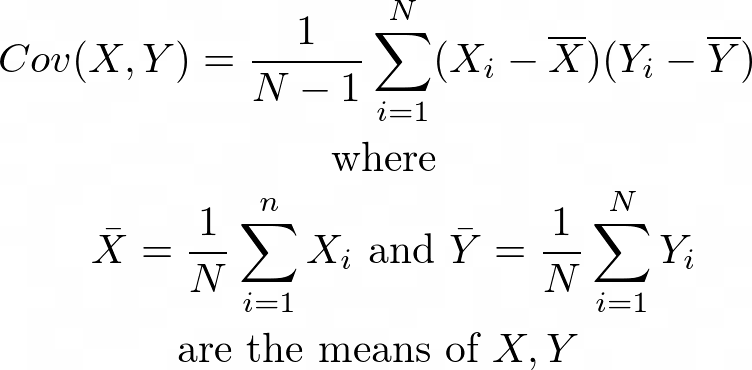作者丨Shuchen Du、ronghuaiyang(译)
卷积神经网络(CNN)
广泛应用于深度学习和计算机视觉算法中。虽然很多基于CNN的算法符合行业标准,可以嵌入到商业产品中,但是标准的CNN算法仍然有局限性,在很多方面还可以改进。这篇文章讨论了语义分割和编码器-解码器架构作为例子,阐明了其局限性,以及为什么自注意机制可以帮助缓解问题。
标准编解码结构的局限性
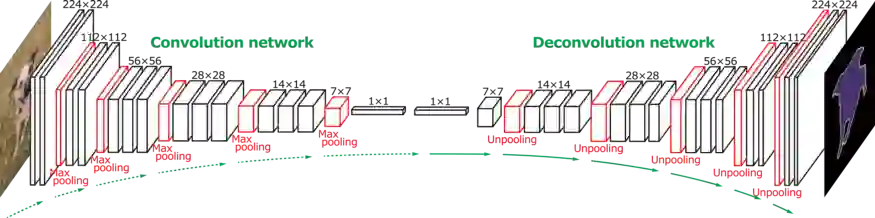
解码器架构(图1)是许多计算机视觉任务中的标准方法,特别是像素级预测任务,如语义分割、深度预测和一些与GAN相关的图像生成器。在编码器-解码器网络中,输入图像进行卷积、激活以及池化得到一个潜向量,然后恢复到与输入图像大小相同的输出图像。该架构是对称的,由精心设计的卷积块组成。由于其简单和准确,该体系结构被广泛使用。
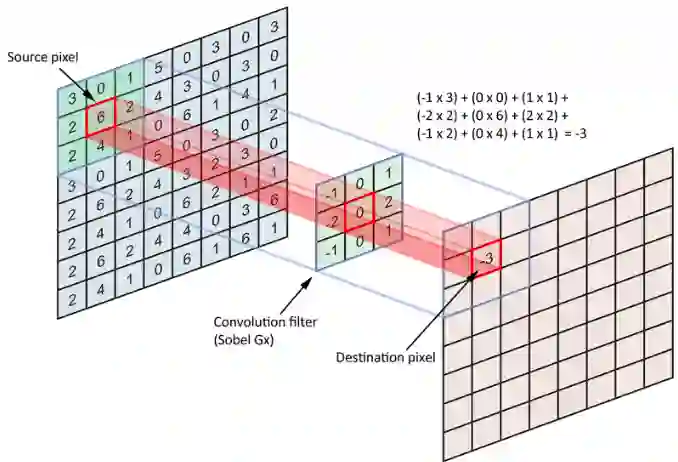
但是,如果我们深入研究卷积的计算(图2),编码器-解码器架构的局限性就会浮出表面。例如,在3x3卷积中,卷积滤波器有9个像素,目标像素的值仅参照自身和周围的8个像素计算。这意味着卷积只能利用局部信息来计算目标像素,这可能会带来一些偏差,因为看不到全局信息。也有一些朴素的方法来缓解这个问题:使用更大的卷积滤波器或有更多卷积层的更深的网络。然而,计算开销越来越大,结果并没有得到显著的改善。
理解方差和协方差
方差和协方差都是统计学和机器学习中的重要概念。它们是为随机变量定义的。顾名思义,方差描述的是单个随机变量与其均值之间的偏差,而协方差描述的是两个随机变量之间的相似性。如果两个随机变量的分布相似,它们的协方差很大。否则,它们的协方差很小。如果我们将feature map中的每个像素作为一个随机变量,计算所有像素之间的配对协方差,我们可以根据每个预测像素在图像中与其他像素之间的相似性来增强或减弱每个预测像素的值。在训练和预测时使用相似的像素,忽略不相似的像素。这种机制叫做自注意力。
CNN中的自注意力机制
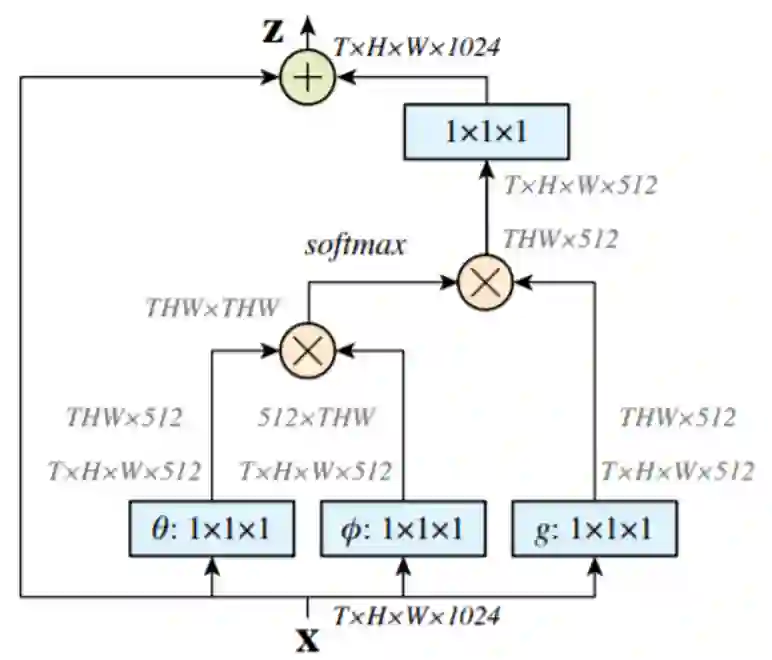
为了实现对每个像素级预测的全局参考,Wang等人在CNN中提出了自我注意机制(图3)。他们的方法是基于预测像素与其他像素之间的协方差,将每个像素视为随机变量。参与的目标像素只是所有像素值的加权和,其中的权值是每个像素与目标像素的相关。
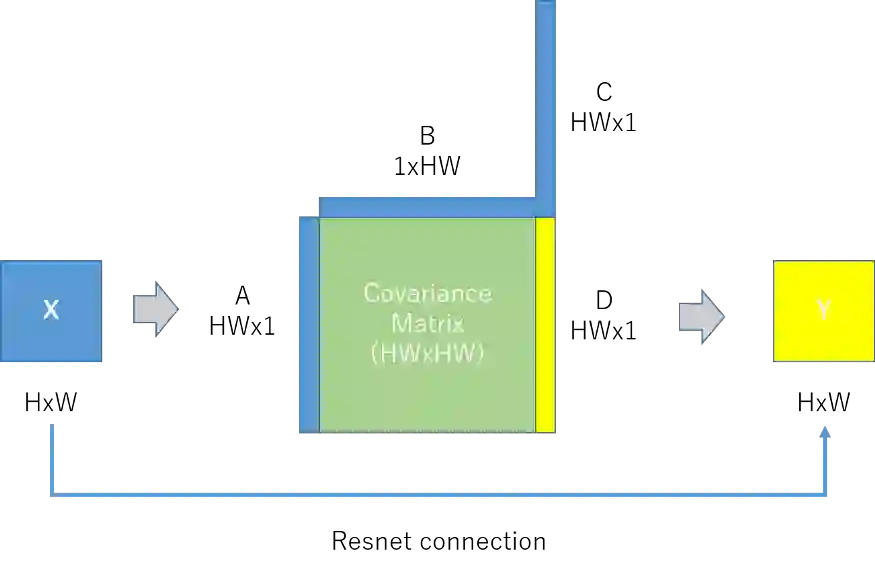
如果我们将原来的图3简化为图4,我们就可以很容易地理解协方差在机制中的作用。首先输入高度为H、宽度为w的特征图X,然后将X reshape为三个一维向量A、B和C,将A和B相乘得到大小为HWxHW的协方差矩阵。最后,我们用协方差矩阵和C相乘,得到D并对它reshape,得到输出特性图Y,并从输入X进行残差连接。这里D中的每一项都是输入X的加权和,权重是像素和彼此之间的协方差。
利用自注意力机制,可以在模型训练和预测过程中实现全局参考。该模型具有良好的bias-variance权衡,因而更加合理。
深度学习的一个可解释性方法
SAGAN将自注意力机制嵌入GAN框架中。它可以通过全局参考而不是局部区域来生成图像。在图5中,每一行的左侧图像用颜色表示采样的查询点,其余五幅图像为每个查询点对应的关注区域。我们可以看到,对于天空和芦苇灌木这样的背景查询点,关注区域范围广泛,而对于熊眼和鸟腿这样的前景点,关注区域局部集中。
参考资料
Non-local Neural Networks, Wang et al., CVPR 2018
Self-Attention Generative Adversarial Networks, Zhang et al. ICML 2019
Dual Attention Network for Scene Segmentation, Fu et al., CVPR 2019
Wikipedia, https://en.wikipedia.org/wiki/Covariance_matrix
Zhihu, https://zhuanlan.zhihu.com/p/37609917
推荐阅读
ACCV 2020国际细粒度网络图像识别竞赛即将开赛!
添加极市小助手微信(ID : cvmart2),备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳),即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群:每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~
![]()