情感分析词嵌入预处理细粒度实验综述(附20页全文下载)
【导读】最近,博士生Erion Çano等人更新了其撰写的最新论文《Word Embeddings for Sentiment Analysis: A Comprehensive Empirical Survey》,总结了到今年为止,在情感分析上词嵌入表示作为预处理一系列的实验分析,调研Glove和word2vec词嵌入在单词类比任务中的质量,以及四个情感分析任务:推文情感分析、歌词情感分析、电影评论情感分析和产品(电话)评论情感分析。预处理步骤也适用于其他应用,比如文本分类、文本生成等等,对词嵌入有研究的小伙伴可以详细了解其实验过程,作者也开放了几个大的预训练词向量,供感兴趣的研究人员复现。
题目:Word Embeddings for Sentiment Analysis: A Comprehensive Empirical Survey
作者:Erion Çano, Maurizio Morisio

【摘要】这项工作调研了训练方法,训练语料库大小和文本主题相关性等因素在词嵌入功能表现对推文,歌词,电影评论和项目评论等情感分析方面的作用。我们还探讨了特定的训练或后处理方法,这些方法可用于在特定任务或领域中提高词嵌入的性能。我们的经验观察表明,使用词汇量大且丰富的多主题文本进行训练的模型在回答句法和语义词汇类比问题方面是优异的。我们进一步观察到,主题相关性的影响在电影和电话评论中更为强烈,但在推文和歌词方面则较弱。这两个后面对语料库大小和训练方法更敏感,发现Glove优于Word2vec。 也发现从词典中“引入”额外的知识或生成特定于情感的词嵌入是提高词嵌入特性性能的两种显著替代方法。
参考链接:
https://arxiv.org/abs/1902.00753
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知)
后台回复“WESA2019” 就可以获取情感分析预处理词嵌入细节实验综述的下载链接~
引言
直到90年代末,主流的自然语言表示模型都是依赖于大型稀疏矩阵的离散向量空间表示。词袋(BOW)表示和特征提取方法(count vectorizer或Tf-idf)尤其流行。2003年在上提出了一种独特的见解,用连续且更密集的单词表示形式的词嵌入代替稀疏的n-gram模型。它们通过使用前馈或更高级的神经网络架构来分析在上下文窗口中一起出现的单词的共现。第一个流行的词嵌入模型是在[6]中提出的C&W(用于Collobert和Weston)。他们利用卷积神经网络(CNN)架构生成词向量,并将其用于几个著名的任务,如命名实体识别、词性标注、语义角色标注等。作者用维基百科语料库进行实验并报告每个NLP任务的显着改进,没有使用手工特征。
更高质量和更容易训练方法,如连续词袋(CBOW)和Skip-Gram,利用浅层神经网络架构来预测给定上下文窗口的单词(前者),或预测给定单词的上下文窗口(后者)。这些方法首先在[20]中提出,并在[21]中得到了相当大的改进,引入了负采样(negative sampling)和高频词的子采样。随后在[23]中提出了一种轻对数双线性学习方法。该方法使用噪声对比估计(NCE)来简化训练过程,NCE是一种通过逻辑回归分类来区分数据分布样本和噪声分布的方法。他们声称,应用于分布式词表示的NCE生成的词向量与Word2vec具有相同的质量,但只用了大约一半的时间。
在[27]中提出的Glove是近年来最流行的词嵌入生成方法之一。它利用共现矩阵中的词共现计数对文本语料库进行训练,有效利用全局语料库统计信息,同时保留了word2vec方法的线性子结构。作者提供的证据表明,Glove在较大的文本语料库中可以很好地扩展,并声称Glove在各种任务(如单词类比)中优于Word2vec和其他类似的方法。他们的实验使用的是大型文本语料库,这些语料库也被公开使用。嵌入词向量在机器翻译、纠错系统或情感分析等各种应用中有着广泛的适用性,这是因为它们具有捕捉文本词的句法和语义规律的“神奇”能力。因此,句法或语义相关的词的向量在向量空间中表现出相同的关系。
本次调研工作的范围是考察Glove和word2vec词嵌入在单词类比任务中的质量,以及四个情感分析任务:推文情感分析、歌词情感分析、电影评论情感分析和产品(电话)评论情感分析。在这里,[2]中的工作在数量和质量上都得到了扩展。更大的文本集合用于生成词嵌入,这些嵌入在更多任务上进行评估。我们特别感兴趣的是,训练方法、语料库主题或大小等因素是如何影响生成的词向量的质量的。出于这个原因,我们收集了各种预训练(使用Glove或Word2vec)和公开可用的语料库,并自己创建了不同大小、领域或内容的其他语料库。
根据我们的实验结果,单词类比任务的最佳模型是多主题、大容量、词汇量丰富的文本包。我们还观察到,训练方法和训练语料库的大小对歌词的情感分析影响较大,对推文的情感分析影响不大,对电影和电话评论的情感分析影响不大。相反,训练语料库的主题相关性对歌词的影响不显著,对推文的影响适中,对电影和电话评论的影响较大。我们还参考了相关的研究工作,试图通过后处理或改进的训练方法来提高单词嵌入的质量。我们对这两种方法进行了评估,发现它们确实在一定程度上提高了词嵌入的质量,至少在某些任务上是这样。这些结果可以作为研究人员或实践者在情感分析或类似的文本相关任务中使用词嵌入的指导原则。任何对我们训练的模型感兴趣的人都可以从http://softeng.polito.it/erion/ 下载,复现我们的实验或进行任何相关的实验。

本文的其余部分组织如下:
在第2节中,我们提出了研究问题,展示了预处理和训练步骤,并描述了我们所实验的语料库。
在第3节中,我们展示了四个情感分析任务的相关最新成果,并描述了我们在实验中使用的数据集。
第四节给出了不同模型在单词类比任务中的结果。
第5节讨论了训练方法、语料库大小和文本主题相关性等属性对模型性能的影响。
第6节提出了几个改进词嵌入质量的建议,
最后,第7节结束了我们的讨论。
附教程内容






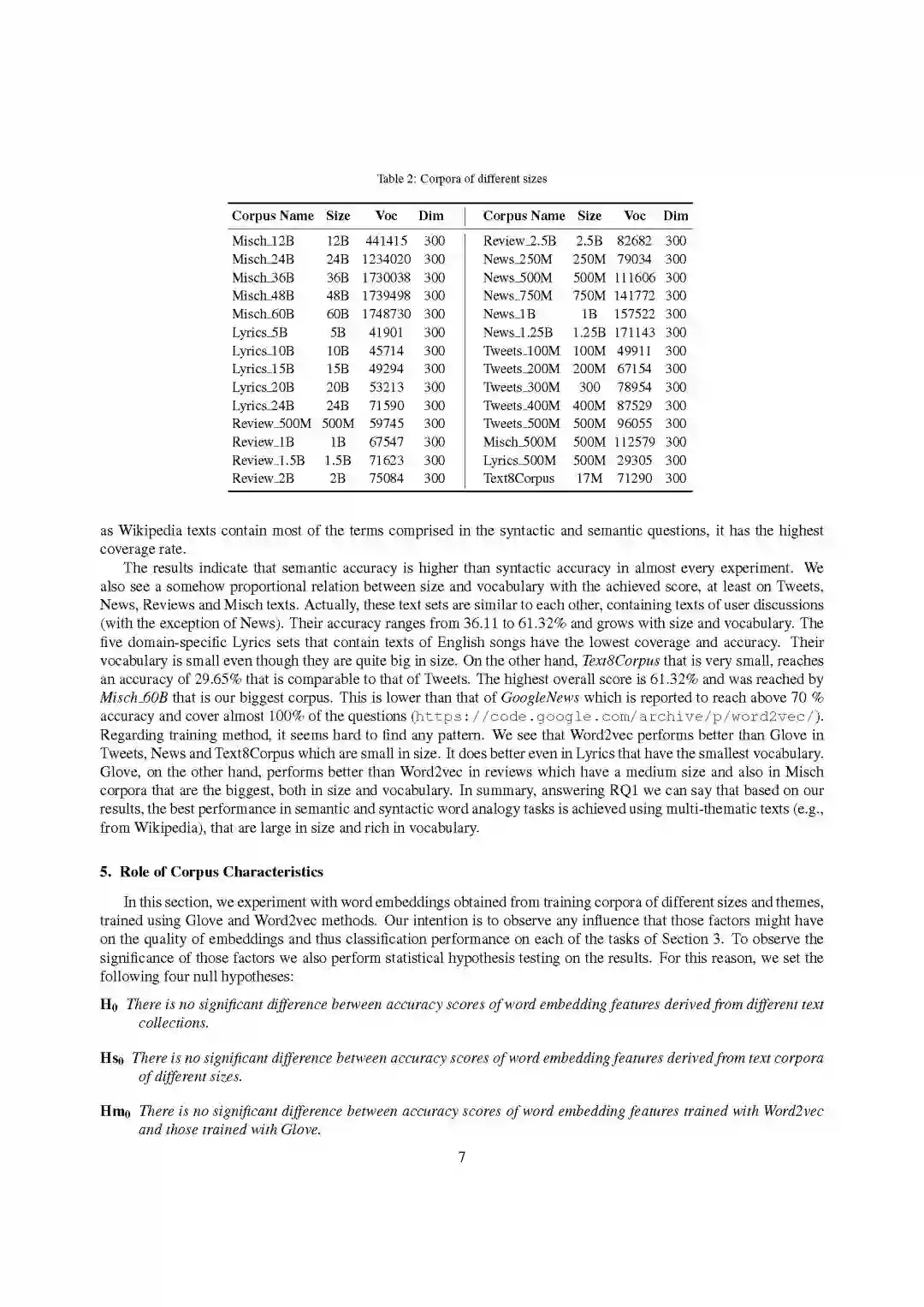
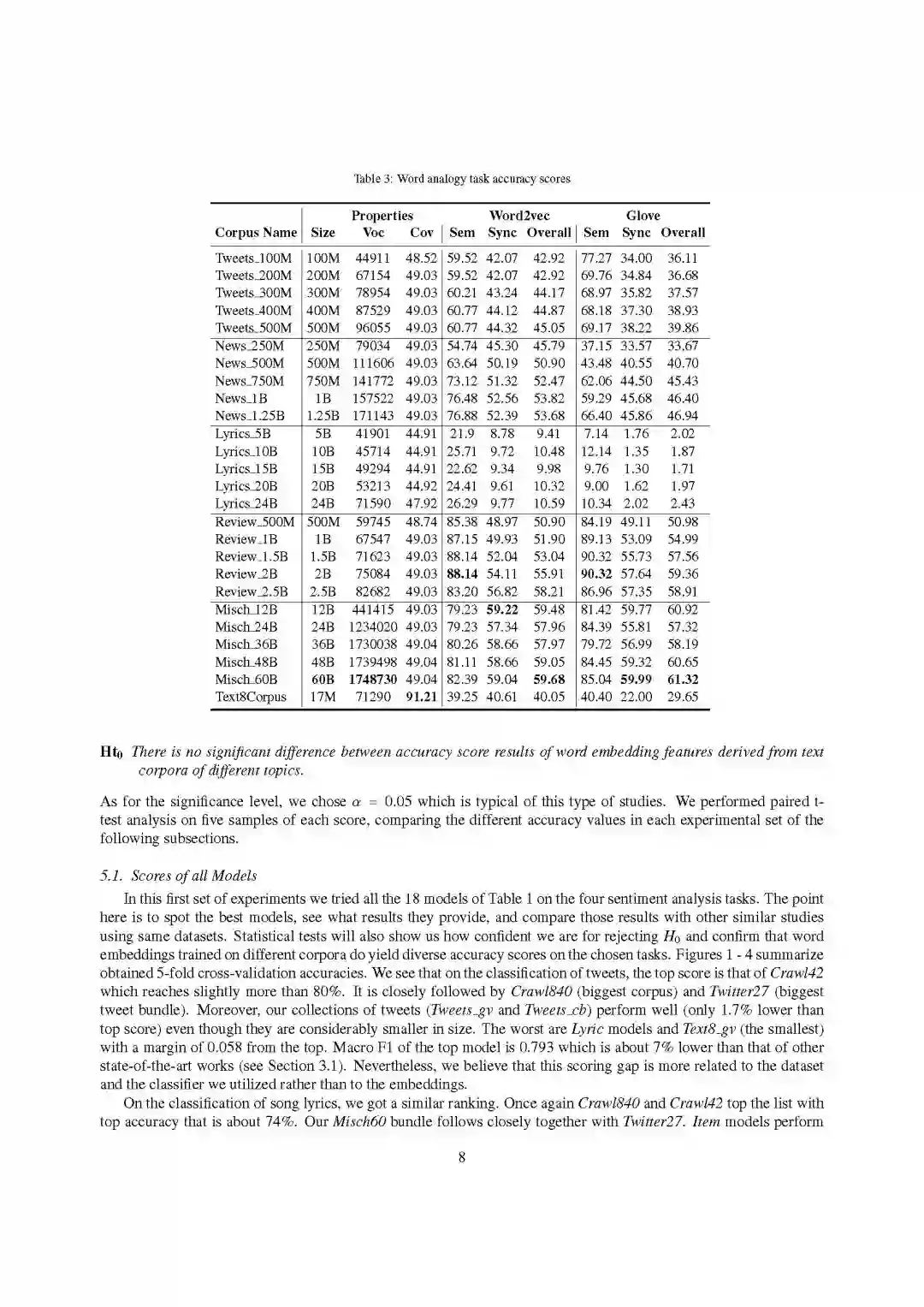
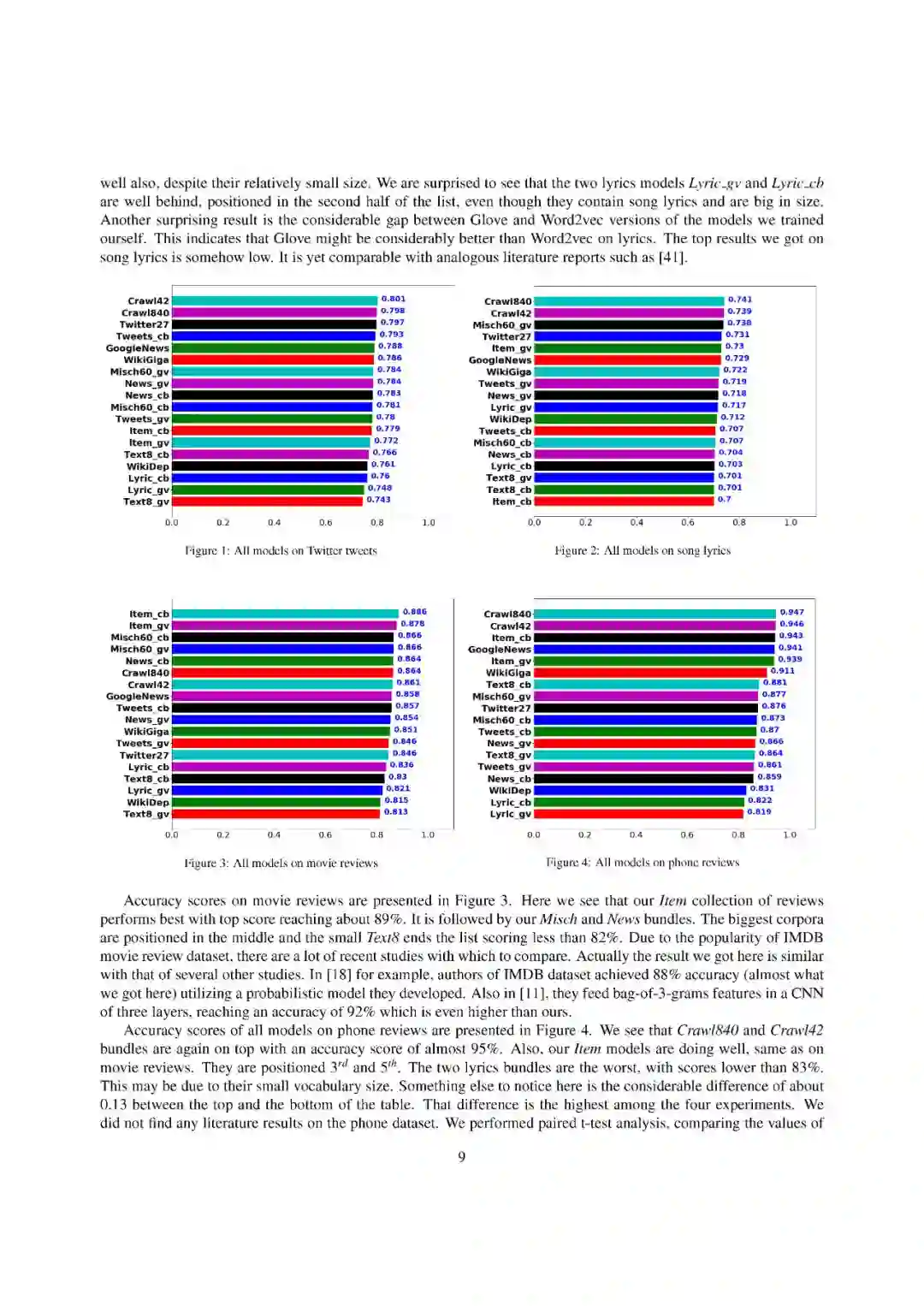


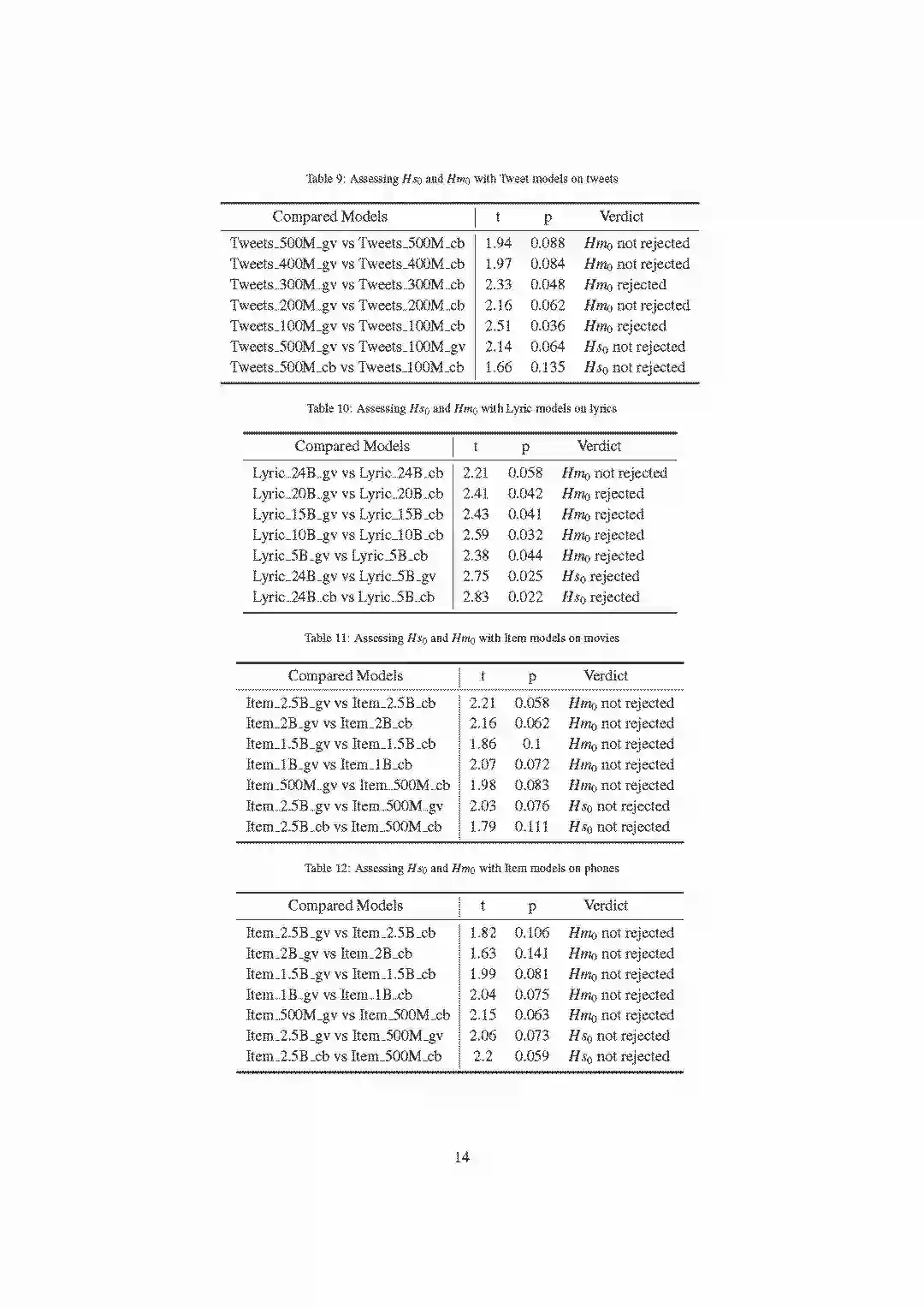



-END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!470+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

请加专知小助手微信(扫一扫如下二维码添加),咨询《深度学习:算法到实战》参团限时优惠报名~

欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程



