论文浅尝 | GaussianPath: 用于知识图谱推理的贝叶斯多跳推理框架

笔记整理:谭亦鸣,东南大学博士生
来源:AAAI’21
链接:https://ojs.aaai.org/index.php/AAAI/article/view/16565
多跳推理由于对下游任务例如问答和图谱补全的可解释性受到关注。多跳推理是一个典型的顺序决策过程,可表述为马尔可夫决策过程。在近年的研究中,基于强化学习的方法被证明是有效的路径推理方法之一。作者提出了一种基于贝叶斯的强化学习多跳推理框架,GaussianPath,其主要特点是考虑了推理路径的不确定性。
背景与动机
作者发现,现有方法假设实体-关系表示遵循单点分布,但事实上,不同实体与关系可能包含不同的不确定性。另一方面,作者发现这些方法里的reward具有偏见性,使得agent容易陷入高回报路径而不是宽推理路径,导致对当前信息过早和次优的利用。
贡献
作者总结论文的贡献如下:
1.提出了一个贝叶斯多条推理范式,旨在捕捉推理路径的不确定性,该方向在RL方法中较少被关注2.构建了一个可训练的贝叶斯神经网络用于逼近Q函数,该模型能够学习概念语义的不确定性,并且权衡利用和探索3.论文对现有的benchmark进行了充分的实验,结果验证了论文方法具有竞争力的性能
方法
多跳推理的不确定性建模
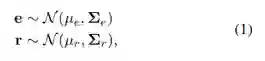
作者使用高斯分布来表示一个实体或关系,如公式1,其中,μe和μr表示平均向量,Σe, Σr表示协方差矩阵(这里作者使用对角协方差来提高计算效率)。因此,强化学习中的状态或者动作也遵循一个联合分布函数如下
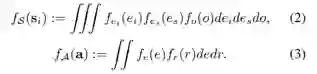
随着与环境迭代交互,agent遵循一个未知的状态-动作分布从source entity扩展到target entity。通过训练agent,高斯分布的后验将会收敛,从而减少不确定性,因此agent会变得更加确定,因此,策略π下的推理路径τ的合理性可以描述为公式4,其中F是一个依赖于 ∀e ∈ E, r ∈ R分布的马尔可夫链上的典型的贝叶斯推断。e和r的不确定性会传递给F,然后反映为预测一条推理路径的不确定性。
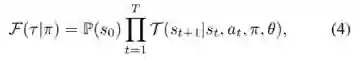
由于KG中的状态-动作组合空间过大,难以直接得到Q函数,为了逼近Q函数,作者首先使用一个BayesianLSTM将当前状态s编码为一个隐向量h,如公式7
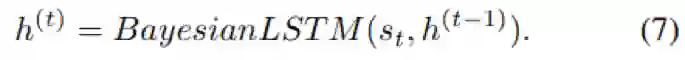
BayesianLSTM对于随机变量是可训练的,可以将概率分布作为输入,再输出概率分布。
然后作者使用了一个贝叶斯线性回归层来学习每个动作的Q-value,如公式8
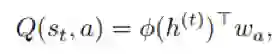
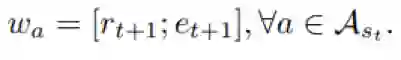
实验
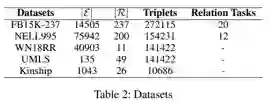
实验数据统计信息如表2所示
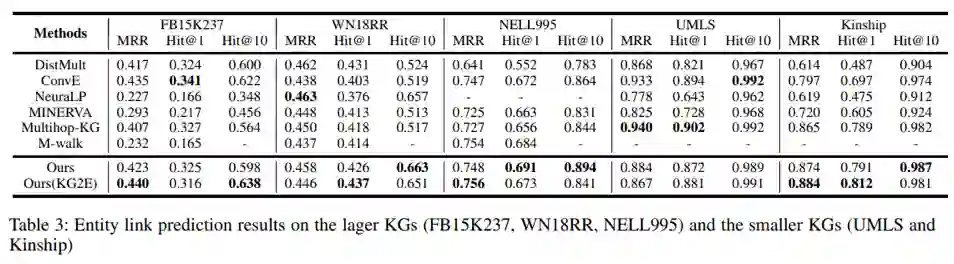
验证推理性能的任务使用的是知识图谱补全和实体链接,前者评价指标为Hit@1,10和MRR,后者评价指标则为MAP。
主要实验结果和对照组的基线模型如表所示:
首先是KG补全任务的结果
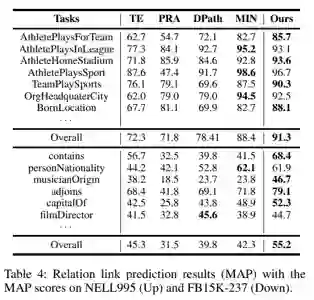
再就是链接任务的结果
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


