打破语言模型黑盒子:谷歌对BERT来了一次「语法测试」

新智元报道
新智元报道
编辑:David
【新智元导读】谷歌研究人员对自家BERT模型进行了「语法测试」,结果显示,BERT确实学会了遵循「主谓一致」的语法,但并未将其视作规则,而当成了一种偏好。模型的具体表现取决于动词出现的频率和形式。
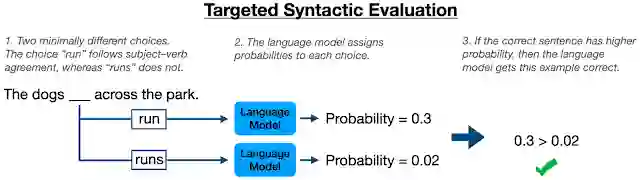

先前工作回顾:「自然句」与「人造句」

没见过的「主语-动词」对
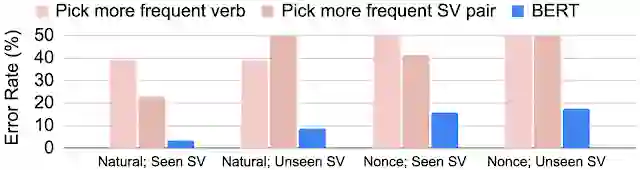
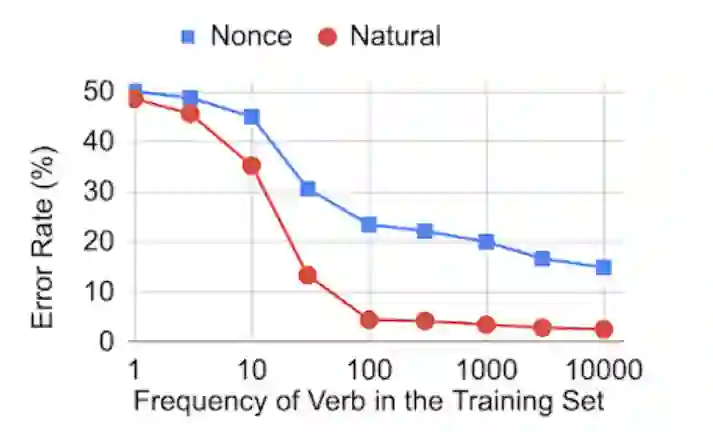
动词出现频率对BERT性能的影响
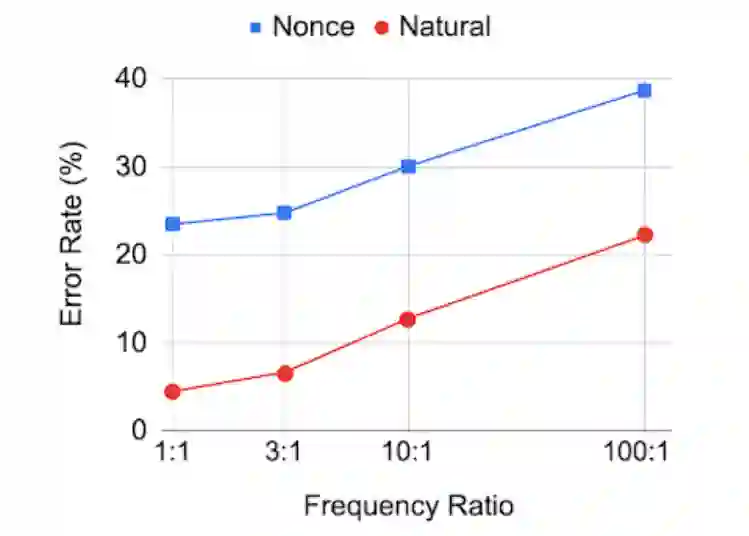
动词形式差异对BERT的影响
结论

登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文