多伦多大学&NVIDIA最新成果:图像标注速度提升10倍!
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
本文经授权转自公众号图灵Topia(ID:turingtopia)
作者:Huan Ling等编辑:刘静
图像标注速度提升10倍!
这是多伦多大学与英伟达联合公布的一项最新研究:Curve-GCN的应用结果。
Curve-GCN是一种高效交互式图像标注方法,其性能优于Polygon-RNN++。在自动模式下运行时间为29.3ms,在交互模式下运行时间为2.6ms,比Polygon-RNN ++分别快10倍和100倍。
数据标注是人工智能产业的基础,在机器的世界里,图像与语音、视频等一样,是数据的一个种类。
对象实例分割是在图像中概括给定类的所有对象的问题,这一任务在过去几年受到了越来越多的关注,传统标记工具通常需要人工先在图片上点击光标描记物体边缘来进行标记。
然而,手动跟踪对象边界是一个费力的过程,每个对象大概需要30-60秒的时间。

为了缓解这个问题,已经提出了许多交互式图像分割技术,其通过重要因素加速注释。但是交互式分割方法大多是逐像素的(比如DEXTR),在颜色均匀的区域很难控制,所以最坏的情况下仍然需要很多点击。
Polygon-RNN将humans-in-the-loop(人机回圈)过程进行构架,在此过程中模型按顺序预测多边形的顶点。通过纠正错误的顶点,注释器可以在发生错误时进行干预。该模型通过调整校正来继续其预测。 Polygon-RNN显示在人类协议水平上产生注释,每个对象实例只需点击几下。这里最糟糕的情况是多边形顶点的数量,大多数对象的范围最多为30-40个点。
然而,模型的重复性将可扩展性限制为更复杂的形状,导致更难的训练和更长的推理。此外,期望注释器按顺序纠正错误,这在实践中通常是具有挑战性的。


最新研究成果中,研究人员将对象注释框架化为回归问题,其中所有顶点的位置被同时预测。
在Curve-GCN中,注释器会选择一个对象,然后选择多边形或样条轮廓。

Curve-GCN自动地勾勒出对象的轮廓

Curve-GCN允许交互式更正,并且可以自动重新预测多边形/样条
与Polygon-RNN + +相比:
Curve-GCN具有多边形或样条曲线参数
Curve-GCN可同时预测控制点(更快)


初始化预测
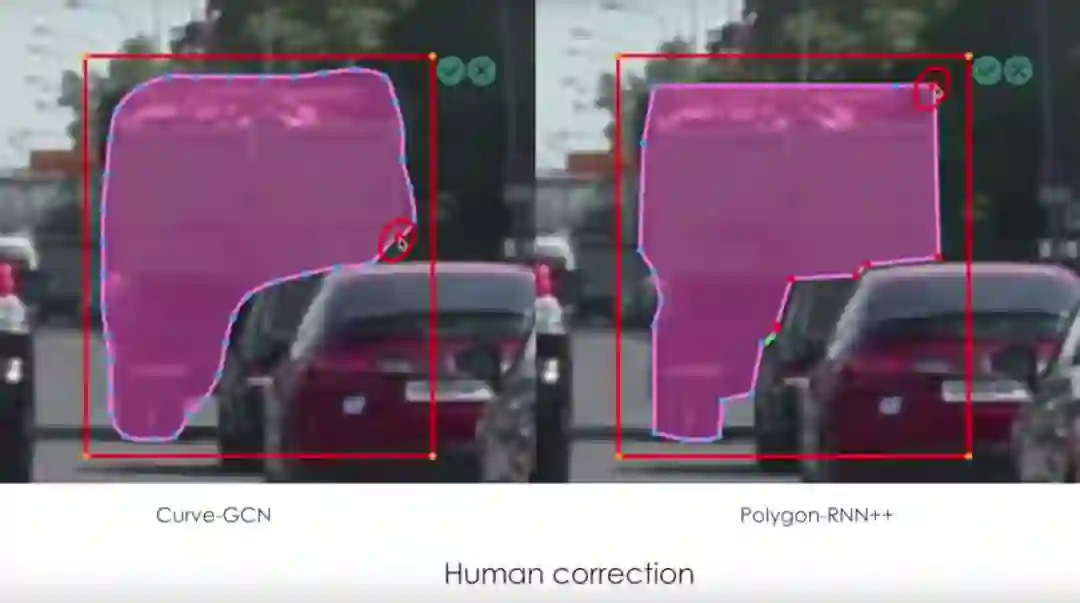
人工校正
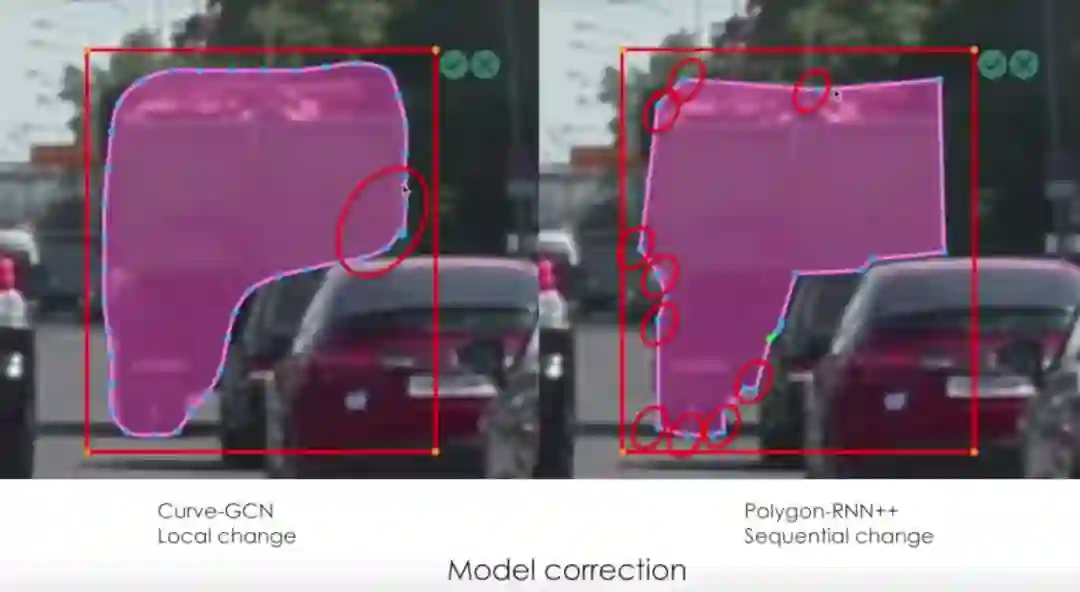
模型校正

模型是在CityScapes数据集上训练的

自动模式下的比较。从左到右:ground-truth, Polygon-GCN, Spline-GCN, ps - deeplab

跨域自动模式。(上)cityscaps训练模型的开箱即用输出,(下)使用来自新领域的10%的数据进行微调。
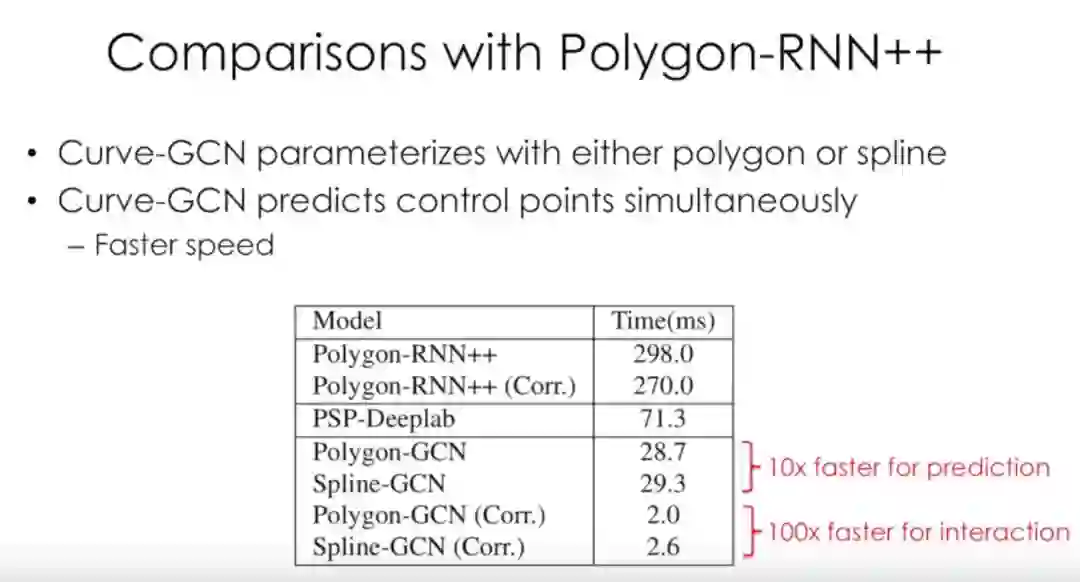

将Polygon和Spline-GCN与Polygon-RNN ++和PSP-DeepLab进行比较
模型在最先进的基础上进行了改进,速度显著加快,允许只具有局部效果的交互式更正,从而为注释器提供了更多的控制。这将导致更好的整体注释策略。
代码:
https://github.com/fidler-lab/curve-gcn
论文地址:
https://arxiv.org/abs/1903.06874
论文摘要
通过边界跟踪来手动标记对象是一个繁重的过程。在Polygon-RNN ++中,作者提出了Polygon-RNN,它使用CNN-RNN架构以循环方式产生多边形注释,允许通过humans-in-the-loop(人机回圈)的方式进行交互式校正。
我们提出了一个新的框架,通过使用图形卷积网络(GCN)同时预测所有顶点,减轻了Polygon-RNN的时序性。我们的模型是端到端训练的。它支持多边形或样条对对象进行标注,从而提高了基于线和曲线对象的标注效率。结果表明,在自动模式下,Curve-GCN的性能优于现有的所有方法,包括功能强大的PSP-DeepLab,并且在交互模式下,Curve-GCN的效率明显高于Polygon-RNN++。我们的模型在自动模式下运行29.3ms,在交互模式下运行2.6ms,比Polygon-RNN ++分别快10倍和100倍。

*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个好看啦~






