法:利用视觉数据直接建模视觉智能体。研究者对狗的相关动作进行建模,在多种度量方式下,对于给定视觉输入,其模型能成功地在各种环境下建模智能体。此外,该模型学得的表征能编码不同的信息,还可以泛化至其他的领域。目前,该论文已被 CVPR 2018 接收。
1. 引言
计算机视觉研究通常集中在一些特定的任务上,包括图像分类、目标识别、目标检测、图像分割等等。这些任务出现,并随着时间的推移逐渐成为视觉智能问题实际应用的典型代表。视觉智能涵盖了许多领域,很难正式地定义或评估。因此,这些代表性任务成为社区重点关注的对象。
本论文作者承认这些计算机视觉研究领域的代表性任务所带来的影响,也赞成对这些基本问题进行持续性的研究。然而,这些代表性任务的理想输出与视觉智能系统的期望功能之前仍然存在差距。这篇论文对视觉智能问题给出了直接的答案。受影响于近期关于行为与互动在视觉理解中作用的研究 [56, 3, 31],本论文研究者将视觉智能问题定义为「理解视觉数据,使得智能体能够在视觉世界中执行动作并解决问题」。在这样的定义下,研究者提出学习像这样的智能体一样在视觉世界里处理问题。
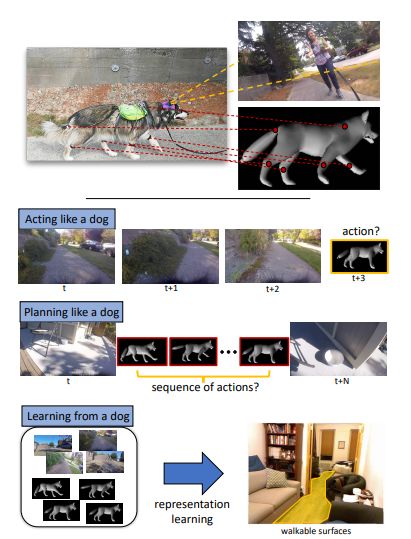
图 1. 研究者解决了三个问题:(1) 模仿狗的行为:根据给出的一系列狗之前的相关行为照片,预测狗接下来的行为动作。(2) 模仿狗的动作规划方式:目的是找出一组动作使狗能从一个给定位置移动到另一给定位置。(3) 利用关于狗的数据来学习:利用学得的知识解决这一问题(例如:预测一个可供行走的地面区域)。
通常情况下,模仿视觉智能体是一个充满挑战并且难以定义的问题。一个动作通常对应一系列包含复杂语义的运动。本论文通过将动作视为其最基本、无语义的形式——简单运动,在模仿视觉智能体方面做出了微小的贡献。
研究者将对狗建模,作为视觉智能体。狗相对人来说,有着更简单的动作空间,使研究变得相对简单。同时,它们能很好地展示视觉智能的特性,例如它们可以分辨食物、障碍、别的动物以及人类,并作出相应的反应输出。然而,它们的目的和动机通常是事先不知道的。因此研究者可以说是在建模一个黑箱。关于这个黑箱系统,我们只知道它的输入和输出。
本论文研究如何基于视觉输入学习模仿狗的行为和动作规划方式。研究者编写了一个以狗为第一人称视角的动作数据集 ( DECADE ),包括以狗为第一人称视角的视频及其对应的运动。为了记录相关的运动,研究者在狗的身体和关节处安装了惯性测量单元 (IMU)。研究者记录了这些装置的绝对位置,然后计算狗的四肢与身体之间的相对角度。
使用 DECADE 数据集,研究者探索了上面提到的三个主要问题 ( 见图 1 ):(1) 模仿狗的行为;(2) 模仿狗的动作规划方式;(3) 将狗的行为动作作为表征学习的监控信号。
在学习模仿狗的行为时,研究者通过观察狗到目前为止的观察结果来预测狗在未来可能的动作(关节屈伸)。在模仿狗的动作规划方式时,研究者解决了预测狗的系列运动动作的问题,这些动作将狗的状态从一个特定状态转变为目标状态。在利用狗作监督时,研究者发现将狗的动作用于表征学习的潜力。
结果是令人欣喜的。研究者的模型可以预测狗在各种场景下的运动(模仿狗的行为),也可以预测狗如何决定从一个状态转化为另一状态(模仿狗的动作规划方式)。除此之外,研究者还展示了根据狗的行为构建的模型也可以泛化至其他的一些任务。更重要的是,在使用狗行为模型为可行走表面预测以及场景识别等任务作预训练之后,这些任务的结果准确率都得到了提高。
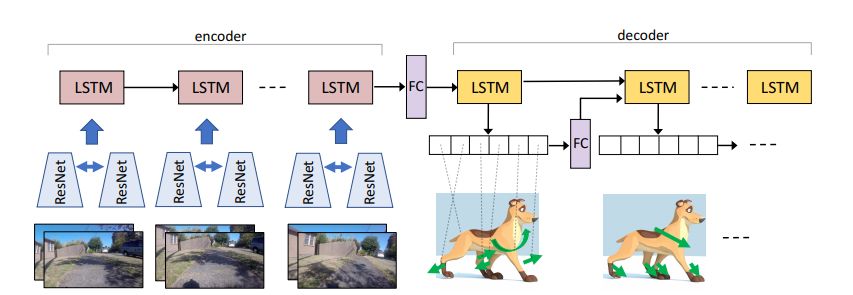
图 2. 模仿狗行为的模型架构。该模型是一个编码器-解码器神经网络。编码器接收一系列图像对,解码器输出各个关节的预测动作。编码器和解码器之间有一个全连接层(FC),以更好地捕捉相关域中的变化(从图像变为动作)。在解码器中,每一个时间步的动作输出概率会被传输至下一个时间步。两个 ResNet 塔共享权重。
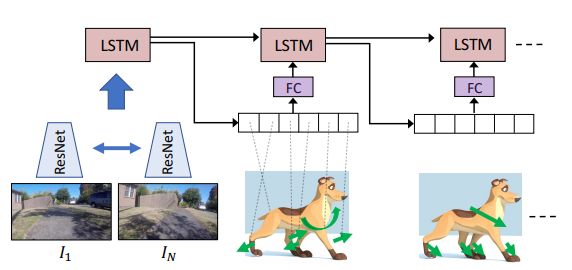
图 3. 用于模仿狗动作规划方式的模型架构。这个模型结合了 CNN 和 LSTM。模型的输入是两个图像 I_1 和 I_N,它们在视频中相差 N-1 个时间步。LSTM 接收来自 CNN 的特征数据作为输入,然后输出一组能使狗从 I_1 的状态转化为 I_N 的动作(关节屈伸)。
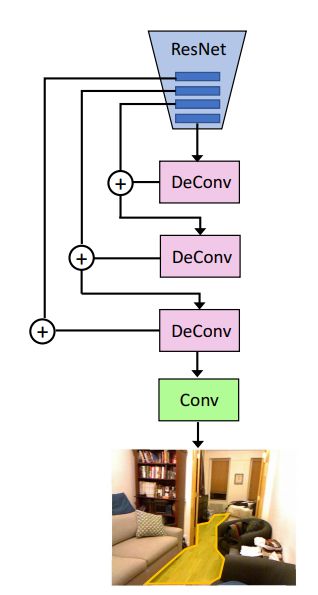
图 4. 用于预测可行走表面的模型架构。研究者使用解卷积和卷积层来增强 ResNet 的最后四层,得出可供行走的表面。

图 5. 定性结果:模型学会了如何执行动作。研究者向模型输入了一个视频的五帧,这五帧中一个男人开始向一只狗扔球。在视频中,这个球撞到墙反弹,而狗转向右边来追这个球。仅仅是使用了视频一开始的五帧,该模型就能精确地预测出狗在球飞过时如何转向右侧的。
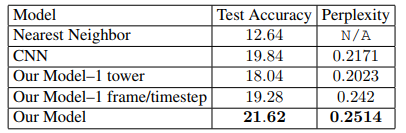
表 2. 模仿动作模型的输出结果。研究者输入了视频的前五帧然后预测接下来的五个动作。
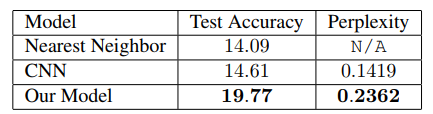
表 3. 模仿规划方式模型的输出结果。预测了从开始帧到结束帧之间的动作组。研究者认为从开始的图像转化成结束的图像需要五步。
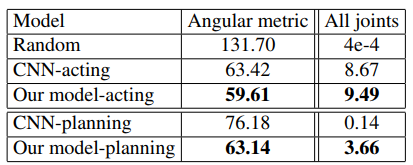
图 4. 对模型效果的评估。第一列(Angular metric)当中的数值越小越好。第二列(All joints)当中数值越大越好。
论文:Who Let The Dogs Out? Modeling Dog Behavior From Visual Data

论文链接:https://arxiv.org/abs/1803.10827
摘要:我们研究了如何直接建模一个视觉智能体。计算机视觉通常专注于解决各种与视觉智能相关的子任务。我们偏离了处理计算机视觉任务的标准方法,直接对视觉智能体进行建模。我们的模型将视觉信息作为输入并直接预测视觉智能体的动作。为了达成这一目标,我们引入了 DECADE,一个包含以狗为第一人称视角的视频以及相应动作的数据集。利用这样的数据集,我们可以建模狗的行为方式和动作规划方式。在多种度量方式下,对于给定视觉输入,我们能成功地在各种环境下建模智能体。此外,相比用图像分类训练出的表征学习,我们的模型学得的表征能编码不同的信息,还可以泛化至其他的领域。特别是,通过将这种对狗的建模用于表征学习,我们在可行走表面预测和场景分类任务中得到了非常好的结果。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com





