融合视频目标检测与单目标、多目标跟踪,港中文开源一体化视频感知平台 MMTracking
机器之心报道
编辑:魔王
香港中文大学多媒体实验室(MMLab)OpenMMLab 开源一体化视频目标感知平台 MMTracking。

视频目标检测只需对视频内的每一帧进行检测,不要求对不同帧中的同一目标进行关联。
多目标检测在完成视频目标检测的基础上,更加侧重于对视频内的同一目标进行关联。
单目标跟踪更加侧重人机交互,算法需要在给定一个任意类别、任意形状目标的情况下,对其进行持续跟踪。
import torch.nn as nnfrom mmdet.models import build_detectorclass BaseMultiObjectTracker(nn.Module):def __init__(self,detector=None,reid=None,tracker=None,motion=None,pretrains=None):self.detector = build_detector(detector)...model = dict(type='BaseMultiObjectTracker',detector=dict(type='FasterRCNN', **kwargs),reid=dict(type='BaseReID', **kwargs),motion=dict(type='KalmanFilter', **kwargs),tracker=dict(type='BaseTracker', **kwargs))视频目标检测:DFF、FGFA、SELSA
多目标跟踪:SORT、DeepSORT、Tracktor
单目标跟踪:SiameseRPN++
对视频目标检测算法 SELSA 的实现结果(第一行)相比于官方实现(第二行),在 ImageNet VID 数据集上 mAP@50 超出 1.25 个点。

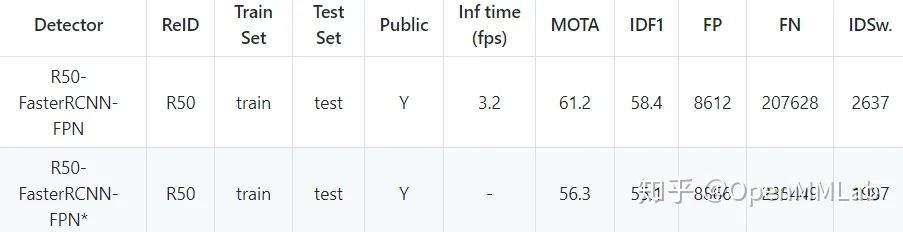
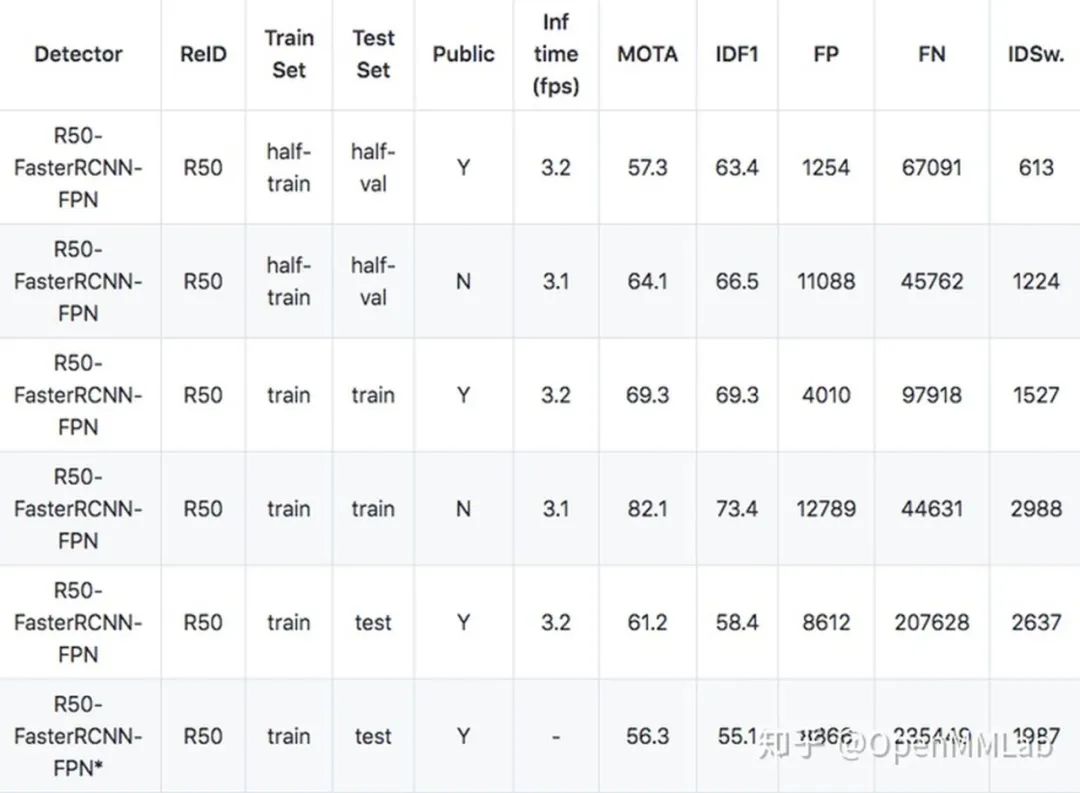
对多目标跟踪算法 Tracktor 的实现结果(第一行)相比于官方实现(第二行),在 MOT17 数据集上 MOTA 超出 4.9 个点,IDF1 超出 3.3 个点。
对单目标跟踪算法 SiameseRPN++ 的实现结果(第一行)相比于官方实现(第二行),在 LaSOT 数据集上的 Norm precision 超出 1.0 个点。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文