COLING 2022 | Pro-KD:循序渐进的平滑知识蒸馏

©PaperWeekly 原创 · 作者 | werge
研究方向 | 自然语言处理

Overview
随着神经模型规模的不断扩大,知识蒸馏作为模型压缩的重要工具收到越来越多的关注。知识蒸馏在一般的分类交叉熵以外加入一个额外的损失项,来鼓励学生模型模仿教师模型的 soft target 输出。相较于 ground-truth 标签,前者能提供更多的概率分布信息,从而提供更多的知识给学生模型。
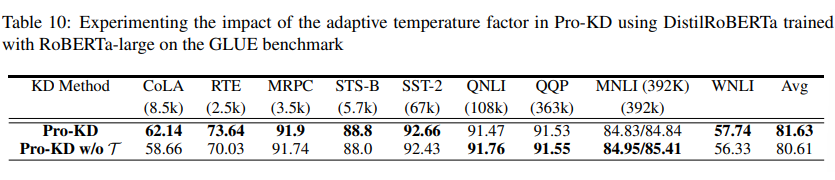
1. 检查点搜索问题:表现最好的教师模型 checkpoint 不一定是最适合蒸馏的教师,early-stopped checkpoint 没准反而是更好的教师模型。但搜索全部 checkpoint 非常耗时耗力,很难获取到最优的 checkpoint;下表展示了 BERT 系模型在不同数据集上的最优 checkpoint:
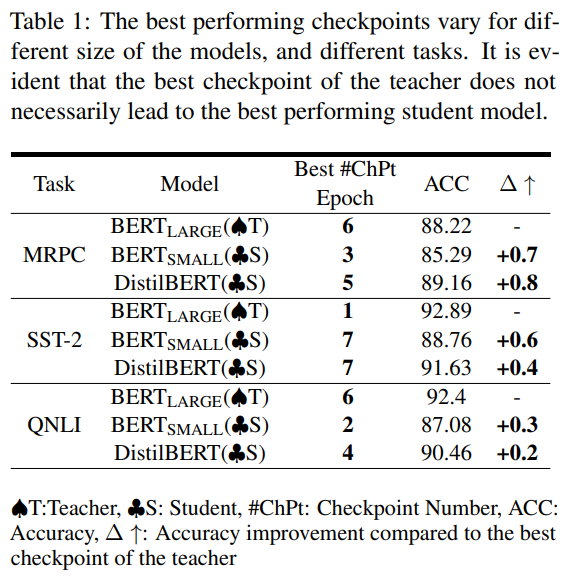
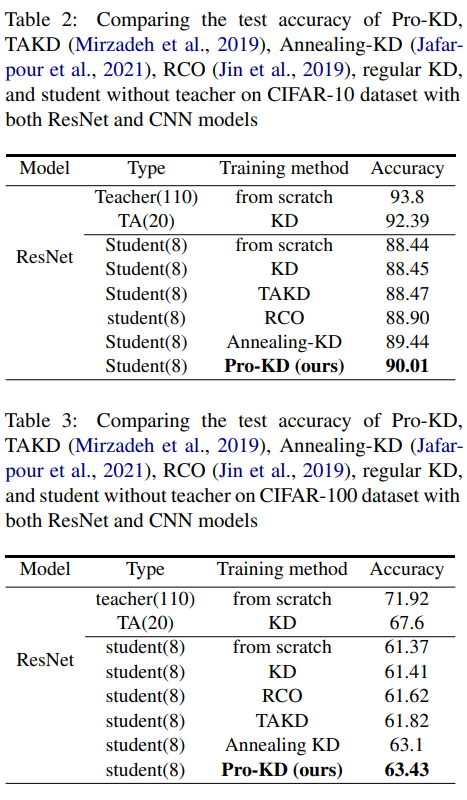
作者通过对 NLP(GLUE 基准和 SQuAD 1.1 和 2.0)和图像分类任务(CIFAR-10、CIFAR-100)的实验,表明了 Pro-KD 的有效性。

论文标题:
Pro-KD: Progressive Distillation by Following the Footsteps of the Teacher
https://arxiv.org/abs/2110.08532
COLING 2022

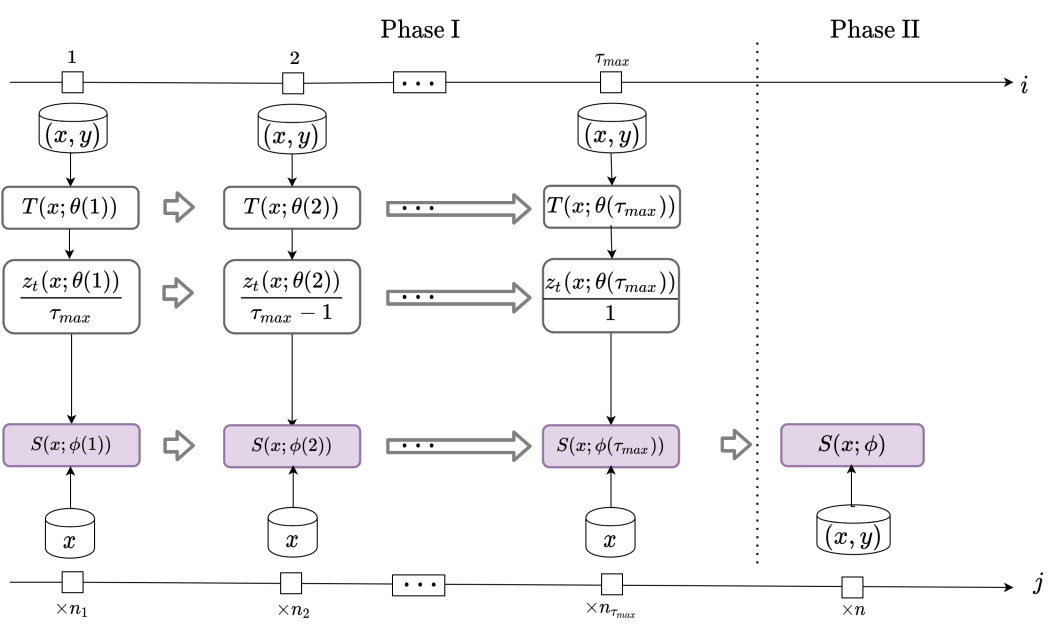
本文提出了 Pro-KD 方法,共分为两个阶段。第一阶段,学生模型仅由自适应平滑版本的教师模型监督训练;第二阶段,学生模型只接受 ground-truth 标签训练。
2.1 General Step-by-Step Training with a Teacher
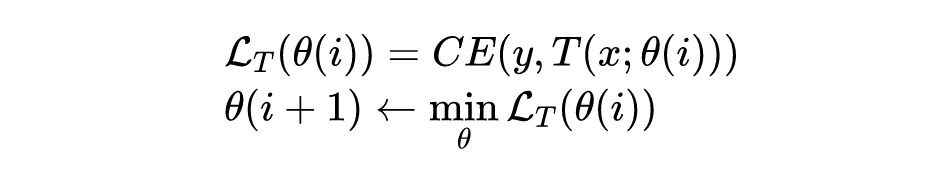
soft-label
输出,也即输出
logit
的平滑版本:
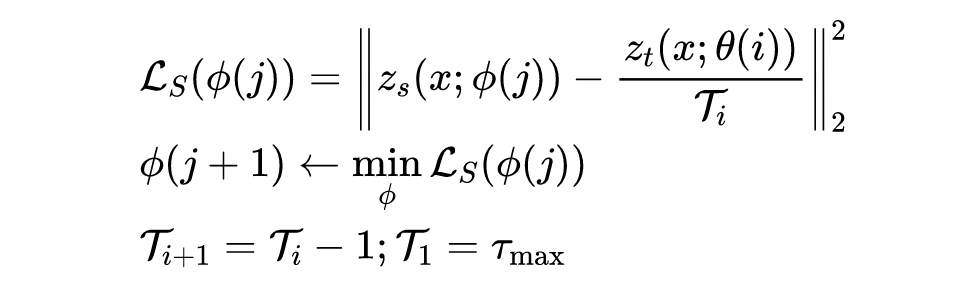
logit
,
表示学生模型第
个 epoch 的损失函数,
为当前 epoch 的温度因子。每个 epoch 减少
,直到
为止,其目的是为了让教师模型的输出更流畅,有益于缓解容量差距问题。
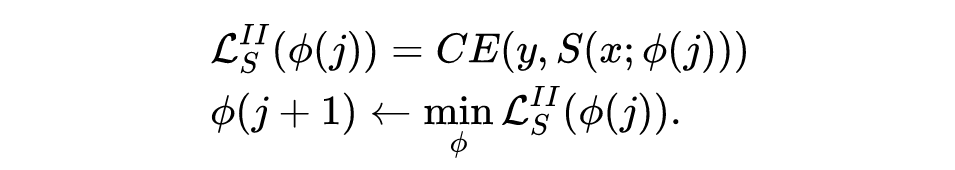
该阶段与一般的 fine-tune 训练基本相同,不再赘述。综上所述,Pro-KD 方法如下图所示。

Experiments
3.1 Setup
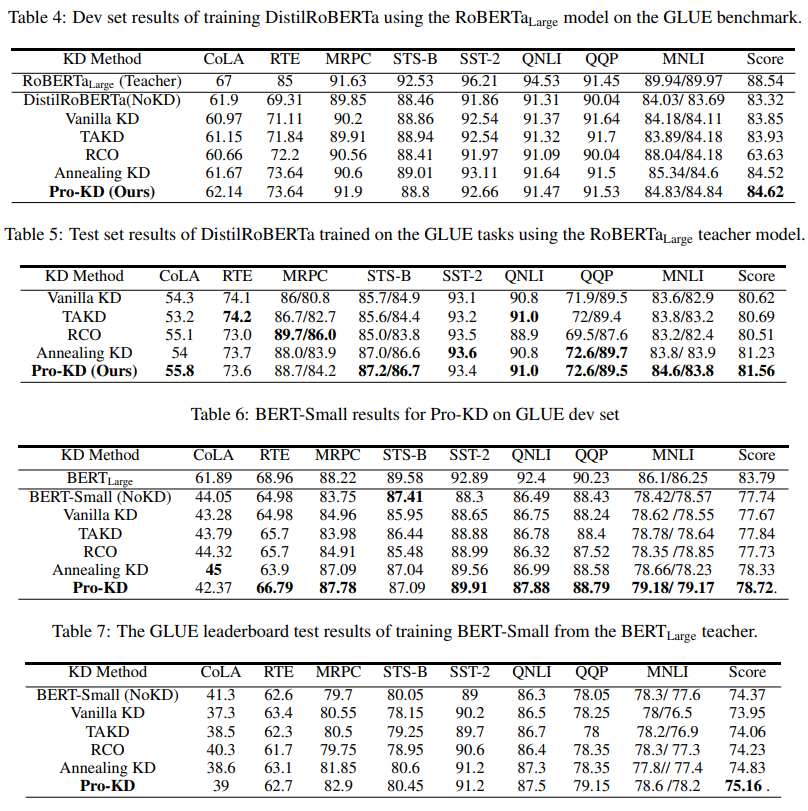
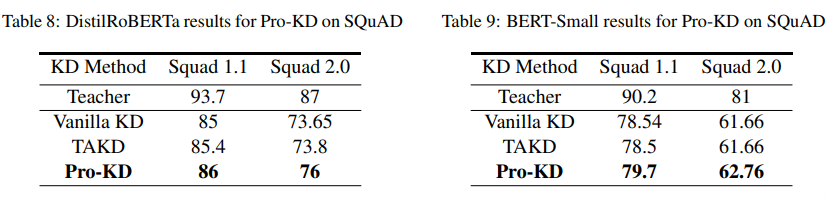
dev set
和
test set
结果。

参考文献
[1] Seyed-Iman Mirzadeh, Mehrdad Farajtabar, Ang Li, and Hassan Ghasemzadeh. 2019. Improved knowledge distillation via teacher assistant: Bridging the gap between student and teacher. arXiv preprint arXiv:1902.03393.
[2] Aref Jafari, Mehdi Rezagholizadeh, Pranav Sharma, and Ali Ghodsi. 2021. Annealing knowledge distillation. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 2493–2504, Online. Association for Computational Linguistics.
[3] Xiao Jin, Baoyun Peng, Yichao Wu, Yu Liu, Jiaheng Liu, Ding Liang, Junjie Yan, and Xiaolin Hu. 2019. Knowledge distillation via route constrained optimization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1345– 1354.
[4] Alex Krizhevsky, Geoffrey Hinton, et al. 2009. Learning multiple layers of features from tiny images
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
点击「关注」订阅我们的专栏吧


