SEED RL — 大规模扩展强化学习
文 / Google Research 阿姆斯特丹分部研究工程师 Lasse Espeholt
过去几年间,强化学习 (RL) 取得了令人瞩目的进展,近期在 围棋 (Go) 和 Dota 2 等游戏上取得的成功也有力地证明了这一点。模型或 智能体,通过探索环境(如游戏)来学习,同时针对特定目标进行优化。但是,目前的 RL 技术需要大量的训练才能成功完成学习,即便是简单游戏,这也使得迭代研究和产品构想需要考虑到计算成本与耗时等限制。
在“SEED RL:具有加速集中推理功能的高效可扩展的 Deep-RL” (SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference) 一文中,我们介绍了可扩展到数千台机器的 RL 智能体,RL 智能体能够以每秒数百万帧的速度进行训练,同时显著提高计算效率。这一成果通过一种新颖的基础架构实现的,集中模型推理并引入快速通信层来大规模利用加速器(GPU 或 TPU)。我们以广泛使用的 RL 基准(例如 Google Research Football、Arcade Learning Environment 和 DeepMind Lab)来验证 SEED RL 的性能,并表明了可以通过使用更大的模型来提高数据效率。
代码已在 Github 上开源,并提供了 Google Cloud 上使用 GPU 的运行示例。
目前的分布式架构
上一代分布式强化学习智能体(例如 IMPALA)使用了专门用于数值计算的加速器,充分利用了有(无)监督学习速度和效率。RL 智能体的架构通常分为 Actor 和 Learner。Actor 一般在 CPU 上运行,并且通过环境中的动作与模型上进行推理来进行迭代,以预测下一个动作。通常,Actor 会更新推理模型的参数,并在收集到足够多的观察数据后,将观察结果和动作的轨迹发送给 Learner,然后优化模型。在这个架构中,Learner 综合来自数百台机器的分布式推理输入,在 GPU 上训练模型。
早期的 RL 智能体 IMPALA 的架构示例。通常使用效率低下的 CPU在 Actor 上进行推理。更新后的模型参数频繁从 Learner 发送给 Actor,导致带宽需求增加
-
与使用加速器相比,使用 CPU 进行神经网络推理的效率更低且速度更慢,同时,随着模型规模的扩大和计算成本的提高,问题也会越来越多。 -
发送模型参数以及 Actor 和 Learner 之间的中间模型状态所需的带宽,可能成为制约架构性能的瓶颈。 在一台机器上处理两个完全不同的任务(即环境渲染和推理)难以充分利用机器资源。
SEED RL 架构
SEED RL 架构在设计上解决了上述缺点。借助这一架构,Learner 可以在 GPU 或 TPU 等专用硬件上集中完成神经网络推理,通过确保将模型参数和状态保持局部状态来加快推理速度,避免数据传输瓶颈。在将每个环境步骤的观察结果发送给 Learner 时,由于基于 gRPC 框架(具有异步流 RPC )的网络库效率非常高,网络延迟维持在较低水平。因此,在一台机器上可实现每秒最多一百万次的查询。Learner 可以扩展到几千个核心(例如,在 Cloud TPU 最多 2048 个),Actor 的数量可以扩展到几千台机器,从而充分利用 Learner,实现每秒百万帧的训练速度。SEED RL 基于 TensorFlow 2 API,并且在我们的实验中通过 TPU 进行加速。
SEED RL 架构概览:与 IMPALA 架构相反,Actor 仅在环境中采取动作。Learner 在加速器上使用来自多个 Actor 的批量数据来集中执行推理
为确保这一架构顺利完成任务,我们将两种最先进的 (SOTA) 算法集成到 SEED RL 中。一种是基于策略梯度的 V-trace 算法,最早随 IMPALA 推出。一般情况下,基于策略梯度的方法可基于动作采样来预测动作分布。但是,由于 Actor 和 Learner 在 SEED RL 智能体上异步执行任务,Actor 的策略稍落后于 Learner 的策略,即变成 异策略 (off-policy)。而一般基于策略梯度的方法则是 同策略 (on-policy),即 Actor 和 Learner 采取同样的策略,并会在异策略环境中遇到收敛和数值问题。V-trace 是一种异策略算法,因而能在异步 SEED RL 架构中有良好的性能表现。
另一种是 R2D2 算法,这是一种 Q-learning 方法,根据使用递归分布式重放预测的动作未来值来选择动作。这种方法使得 Q-learning 算法能够大规模地执行,同时仍然能够利用递归神经网络,后者能够根据一个 Episode 中所有过去帧的信息来预测未来值。
实验
SEED RL 在常用的 Arcade Learning Environment、DeepMind Lab 环境以及最近发布的 Google Research Football 环境中进行了基准测试。
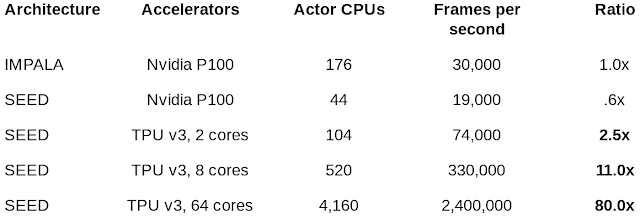
在 DeepMind Lab 上对比 IMPALA 和 SEED RL 各种配置的每秒帧数:SEED RL 使用 4,160 个 CPU 达到每秒 240 万帧的计算速度。假定速度相同,IMPALA 将需要 14,000 个 CPU
在 DeepMind Lab 上,我们使用 64 个 Cloud TPU 核心实现每秒 240 万帧的计算速度,与之前SOTA 的分布式智能体 IMPALA 相比,提高了 80 倍,从而能够大幅加快执行速度和计算效率。相同速度下,IMPALA 需要的 CPU 数量是 SEED RL 的 3 至 4 倍。
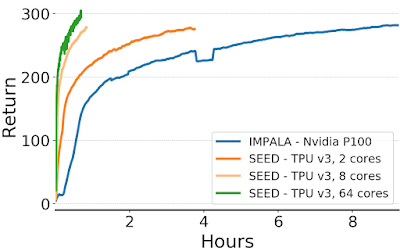
使用 IMPALA 和 SEED RL 在 DeepMind Lab 上玩游戏“explore_goal_locations_small”随时间推移获得的 Episode 回报(即奖励总和):借助 SEED RL,训练时间大幅减少
在针对现代加速器进行优化的架构中,为了提高数据效率自然会扩展模型规模。实验结果显示,通过扩展模型规模和提升输入分辨率,我们能够解决之前无法解决的 Google Research Football的“困难 (Hard) 模式”任务。

在 Google Research Football “困难 (Hard)”任务中不同架构的得分:实验结果显示,通过使用输入分辨率和扩大模型,可以提高得分,而且随着训练的增多,模型的性能将大大超过内置 AI
这篇论文中提供了更多详细信息,包括我们在 Arcade Learning Environment 中取得的成绩。我们认为,SEED RL 及其实验结果表明,通过利用加速器,强化学习已再一次赶超其他深度学习领域。
致谢
本项目是与 Raphaël Marinier、Piotr Stanczyk、Ke Wang、Marcin Andrychowicz 和 Marcin Michalski 协作完成。此外,我们还要感谢 Tom Small 为可视化工作付出的努力。
如果您想详细了解 本文讨论 的相关内容,请参阅以下文档。这些文档深入探讨了这篇文章中提及的许多主题:
Go
https://www.nature.com/articles/nature16961Dota 2
https://openai.com/projects/five/SEED RL:具有加速集中推理功能的高效可扩展的 Deep-RL
https://arxiv.org/abs/1910.06591Google Research Football
https://ai.googleblog.com/2019/06/introducing-google-research-football.htmlArcade Learning Environment
https://arxiv.org/abs/1207.4708DeepMind Lab
https://github.com/deepmind/labGithub
https://github.com/google-research/seed_rlIMPALA
https://arxiv.org/abs/1802.01561gRPC
https://grpc.io/网络库
https://github.com/google-research/seed_rl/tree/master/grpcTensorFlow 2
https://www.tensorflow.org/guide/effective_tf2TPU
https://cloud.google.com/tpu/策略梯度
https://www.youtube.com/watch?v=KHZVXao4qXsV-trace
https://arxiv.org/abs/1802.01561R2D2
https://openreview.net/forum?id=r1lyTjAqYX&utm_campaign=RL%20Weekly&utm_medium=email&utm_source=Revue%20newsletter
更多 AI 相关阅读:
了解更多请点击 “阅读原文” 访问 Github。




