双塔模型的最强出装,谷歌又开始玩起“老古董”了?

文 | 兔子酱
双塔模型已经证明在搜索和问答任务中是非常有效的建模方法,理论和业务落地已相当成熟。双塔根据参数共享程度不同,通常会归纳成两类:Simese dual encoder和Asymmetric dual encoder,前者参数结构完全对称,后者则是不完全对称(下文简称SDE和ADE)。
本篇论文是继双塔沉寂许久之后,谷歌再次将它推到宇宙中心,并打开双塔的最强出装,详细地探索两者的区别和关联,也通过实验给出了双塔结构的更多经验性结论。适合老司机再次回味经典和小白做深刻且系统地入门~
论文题目:
Exploring Dual Encoder Architectures for Question Answering
论文链接:
https://arxiv.org/abs/2204.07120
![]() 背景
背景![]()
 背景
背景首先科普下什么是SDE和ADE?双编码器网络结构是将text1和text2分别编码成向量表征,然后计算两者的cosine等距离函数衡量其相似度。SDE是完全共享参数的双胞胎网络,也就是虽说是双塔,但实际上query/user和doc/item共用一套参数;ADE只是部分参数共享或者完全不共享,是独立的两套参数网络。它们的共同点是都不会进行深层交互,对比BERT则是典型的交互式网络。双塔结构一个最典型的应用是召回or粗排,对计算速度要求严格的场景。
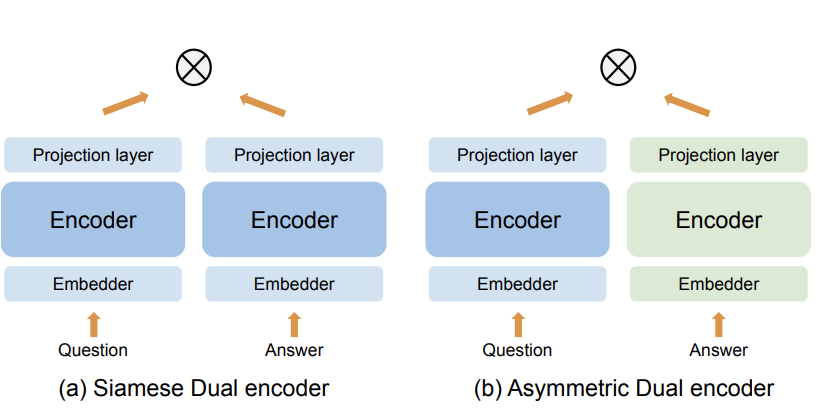
双塔的建模思想是比较简单和容易理解的。本篇文章短小精悍,亮点就在于提供双塔应用场景下一个较通用的结论,解释清楚了几个疑问:
-
ADE和SDE在QA任务上哪一个效果更好? -
ADE表现差的原因是什么?解决办法是什么?
作者通过合理且详实的实验得到可靠的结论,小白也可以迅速get到如何在(向)实(导)验(师)做科(汇)研(报)。

![]() 实验
实验![]()
作者在QA检索任务上进行了5个实验,计算query和候选answer(doc or passage)的相似性,评测任务是MS MARCO和MultiReQA。模型的encoder是基于transformer,cosine作为距离度量函数,目标是探究参数的共享化程度对建模效果影响。 5组实验网络分别是图一的标准SDE和ADE,以及3个变种结构:• ADE with shared token embedder (ADE-STE) • ADE with frozen token embedder (ADE-FTE) • ADE with shared projection layer (ADE-SPL) 实验结果如下:
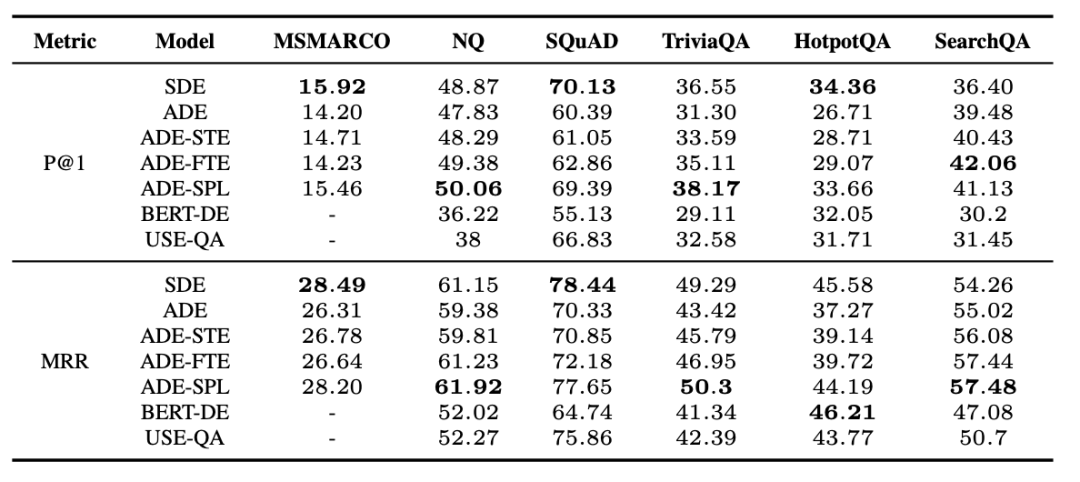
实验结论:
-
ADE在多个任务上的表现一致地明显逊色于SDE。作者给出来合理的解释是由于ADE本质是两个参数不同的网络,所以把query和doc映射到两个完全不同的向量空间。这一点后面又给出了更有力的证据。 -
ADE-SPL的表现可以媲美SDE。后3个实验是作者探索参数共享化程度提出的结构,同时也给出了网络的哪一部分是限制ADE效果的关键。只是共享或者固定底层token embedder参数带来的效果提升并不明显,但当最后的顶层参数共用一套全连接层的时候,可以取得和SDE接近的效果。为什么呢?作者的猜测是因为最后的MLP又把参数约束到了同一个向量空间中了。
为了进一步说明问题,作者进行了另一个实验,将NaturalQuestions测试集的query和answer提前计算出来,然后通过t-SNE映射并聚类到一个二维空间中,惊讶地发现,dual encoder的表现取决于最后两者是否在一个可比的向量空间。
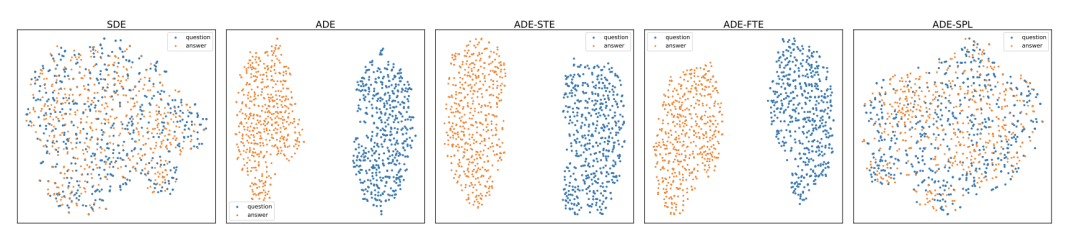
![]() 总结
总结![]()
本文篇幅非常简短,逻辑非常清晰,针对dual encoder的两种经典结构进行了比较探索,最终证明SDE比ADE表现优异来自于顶层参数共享一致。
萌屋作者:兔子酱
一个颜值与智商双高的妹纸,毕业于明光村职业技术学校北邮。和小夕一起打过比赛,霸过榜。目前在百度做搜索算法。
 萌屋作者:兔子酱
萌屋作者:兔子酱
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
 后台回复关键词【入群】
后台回复关键词【入群】
