【情感分析】基于Aspect的情感分析模型总结(二)
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要10分钟
跟随小博主,每天进步一丢丢


继续之前的ABSA之旅

Interactive Attention Networks for Aspect-Level Sentiment Classification(IJCAI2017)[1]
这篇文章作者的思路也是将target和context进行交互获取句子的准确表达,利用的模型是attention。与上面几个模型不同的在于,这里考虑了target可能存在好几个word组成的短语,另外添加了一层对于target的attention操作用于计算权重。提出了Interactive Attention Networks(IAN), 整体模型框架如下:
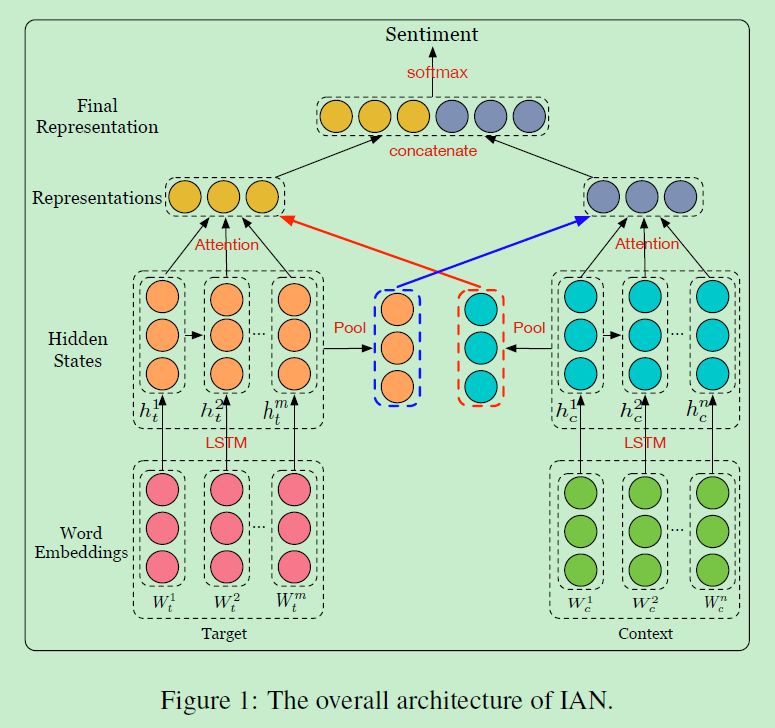
1.1 IAN
-
输入包括n个单词的 「context」: 和m个单词的 「target」 : -
对输入进行embedding层后输入到LSTM网络中得到各个隐状态表示; -
对所有隐状态求平均分别得到target和context的隐状态表示,以此作为后续attention两者的交互:
-
分别计算attention权重得分:
-
根据单词权重计算target和context的最终表示:
-
将 和 拼接起来作为整个输入句子的向量表示,并送入softmax计算类别概率
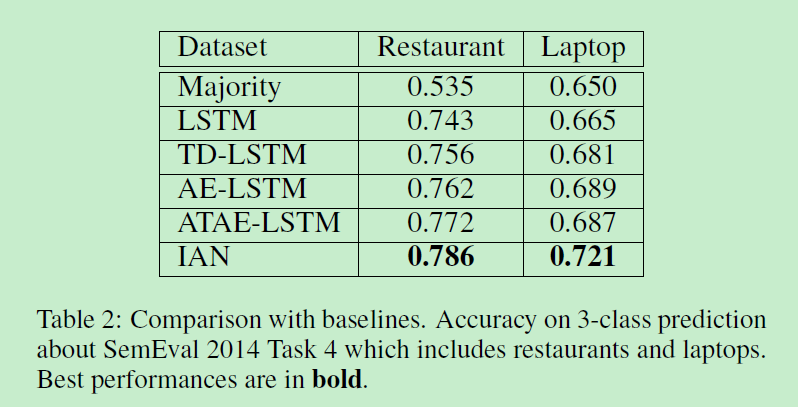
1.2 试验分析
同样数据集选用的也是SemEval 2014 Task 4,
Multi-grained Attention Network for Aspect-Level Sentiment Classification[2]
EMNLP 2018的一篇论文,作者分析了先前提出的ABSA任务模型的不足:
-
使用的attention mechanism都是属于粗粒度的(简单地求和操作),如果对于target word和context都很长的话会引入额外的损失; -
另外,先前的工作都是将aspect和context视作是单独的instance进行训练,没有考虑到具有相同上下文的instance之间的关联,而这些关联很有可能会带有额外的信息。
于是提出了一种解决ABSA问题的多粒度注意力网络(Multi-grained Attention Network, MGAN),主要的改进有:
-
「细粒度注意力机制(fine-grained attention mechanism):」 单词级别(word-level)的target和context之间的交互,可以减少粗粒度attention的损失; -
「多粒度注意力机制 (multi-grained attention network):」 粗粒度attention和细粒度attention结合; -
「aspect alignment loss:」 在目标函数中加入aspect alignment loss,以增强context相同而情感极性不同的aspect对context权重学习的差异性。
模型如下,可以分为四个部分:
-
Input embedding layer -
contextual layer -
multi-grained attention layer -
output layer
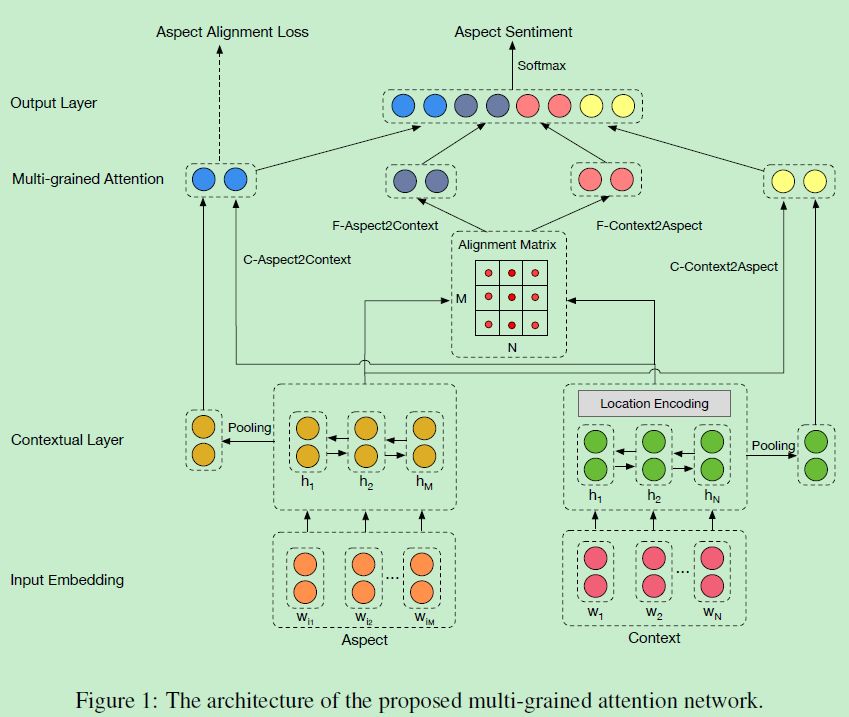
2.1 Input Embedding Layer
输入embedding层,使用的是预训练好的Glove,获得定长的aspect和context向量表示。
2.2 Contextual Layer
将上一步获得的aspect和context向量矩阵送入双向LSTM网络来捕获输入中词与词之间的关联,得到一个sentence contextual output
和aspect contextual output
。然后这里就可以把这两个矩阵进行交互了,但是作者又另外考虑了在上下文中与aspect word距离不同的word应该有不同的权重,引入了「position encoding mechanism」:context中与aspect相距为l的单词的权重
为:
「注意,aspect中的词的权重设置为0。」 于是最终得到的优化后的sentence contextual output
为
2.3 Multi-grained Attention Layer
前面的部分可以说跟之前的工作大同小异,重点在于接下来的「多粒度注意力层」。
「(1)Coarse-grained Attention」
粗粒度attention的话跟之前的attention是一样的,
-
C-Aspect2Context:对aspect矩阵Q进行求平均pool得到一个向量表示,将其与context矩阵H交互做attention, -
C-Context2Aspect:这一步是跟C-Aspect2Context对称的
「(2)Fine-grained Attention」
细粒度attention的目的是刻画aspect对context或者context对aspect词与词之间的影响关系。首先定义H和Q元素之间的相似矩阵U,注意U的形状为[N * M],U中每个元素 表示context中的第i个单词和aspect中的第j个单词之间的相似度,
-
F-Aspect2Context刻画的是对于每一个aspect word,context对其的影响程度。首先求出矩阵U中每一行最大的值,然后对其归一化操作得到和为一的权重分布后加权求和得到新的H表示
-
F-Context2Aspect刻画的是对于每一个context word,aspect对其的影响程度。首先对U中每一行做归一化操作,得到N个和为1 的权重表示,然后用N个长为M的向量去和矩阵M逐元素加权求和,最后将这N个新的表示相加取平均,得到aspect最后的细粒度表示。
24 Output Layer
在这一层将上述步骤得到的attention表示拼接起来,作为最终输入句子的向量表示并送入softmax层分析情感得分。
2.5 Loss Function
模型选用的损失函数为:
其中第一项为交叉熵损失,第二项为单独设计的aspect alignment loss,第三项为正则化项。这里需要重点说一下aspect alignment loss。该损失作用于C-Aspect2Context attention部分,C-Aspect2Context attention是用于确定与特定的aspect相关性最高context中的单词。加上了这个损失,在训练过程中模型就会通过与其他aspect比较而更加关注对自己更重要的context word。
举个栗子,在句子I like coming back to Mac OS but this laptop is lacking in speaker quality compared to my $400 old HP laptop中,通过与不同的aspect Mac OS相比,speaker quality应该更关注词语lacking,而更少关注like。
对于aspect列表中的任一对aspect 和 ,首先求出它们对context中某一特定单词的attention权重差的平方,然后乘上 和 之间的距离 :
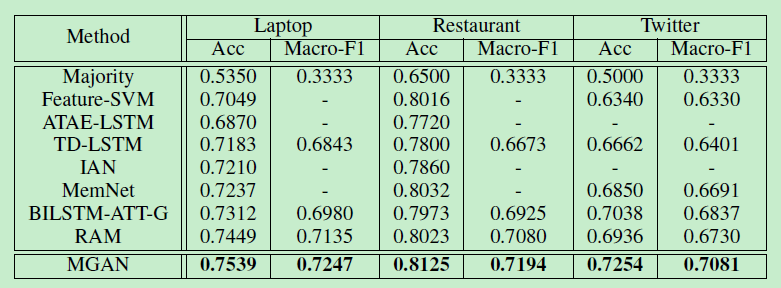
2.6 试验分析
Aspect Level Sentiment Classification with Attention-over-Attention Neural Networks[3]
这篇文章的思路好像跟上一篇很像,模型可以分为四个部分:
-
word embedding -
Bi-LSTM -
Attention-over-Attention -
Final Classification
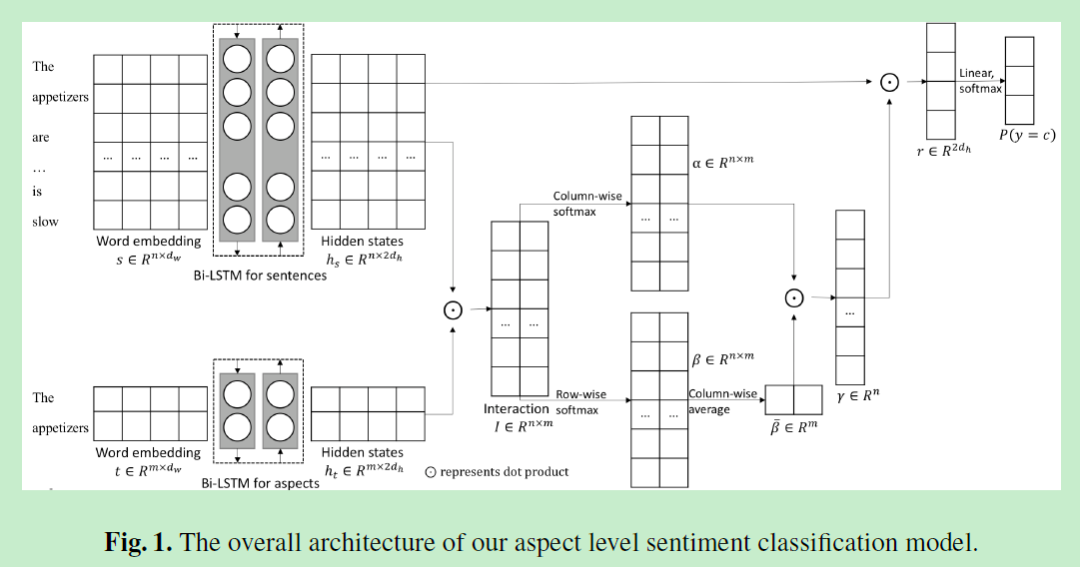
3.1 Attention-over-Attention(AOA)
定义长度为n的句子 和长度为m的target
-
经过双向LSTM得到的隐状态表示为矩阵 , , -
接着计算两者的交互矩阵 ; -
通过对交互矩阵做基于列的softmax和基于行的softmax可以得到target-to-sentence attention 和sentence-to-target attention
-
对beta向量求平均,也就获得target-level attention:
-
最后再做一次sentence层面的attention:
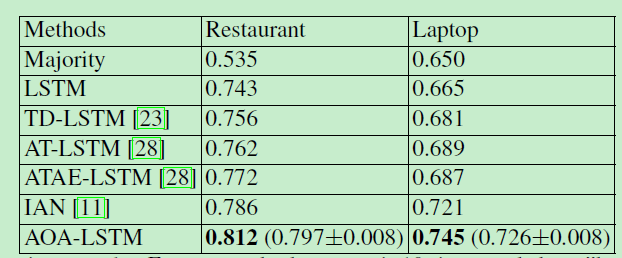
3.2 试验分析

本文参考资料
Interactive Attention Networks for Aspect-Level Sentiment Classification(Ma/IJCAI2017): https://arxiv.org/pdf/1709.00893.pdf
[2]Multi-grained Attention Network for Aspect-Level Sentiment Classification: https://www.aclweb.org/anthology/D18-1380
[3]Aspect Level Sentiment Classification with Attention-over-Attention Neural Networks: https://arxiv.org/abs/1804.06536
- END -







