NeurIPS 2019 | 国科大、厦大联合提出FreeAnchor:一种新的anchor匹配学习法

前言
本文将对NeurIPS2019会议论文《FreeAnchor:Learning to Match Anchors for Visual Object Detection》进行解读。为了打破IoU(Intersection-over-Unit)的限制,作者提出了一种新的anchor匹配学习的方法,允许以灵活的方式来匹配目标与anchor,称为“FreeAnchor”。FreeAnchor通过将目标检测器训练转换为最大似然估计(MLE)过程,实现将hand -crafted设定的anchors更新为“free”方式产生的anchors。在COCO的实验表明,FreeAnchor在性能上显著超过同类方法。
研究现状
为了表示具有有限卷积特征的各种外观,宽高比和空间布局的目标,大多数基于CNN的检测器都用多个比例和宽高比的anchor boxes作为目标定位的参考点,通过分配给每个目标若干个anchors,可以确定features并执行分类和定位。基于anchor的检测器通常利用空间对齐方式(即目标与anchor之间的IoU)作为anchor分配依据,并以hand-crafted方式选择。一方面,对具有倾斜特征的目标(如细长目标),其最具代表性的特征并不靠近目标中心。因此,空间对齐的anchor可能对应较少的features,会降低分类和定位能力。另一方面,当多个目标组合在一起时,使用IoU匹配适当的anchors则更为困难。由此可见,很难设计一种通用的规则,可以将anchors/features与各种几何布局的目标进行最佳匹配。
为了打破预先分配anchors的限制, anchor-free方法采用了像素级监督【1】和中心位置边界框回归【2】。CornerNet【3】和CenterNet 【4】用关键点学习替换了边界框学习。MetaAnchor【5】方法学习从带有子网络的任意自定义的先验框中生成anchors。GuidedAnchoring 【6】利用语义特征来指导anchors的预测,同时用预测的anchors替换密集的anchors。IoU-Net【7】结合了IoU引导的NMS(Non-Maximum Suppression,非极大值抑制),这有助于消除由误导的分类置信度引起的回归失败。
但在检测器训练期间仍然缺乏一种系统的方法来对anchors和目标之间的对应关系进行建模,这阻碍了features选择和学习的优化。
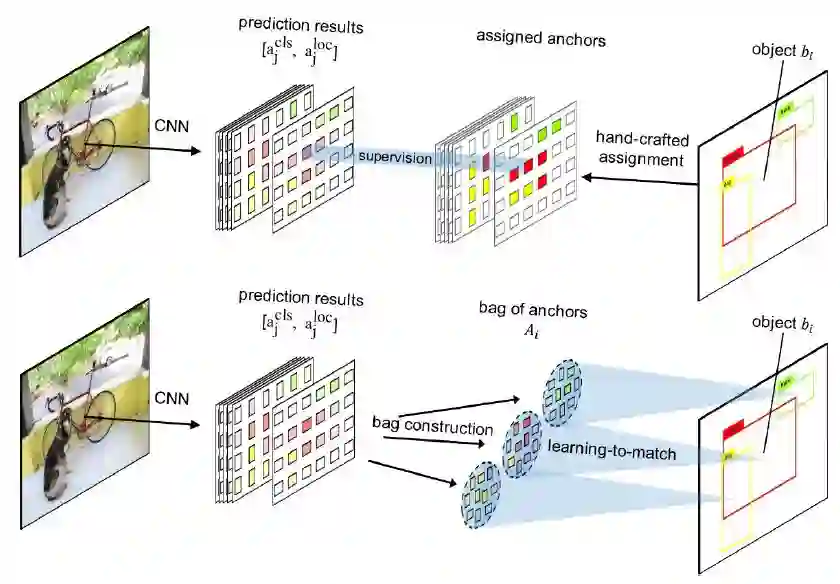
图1:hand-crafted anchor分配(顶部)和FreeAnchor(底部)的比较。
FreeAnchor允许每个目标在检测器训练期间从一组anchors中灵活匹配最佳的anchor。
方法





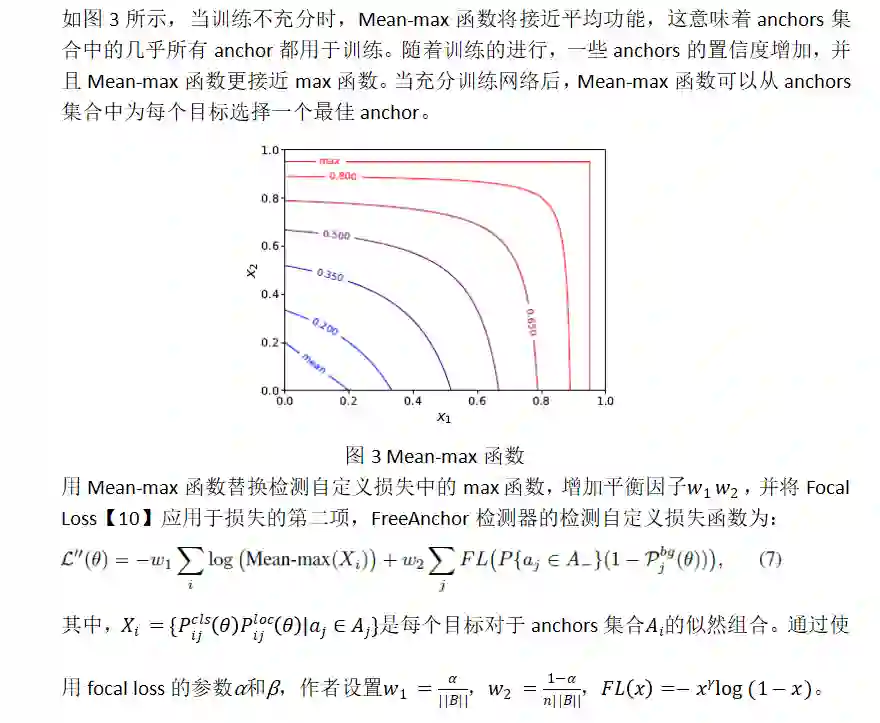
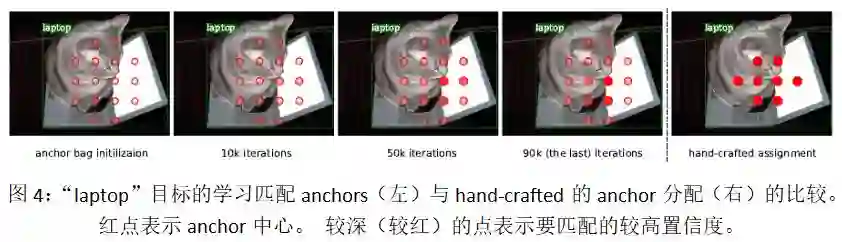
实验
• 模型效果(Model Effect)
如图5所示,对于方形目标类别, FreeAnchor的性能相当于RetinaNet。但在细长目标上,FreeAnchor性能明显优于RetinaNet。其原因在于,FreeAnchor激活每个目标的anchors集合内的至少一个anchor,以便预测正确的类别和位置,且激活的anchor不一定与目标空间对齐,只需有对分类和定位的最具代表性的features。
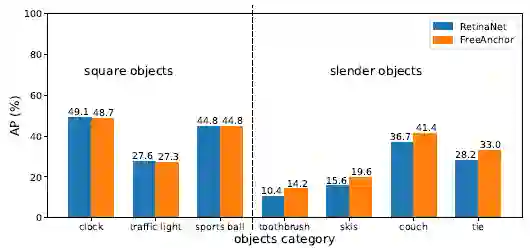
图5:正方形和细长对象的性能比较。
作者进一步比较了在各种拥挤情况下RetinaNet和FreeAnchor的性能,如图6所示。随着每个图像中目标数量的增加,FreeAnchor优势越来越明显。
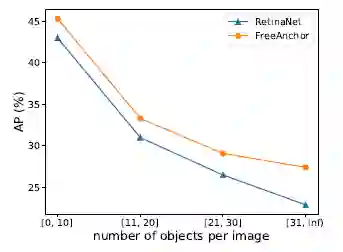
图6:目标拥挤情况下的性能比较。
为了评估anchors预测与NMS的兼容性,作者将NMS召回率NR_τ 定义为在给定IoU阈值τ下NMS前后的召回率之比。遵循COCO中AP的定义方式,NR定义为τ以0.05为间隔变化,从0.50到0.90中NR_τ 的平均值。实验结果如表1 所示,FreeAnchor的NR_τ 显著高于RetinaNet。

• 检测性能(Detection Performance)
表2为FreeAnchor与RetinaNet的性能比较,FreeAnchor可将AP提升3.0%左右,这对通用目标检测任务来说是一个显著提升。
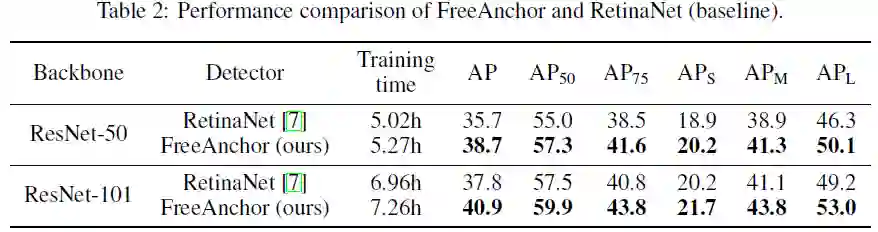
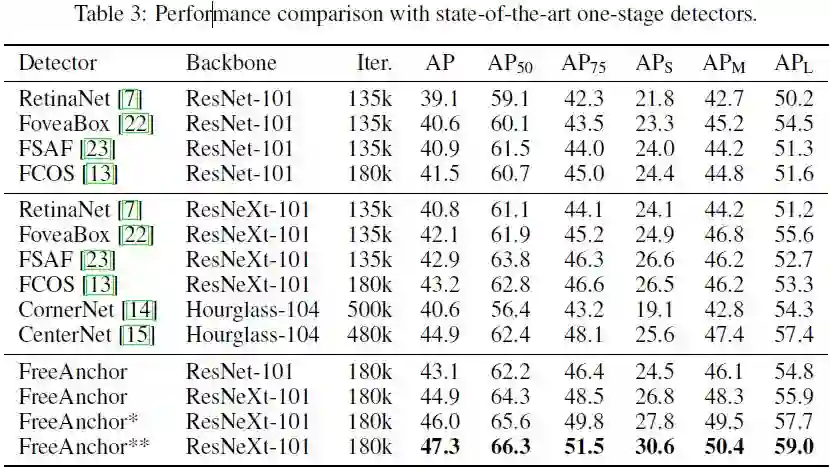
表3所示为FreeAnchor和其他方法的对比。FreeAnchor使用的ResNeXt-64x4d-101骨干网络少,训练迭代次数少,但在AP方面可与CenterNet相媲美(分别为44.9%和44.9%),尤其AP50性能更为突出。
总结
作者提出了一种用于视觉目标检测的FreeAnchor方法。FreeAnchor通过将目标检测器训练转换为最大似然估计(MLE)过程,将hand-crafted的anchor分配更新为“free”的目标与-anchor对应。实验结果表明,FreeAnchor显着提高了目标检测的性能。
参考文献:
【1】Xinyu Zhou, Cong Yao, He Wen, Yuzhi Wang, Shuchang Zhou, Weiran He, and Jiajun Liang. EAST: an efficient and accurate scene text detector. In IEEE CVPR, pages 2642-2651, 2017
【2】Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. Fcos: Fully convolutional one-stage object detection. arXiv: 1904.01355, 2019
【3】Hei Law and Jia Deng. Cornernet: Detecting objects as paired keypoints. In ECCV, pages 765-781, 2018
【4】Kaiwen Duan, Song Bai, Lingxi Xie, Honggang Qi, Qingming Huang, and Qi Tian. Centernet: Object detection with keypoint triplets. In IEEE CVPR, 2019
【5】Tong Yang, Xiangyu Zhang, Zeming Li, Wenqiang Zhang, and Jian Sun. Metaancho: Learning to detect objects with customized anchors. In NIPS, pages 320-330, 2018
【6】Jiaqi Wang, Kai Chen, Shuo Yang, Chen Change Loy, and Dahua Lin. Region proposal by guided anchoring. In IEEE CVPR, pages 2965-2974, 2019
【7】Borui Jiang, Ruixuan Luo, Jiayuan Mao, Tete Xiao, and Yuning Jiang. Acquisition of localization confidence for accurate object detection. In ECCV, pages 784-799, 2018
【8】Ross B. Girshick. Fast R-CNN. In IEEE ICCV, pages 1440-1448, 2015
【9】Joseph Redmon and Ali Farhadi. YOLO9000: better, faster, stronger. In IEEE CVPR, pages 6517-6525, 2017
【10】Tsung-Yi Lin, Priya Goyal, Ross B. Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In IEEE ICCV, pages 2999-3007, 2017



