【导读】作为计算机视觉领域的三大国际顶会之一,IEEE国际计算机视觉与模式识别会议CVPR(IEEE Conference on Computer Vision and Pattern Recognition) 每年都会吸引全球领域众多专业人士参与。CVPR 2021将在线举行, 中国科学院院士、中科院自动化所智能感知与计算研究中心主任谭铁牛将出任大会主席(General Chair,GC),上海科技大学的虞晶怡教授将任程序主席(Program Chair,PC)。今年的CVPR有效投稿多达7500篇,一共有1663篇论文被接收,接收率为27%。
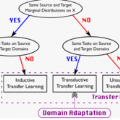
为此,专知小编提前为大家整理了五篇CVPR 2021领域自适应(Domain Adaptation)相关论文,这块这几年一直比较受关注,特别是未知域、通用域学习等等?大家先睹为快——真实域泛化、多目标域自适应、通用领域自适应、频域空间域方法、未知域泛化
CVPR2021IVC、CVPR2021PID、CVPR2021IC、CVPR2021VU、CVPR2021OD、CVPR2021OT、CVPR2021AR
1. Adaptive Methods for Real-World Domain Generalization
作者:Abhimanyu Dubey, Vignesh Ramanathan, Alex Pentland, Dhruv Mahajan
摘要:不变性(Invariant)方法在解决域泛化问题方面非常成功,其目的是对在训练中使用的数据分布不同的数据分布进行推断。在我们的工作中,我们调研了是否有可能利用来自不可见的测试样本本身的域信息。我们提出了一种包含两个步骤的领域自适应方法:a)我们首先从无监督的训练示例中学习判别性领域嵌入,以及b)使用该领域嵌入作为补充信息来构建领域自适应模型,该模型同时采用了以下两种方法:进行预测时要考虑输入及其域。对于不可见的域,我们的方法仅使用一些未标记的测试示例来构建域嵌入。这可以在任何不可见的域上进行自适应分类。我们的方法可在各种领域通用基准上实现最先进的性能。此外,我们推出了第一个真实的,大规模的领域通用基准测试Geo-YFCC,其中包含110万个样本,经过40个训练,7个验证和15个测试域,比以前的工作大了几个数量级。我们显示,与在所有训练域的数据联合上训练模型的简单基准相比,现有方法无法扩展到该数据集或表现不佳。相比之下,我们的方法实现了1%的显着改进。
网址: https://arxiv.org/abs/2103.15796
2. Curriculum Graph Co-Teaching for Multi-Target Domain Adaptation
作者:Subhankar Roy, Evgeny Krivosheev, Zhun Zhong, Nicu Sebe, Elisa Ricci
摘要:在本文中,我们讨论了多目标域适应(MTDA),其中给定一个标记的源域数据集和多个数据分布不同的未标记的目标域数据集,任务是为所有目标域学习可靠的预测模型。我们确定了两个关键方面,可以帮助减轻MTDA中的多领域转移:特征聚合和课程学习(curriculum learning)。为此,我们提出了使用双重分类器的课程图协同教学模型 Curriculum Graph Co-Teaching(CGCT),其中之一是图卷积网络(GCN),该图卷积网络汇总了跨域相似样本的特征。为了防止分类器过分适合自己的嘈杂伪标签,我们与双分类器一起使用了一种共同教学策略,并借助课程学习来获得更可靠的伪标签。此外,当域标签可用时,我们提出了Domain-aware Curriculum Learning(DCL),这是一种顺序适应策略,首先适应较容易的目标域,然后适应较难的目标域。我们在几个基准上实验性地证明了我们提出的框架的有效性,并大幅提高了MTDA中的最新水平(例如,在DomainNet上为+ 5.6%)。
代码: https://roysubhankar.github.io/graph-coteaching-adaptation
网址: https://arxiv.org/abs/2104.00808
3. Domain Consensus Clustering for Universal Domain Adaptation
作者:Guangrui Li, Guoliang Kang, Yi Zhu, Yunchao Wei, Yi Yang
摘要:在本文中,我们研究了通用域自适应(UniDA)问题,该问题旨在在不对齐的标签空间下将知识从源域转移到目标域。UniDA的主要挑战在于如何将公共类(即跨域共享的类)与私有类(即仅在一个域中存在的类)分开。先前的工作将目标域中的私有样本视为一个通用类,但忽略了它们的固有结构。因此,所得到的表示在潜在空间中不够紧凑,并且很容易与普通样本混淆。为了更好地利用目标域的内在结构,我们提出了Domain Consensus Clustering(DCC),它利用域共识知识来发现普通样本和私有样本上的区分性聚类。具体来说,我们从两个方面汲取领域共识知识,以促进聚类和私有类发现,即语义级别的共识(将周期一致的簇标识为通用类)和样本级别的共识,利用交叉域分类协议以确定集群的数量并发现私有类。基于DCC,我们能够将私有类与公共类分开,并区分私有类本身。最后,我们在识别出的常见样本上应用了分类感知比对技术,以最大程度地减少分布偏移,并应用原型正则化方法来激发可辨别的目标集群。在四个基准上进行的实验表明,DCC明显优于以前的最新技术。
网址: http://reler.net/papers/guangrui_cvpr2021.pdf
4. FSDR: Frequency Space Domain Randomization for Domain Generalization
作者:Jiaxing Huang, Dayan Guan, Aoran Xiao, Shijian Lu
摘要:域泛化旨在从“已知”源域中为各种“未知”目标域学习可泛化的模型。已经通过域随机化对它进行了广泛的研究,该方法将源图像转移到空间中的不同样式以学习域不可知的特征。然而,大多数现有的随机化方法使用的GAN常常缺乏控制力,甚至改变了图像的语义结构。受到将空间图像转换成多个频率分量(FC)的JPEG理念的启发,我们提出了频空域随机化(FSDR),该方法通过仅保留域不变FC(DIF)和随机化域变FC(DVF)来随机化频率空间中的图像。FSDR具有两个独特的功能:1)将图像分解为DIF和DVF,从而允许对其进行显式访问和操纵以及更可控的随机化;2)它对图像的语义结构和领域不变特征的影响最小。我们统计地检查了FC的域方差和不变性,并设计了一个网络,该网络可以通过迭代学习动态地识别和融合DIF和DVF。对多个领域可概括的分割任务的广泛实验表明,FSDR实现了出色的分割,其性能甚至与在训练中访问目标数据的领域自适应方法相当。
网址: https://arxiv.org/abs/2103.02370
5. RobustNet: Improving Domain Generalization in Urban-Scene Segmentation via Instance Selective Whitening
作者:Sungha Choi, Sanghun Jung, Huiwon Yun, Joanne Kim, Seungryong Kim, Jaegul Choo
摘要:将深度神经网络的泛化能力提高到不可见域对于现实世界中与安全相关的应用(如自动驾驶)至关重要。为了解决这个问题,本文提出了一种新的实例选择性白化损失(instance selective whitening loss),以提高针对未知域的分割网络的鲁棒性。我们的方法解开了特征表示的高阶统计量(即特征协方差)中编码的特定于域的样式和域不变内容,并有选择地仅删除导致域移位的样式信息。如图1所示,我们的方法为(a)低照度,(b)多雨和(c)不可见的结构提供了合理的预测。这些类型的图像未包含在训练数据集中,其中基线显示出明显的性能下降,这与我们的方法相反。我们的方法提高了各种骨干网络的鲁棒性,而没有额外的计算成本。我们在城市场景分割中进行了广泛的实验,显示了我们的方法在现有工作中的优越性。
代码: https://github.com/shachoi/RobustNet
网址: