预训练模型参数量越来越大?这里有你需要的BERT推理加速技术指南

基于 Transformer 的预训练模型,尤其是 BERT,给各种 NLP 任务的 performance 带来了质的飞跃。如今 pretrained model + Fine tune 几乎已经成为 NLP modeling 工作的标准范式。然而这些模型却是越来越重,如 RoBERTa-large 有 3.55 亿参数,GPT2-xl 有 15 亿参数,GPT3 的参数达到了 1750 亿!
在有着三高问题(特点?)的互联网系统中使用这种模型面临着很大的性能瓶颈,甚至已经很难将一个 SOTA 的模型直接搬到线上进行实时的推理计算。本文将介绍最广为使用的预训练模型 BERT 的推理加速技术,这些技术可以应用到其他类似 Transformer Based 预训练模型中。
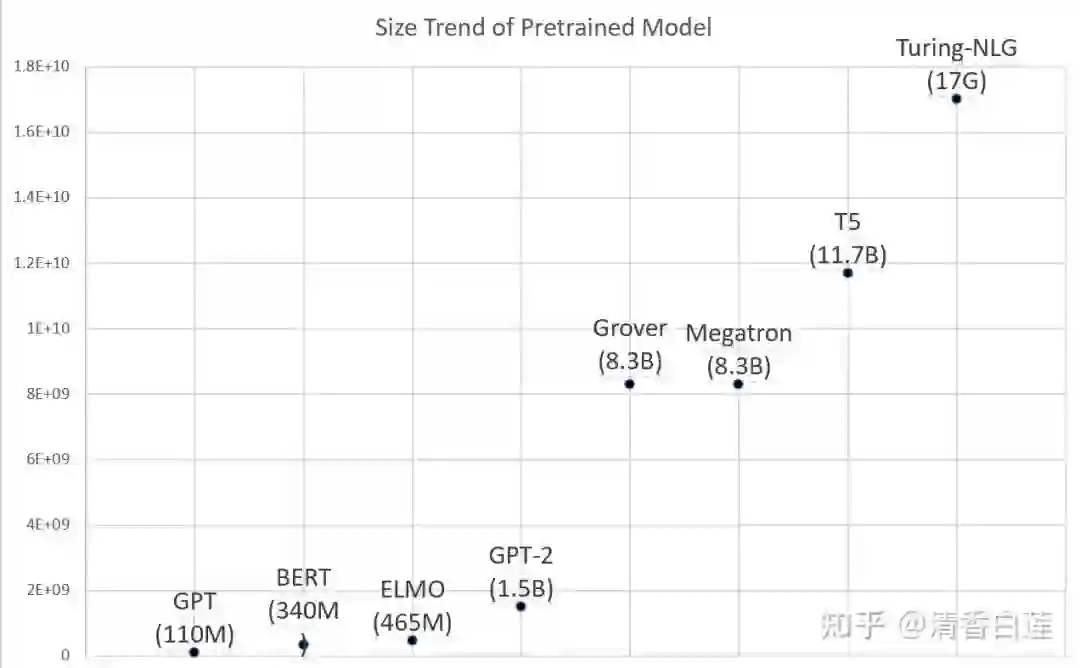

BERT 模型包含一个 embedding 层与多个 Transformer 层。如果你的语料比较小,任务比较简单,可以对 BERT 模型做适当的裁剪:
Embedding 层的裁剪:如果用的是 Multilingual BERT 可以将用不到的语言的 Word Embedding 裁剪掉。可以用 BERT 的 vocabulary 对你的 target 语料进行 BPE 切词,并统计词频,对于频次特别低的词的 Embedding 也可以裁剪掉。
Transformer 层的裁剪:BERT 中包含了 12 层的 Transformer,大的有 24 层,其他模型甚至更多,但实际你的任务如果不是很复杂,可能未必需要这么多层。由于底层的 Transformer 善于捕捉细粒度的信息,一般有限选择底层的 Transformer 层。常见的选择方式是选择底部几层,如第 1、2、3 层,或者间隔选,如第 1、3、5 层。

2.1 Embedding层的压缩
2.1.1 维度缩减
这是最简单粗暴的方式,BERT 模型的 Embedding 维度有 768 与 1024 两个版本,你在设计 Student Model 时可以用 512 甚至更低的维度。这时候如果想复用 BERT 的 Transformer 的参数,那么需要对 Embedding 做一个线性变换,将其转换成 768 或者 1024 维。可通过添加一个全连接层来实现。
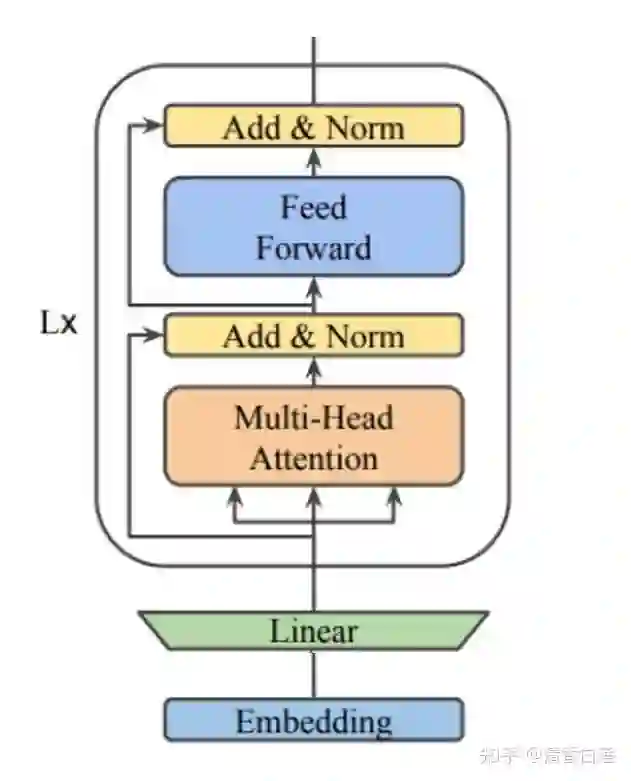
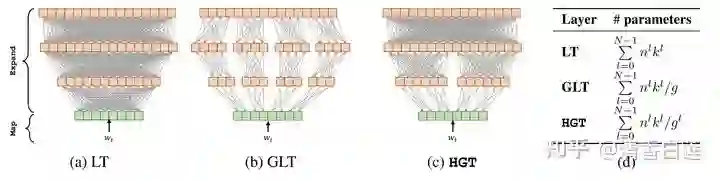
2.1.2 Factorized embedding parameterization
2.2 Transformer层的压缩
这种方法是在 ALBERT 中使用的,即多个层使用相同的参数,它不能较少推理的时间但可以减少模型的体积。参数共享有三种方式:只共享 feed-forward network 的参数、只共享 attention 的参数、共享全部参数。
另一个更优雅的方式是压缩宽度,使用窄深的模型,下图是 MobileBERT 用的模型架构。最终产出的是窄深的 MobileBERT,但需先训练一个比较宽的 model,然后将其知识蒸馏到 MobileBERT 中。其中宽模型与窄模型使用了相同的 Embedding 层,这个 embedding 层通过线性变换来适配各自的 Transformer 层。
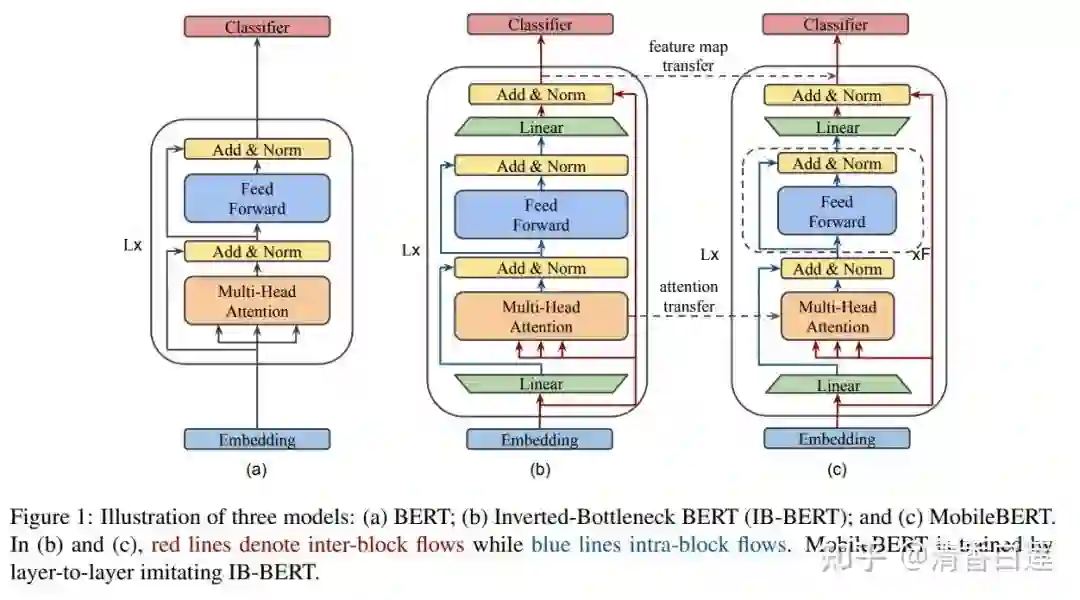
2.3 蒸馏方法
BERT 的蒸馏方法已经有过很多研究,如 BERT-PKD、DistilBERT 以及 TinyBERT 等,这些方法的卖点主要在 loss 的设计上。这里介绍下 TinyBERT 的 Loss 设计,应该说考虑的比较全面主要包含三大块:Attention Loss,Hidden Loss 与 Embedding Loss。
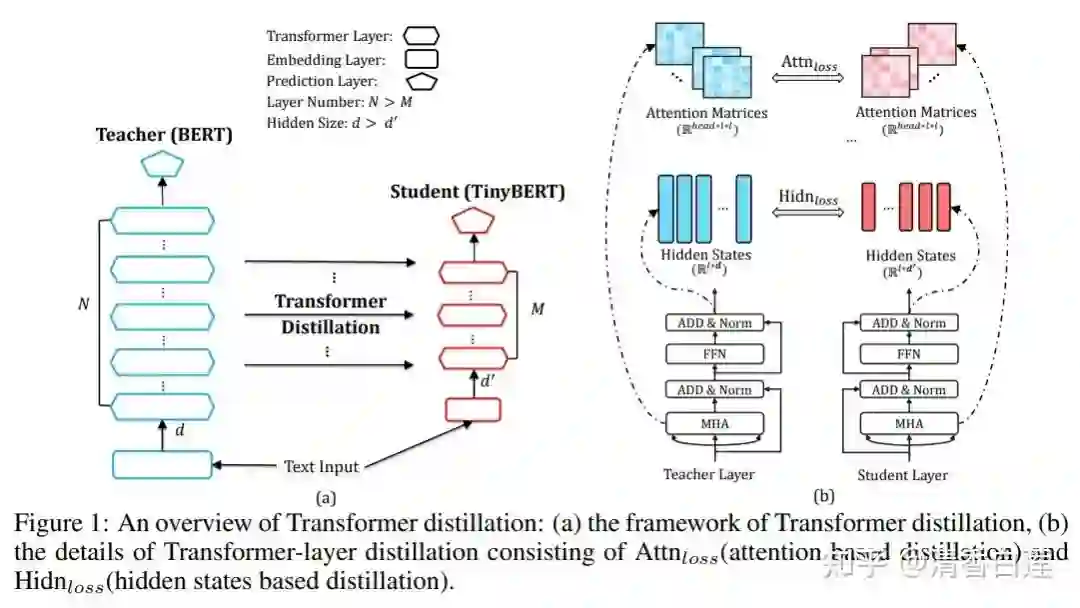
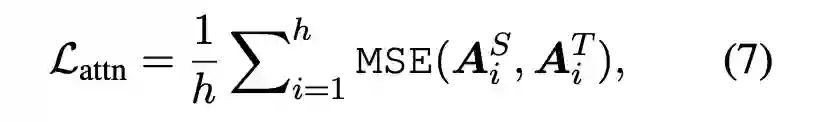
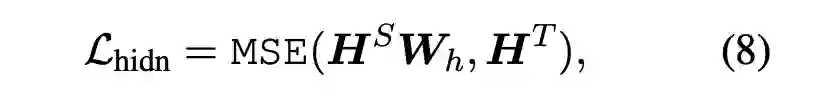
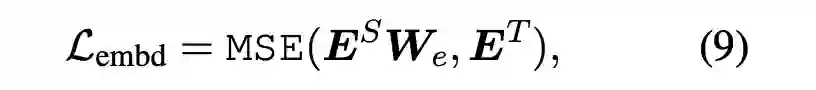
2.4 Task Specific蒸馏
前面的蒸馏方式是针对 BERT 模型本身的,学习的是 BERT 中通用的语言表征方式,并未涉及到具体的任务,这种蒸馏被称为 Task Agnostic 蒸馏。预训练模型只是提供了一个初始参数,针对具体的任务,还要在相应的数据集上做微调,得到我们具体任务的 model,然后我们对这个针对具体 NLP 任务的 model 做蒸馏,也就是 Task Sepcific 蒸馏。
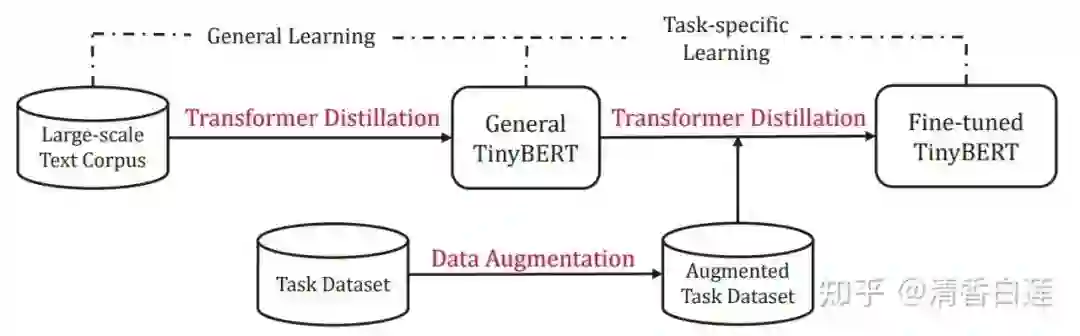
2.4.1 完整蒸馏流程
以 TinyBERT 作为 Student Model 为例, 整个蒸馏的流程为:
1. 用上一小节介绍的 Task Agnostic 方法将 BERT 中的知识蒸馏到 TinyBERT 中;
2. 收集具体任务相关数据集,然后用 BERT 模型在这个数据集上做微调得到 Teacher Model;
3. 以第一步的 TinyBERT 的参数来初始化 Student Model,用 Task Specific 蒸馏方法将 Teacher Model 的知识蒸馏到 Student Model。
Task Specific 的损失函数一般采用:
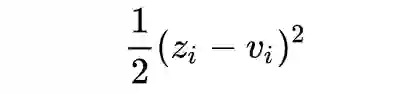
对 Student Model 的 logits 升温后的交叉熵损失:采用一个广义的 softmax 函数,T 为温度,值越大,输出的概率分布越平缓,越小则分布越陡峭,当 T=0 时就变成了 one-hot 编码。在做 inference 时 T=1,在做训练时为大于 1 的某个数。
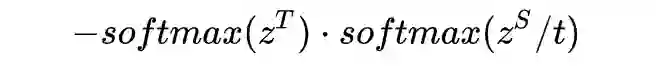
在知识蒸馏问题中,并非 Teacher Model 越好 Student Model 就越好。当 Teacher Model 比 Student Model 大很多时,Capacity Gap 问题将会变得非常严重。下图中的 Student Model 都是 ResNet14,当 Teacher Model 的体量超过 ResNet32 时,蒸馏的结果却出现了明显的 drop。同时 KD Loss 随着 Teacher Model 的增大而不断增加,说明 Student Model 对 Teacher Model 的模仿能力或者拟合程度越来越低。
一般随着模型的增大,会对预测的 label 更加 confident,即分配更高的概率。如下图左侧,Teacher Model 对预测的 label 分配的概率时 0.984,而 Student Model 分配的概率是 0.73。而常规的知识蒸馏使用了 Soft Target,即让 Student Model 去学习 Teacher Model 的输出概率分布,然而 Student Model 在体量上的劣势就注定了它很难在这方面向 Teacher Model 看齐。


另一个缓解 Capacity Gap 的策略是使用多阶段的蒸馏,一般使用两阶段,引入一个 size 适中的网络,即 Teacher Assistant,作为 Teacher 与 Student 之间的过渡。Teacher 与 TA 以及 TA 与 Student 之间的 Capacity Gap 都不是很严重,先将 Teacher 的知识蒸馏到 TA,再将 TA 的知识蒸馏到 Student,这就避免了 Gap 过大时蒸馏效果出现剧烈 drop 的情况。

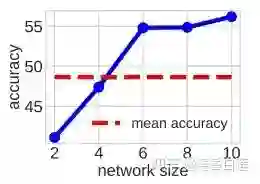
那么 TA 的 size 选多少合适呢?一般并不是选择两者体积的平均,而是在各自单独训练的情形下,性能介于 Teacher 与 Student 之间的网络的 size。例如,在下图重蓝色的折线表示随着模型层数的增加,模型的准确率,如果 Student 是两层,Teacher 是 10 层,那么 TA 应该选 4 层,因为它的性能接近前两者的平均值。

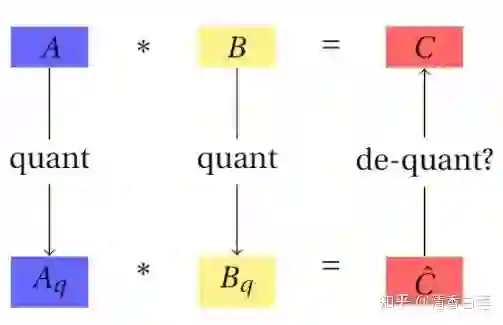
量化
量化是一种信息的有损压缩方式,在神经网络里面的应用是将高精度的浮点数运算转化成低精度的整数运算,以加速模型的而推理计算。
量化方式有两种:
训练后量化:模型训练好之后再进行量化,这种方法一般对大模型效果不错,对小模型则效果比较差;
训练感知量化:在训练过程中对模型参数量化,inference 与 training 使用的是量化过后的 weights 和 activation。
3.1 对称线性量化
为了保证精度,一般都是用训练感知量化。在 BERT 中经常采用的量化算法是对称线性量化(symmetric linear quantization)。
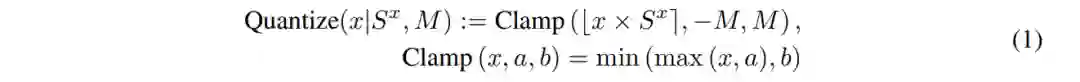
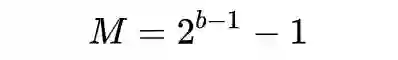
在训练过程中 weights 的尺度参数可以设为:
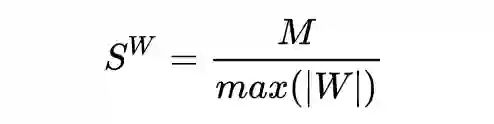
activations 的尺度参数可基于下式,其中 EMA 为指数加权平均。
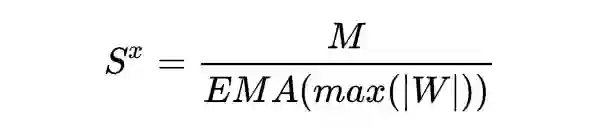
量化的极限是 BinaryBERT,模型的 Weights 与 Embeddings 都用 1 位的整数表示,即要么是 0 要么是 1,模型的体量可以缩减为原来的 1/24,推理速度提升一个数量级。
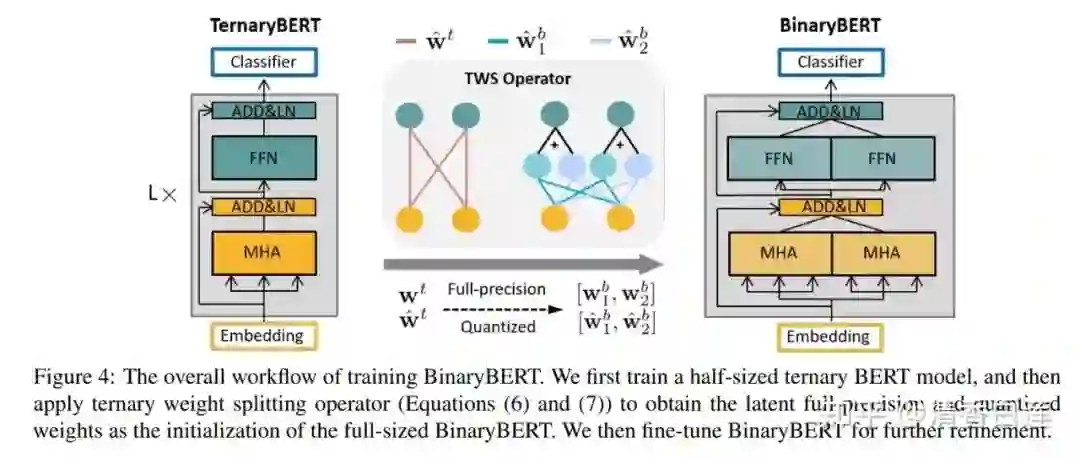
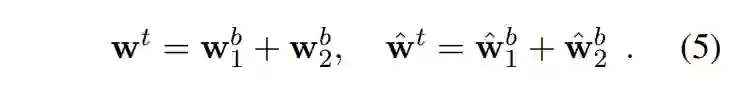
其中:

有点类似于用两个 Binary 数据来表示一个 Ternary 数据,所以 BinaryBERT 的 size 也是 ternary BERT 的两倍。

4.1 计算流图优化
神经网络是一个计算流图,原始的执行流程还可以还很多优化,比如算子的合并,运行时不需要部分的裁剪等。常见的针对神经网络计算流图优化的引擎主要有 ONNX Runtime 与 TVM,其中 ONNX Runtime 使用最广。
ONNX Runtime 是由微软推出的推理优化框架,支持多种运行后端包括 CPU,GPU,TensorRT,DML 等,并且对通用的 ONNX 格式模型提供了原生的支持。其基本原理是先执行一遍模型的推理,然后自动将模型中用不到的部分修剪掉,并将部分算子做了合并,还能对网络的拓扑结构做优化,最终生成一个精简的静态计算流图。
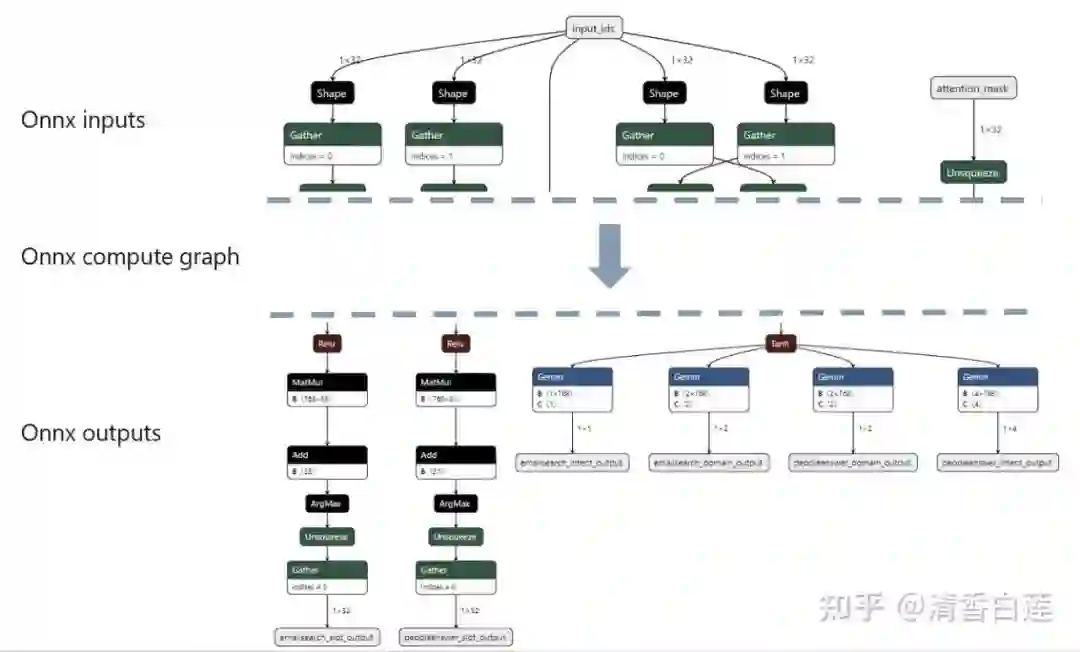
使用起来也非常简单,只要加载模型然后执行一次推理运算即可,具体详见官方文档:

前面介绍的推理加速方法都是对模型本身的优化,换个角度思考,也可以从硬件方面去进行加速,不过由于硬件门槛高,这方面的案例并不多,不过大厂好像都在这块有投入。
神经网络处理器:由于芯片定制化生产技术的成熟,谷歌在 2015 年就推出了专门用于神经网络计算的 TPU,如今 AI 应用润物细无声,占据了大部分的算力消耗,各大硬件厂商都在发力神将网络处理器(NPU)。
ASIC:在某些人眼中,可能任何处理器都不是最优的只有 ASIC 才是最优的,也就是为某个应用定制专业的芯片。这块,如果模型已经高度产品化了,如语言识别、图像识别、机器翻译等可以考虑使用。
FPGA:这块也炒的比较火,微软已经在数据中心使用了大量的 FPGA 代替 CPU 做科学计算。单从算力本身来说 FPGA 的主频远比不上 CPU 与 GPU,但他的优势在于并行度,对于大的矩阵计算,CPU 需要很多时钟周期才能完成,GPU 拓展了带宽比 CPU 有了明显的优势,但 FPGA 在并行上有无与伦比的优势,只要门电路足够,可以根据需要不断增加并行度,并且它完成一件事情的时间是确定的,每个并发完成的时间完全一致,不存在时间片、线程与资源冲突问题。FPGA 的另一个优势是完成同样的计算功耗比 CPU 低很多,GPU 就更不用说了。但这一块实际使用起来并没有那么容易,可以应用的场景非常少,下一节做个简单的案例介绍。
FPGA 本身的主频非常低,跟 CPU 差远了,而且存储资源非常小,数据吞吐能力差,完全用 FPGA 实现一个 BERT 模型理论上不是不行,但肯定是土豪的玩具。一个折衷的办法是与 CPU 协同工作,把 CPU 不擅长且 memory cost 较低的矩阵计算任务交给它,也就是 BERT 中的 Encoder 层,CPU 主要处理 Embedding 层与 Task Specific 层。当然,由于 FPGA 的 memory 限制,需要把 BERT 模型量化成 Integer Only BERT,整个系统的架构如下:
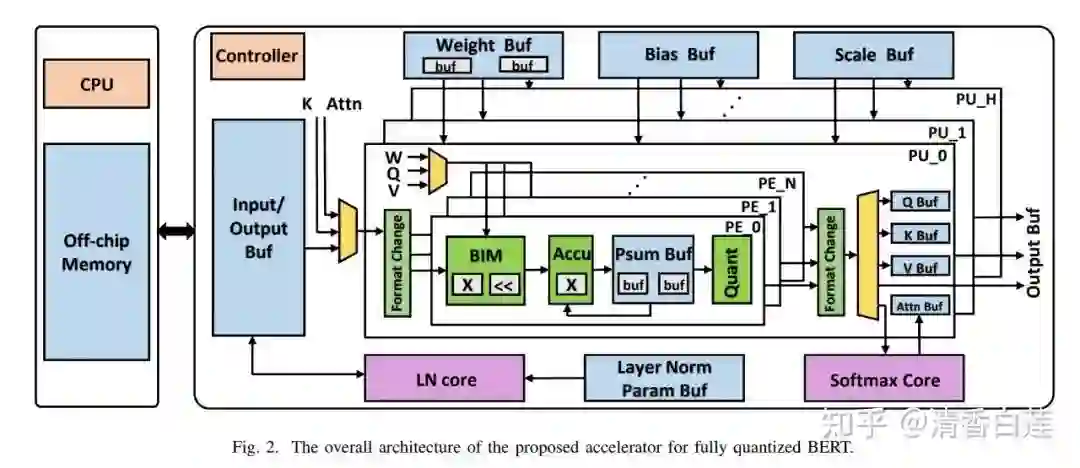
CPU 计算的中间结果与模型的权重都存放在 off-chip memory 上,通过 AXI4 接口传送给 FPGA。FPGA 内部实现了三个计算单元用于加速计算:
1. PE (Processing Element):用于不同位宽的矩阵乘法计算。
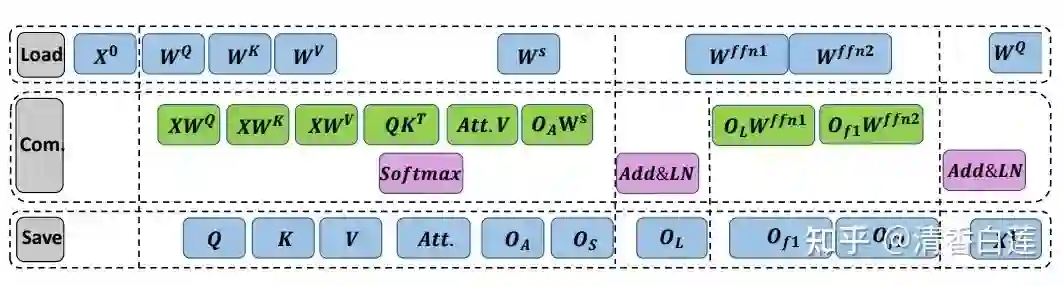
3. LN Core:用于 Layer Normalization 计算,由于 LN 运算中很多 Element Wise 的加乘运算与非线性变换,单独依靠 PE 无法完成,所以针对这部分做了专门的设计。 整个数据流图如下,FPGA 从 off-chip memory buffer 中读取数据,为了减少 FPGA 的数据吞吐量,将每个阶段分成几个子阶段,每个子阶段只加载需要的数据,最后将计算结果写入 goff-chip memory buffer 供 CPU 做 Task Specific 层的运算。

总结
面这些技术未必全部都需要做,一般经过蒸馏与 ONNX Runtime 的推理优化,可以将模型从 1~2G 压缩到 30~60M,推理速度也至少提升一个数量级,基本满足线上需求,模型的 performance 的 drop 一般在 5% 以内。量化虽然能显著缩小模型的体积,但对小模型 ROI 较低,一般蒸馏与量化两种方法二选一就行了,很少同时做。FPGA 本身算力较差,很难提升推理速度,与 CPU/GPU 相比,主要优势在于更高的并行计算能力与更低的功耗比,但高度定制化,使用门槛高,设计的不好很可能会弄巧成拙,主要用在资源受限的边缘计算设备上。
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。

参考文献
V. Sanh, L. Debut, J. Chaumond, and T. Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter, 2020.
S. Sun, Y. Cheng, Z. Gan, and J. Liu. Patient knowledge distillation for bert model compression, 2019.
Sachin Mehta, Rik Koncel-Kedziorski, Mohammad Rastegari, Hannaneh Hajishirzi. DeFINE: DEEP FACTORIZED INPUT TOKEN EMBEDDINGS FOR NEURAL SEQUENCE MODELING, 2020.
Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, Denny Zhou. MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices, 2020.
Jia Guo, Minghao Chen, Yao Hu, Chen Zhu, Xiaofei He, Deng Cai. Reducing the Teacher-Student Gap via Spherical Knowledge Disitllation.
Seyed-Iman Mirzadeh, Mehrdad Farajtabar, Ang Li, Hassan Ghasemzadeh. Improved Knowledge Distillation via Teacher Assistant: Bridging the Gap Between Student and Teacher, 2019.
Ofir Zafrir, Guy Boudoukh, Peter Izsak, Moshe Wasserblat. Q8BERT: Quantized 8Bit BERT, 2019.
Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer. I-BERT: Integer-only BERT Quantization, 2021.
Yelysei Bondarenko, Markus Nagel, Tijmen Blankevoort. Understanding and Overcoming the Challenges of Efficient Transformer Quantization. 2021.
Zejian Liu , Gang Li , Jian Cheng. Hardware Acceleration of Fully Quantized BERT for Efficient Natural Language Processing, 2021.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧





