【实战】GAN网络图像翻译机:图像复原、模糊变清晰、素描变彩图
1新智元专栏
作者:刘世强
【新智元导读】本文介绍深度学习方法在图像翻译领域的应用,通过实现一个编码解码“图像翻译机”进行图像的清晰化处理,展示深度学习应用在图像翻译领域的效果。

近年来深度学习在图像处理、音频处理以及NLP领域取得了令人瞩目的成绩,特别在图像处理领域,深度学习已然成为主流方法。本文介绍深度学习方法在图像翻译领域的应用,通过实现一个编码解码“图像翻译机”进行图像的清晰化处理,展示深度学习应用在图像翻译领域的效果。此外,由于神经网络能够自动进行特征工程,同一个模型,如果我们使用不同场景下的数据进行训练,便可适应不同的场景,真正实现了以不变应万变。在存在对偶关系的图像处理场景,不妨尝试一下“图像翻译机”方法,效果应该不会太差。最后我们介绍一下最近大热的生成对抗神经网络(GAN)在图像翻译的最新进展。
图像翻译,类似于语言翻译,是把一种图像转换为另一种图像,例如图像复原、把二维地图转换为三维地图、把模糊图像转换为清晰图像、把素描转化为彩图等等。在深度学习流行之前,进行图像翻译是一种state of art的工作,以图像复原为例,原来常使用滤波的方法,针对不同种类的退化图像,需要使用不同的滤波方案。而现在使用深度学习方法,只要训练数据足够多,方法简单粗暴但效果很好。下面这些图例都可以归为图像翻译的范围:

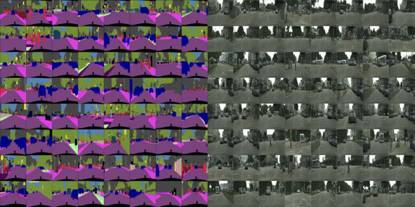
这里让我们构造一个简单的编码解码“图像翻译机”进行模糊图像的清晰化处理,项目地址:https://github.com/lsqpku/img2img。note: 本项目中的一部分代码来自于DCGAN项目(https://github.com/Newmu/dcgan_code)。
本文构造的“图像翻译机”参考了自编码神经网络的思想,自编码神经网络是一种无监督学习算法,通过编码-解码过程,使得输出尽量和输入相等,因此可以把自编码神经网络看作是一个恒等函数,关于自编码神经网络可参考斯坦福大学的教学资料http://deeplearning.stanford.edu/wiki/index.php/Autoencoders_and_Sparsity。我们把GAN中discriminator网络结构和generator网络结构重新组合起来,把discriminator改造为encoder,把generator改造为decoder,这样就建一个简单的图像翻译网络,网络结构如下:
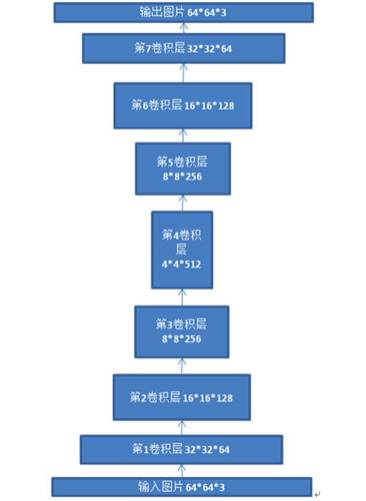
(作为示例项目,为减少计算量和过拟合,在网络结构中心并没有增加全连接的bottleneck层)其中encoder网络结构的tensorflow代码是:

其中卷积层后面挂着batch norm层进行正则化,卷积层激活函数是leaky relu。
generator网络结构tensorflow代码是:

其中卷积层后面挂着batch norm层进行正则化,激活函数是relu,最后进行了tanh激活。
这一结构类似于自编码神经网络,不同的是,在训练这个翻译网络的时候,输入和输出图像属于不同的域。例如在训练一个模糊图像清晰化的神经网络时,输入的训练样本是模糊图像,输出是清晰化后的图像,输出图像要尽量和对应的清晰图像接近,因此训练样本是模糊图像加对应的清晰图像。
示意图,输入模糊图像,输出清晰图像:

对于损失函数,我们简单地使用了输出图像和原图像的L2 loss作为损失函数。
self.loss = tf.nn.l2_loss(self.G - inputs)
我们使用了wiki 人脸数据(https://data.vision.ee.ethz.ch/cvl/rrothe/imdb-wiki/)进行训练,删除原始数据集中的黑白图片,并把人脸按照性别分开,本项目使用男性人脸数据进行训练。此外,为了得到模糊图像,我们分别对原始图像进行了高斯模糊、随机高斯模糊以及先缩小再放大到原尺寸的resize模糊,模糊图像和原始图像一一对应,这样就得到一大批对偶的模糊-清晰图像训练集(超过2万张图片)。理论上我们可以使用任何图片数据集进行训练和测试,但是需要注意训练数据的样本量,对于上述的模型,当图片数量不超过1000时,会导致明显的过拟合,建议训练样本在上万张以上。对于测试数据,我们使用了男性人脸、女性人脸、甚至建筑物进行测试。
前面第一副图像以及下图都是使用该神经网络对男性测试样本进行的清晰化处理,从处理效果看,虽然并不完美,但清晰化程度已大大提高(从左到右:原图像、模糊化后的图像和通过模型清晰化的图像)。

那么使用男性人脸训练的模型对女性测试样本进行清晰化处理效果如何呢?下图是女性测试样本的处理效果(同样对女性样本进行高斯模糊),和男性处理效果差不多(从左到右:原图像、模糊化后的图像和通过模型清晰化的图像)。

开一下脑洞,对非人脸样本的处理效果如何?下图是对一些非人脸图片的测试效果(同样是先进行了高斯模糊),发现效果也是比较好的,但是色系发生了变化,从冷色调转变为人脸色调(从左到右:原图像、模糊化后的图像和通过模型清晰化的图像)。

把上图转为灰度图像,清晰化效果看起来更明显一些(从左到右:原图像、模糊化后的图像和通过模型清晰化的图像):

然而,高斯模糊只是模糊方法的一种,使用高斯模糊图像进行训练的模型是否适用于其他模糊方案(例如先resize原图像的1/16,再resize回原尺寸)?下图是对resize模糊方案处理过的测试样本的测试效果(左图为对高斯模糊图像进行清晰化后的效果,右图为对resize模糊图像进行清晰化后的效果)。

可以看出使用高斯模糊图像训练的模型在处理resize模糊图像效果变差,但这是可以解释的,深度学习本质上还是一种模式识别,使用高斯模糊的训练样本,模型会找到高斯模糊的模式。为了使得模型也能够处理resize模糊图像,我们可以把两种样本都作为训练样本进行训练,试验表明对两种情况的清晰化都会比较好,这就是深度神经网络的强大之处,模型的capacity可以很大,通过增加测试样本和模型规模,一个模型可以处理更复杂的情况。
上面的模型只是一种神经网络简单的应用,由于模型的损失函数是简单的L2-loss,因此会造成图像模糊化的效果。为了使图像变得更加真实并减少对训练样本量的依赖,有人使用GAN进行图像翻译,这里介绍几个比较不错的案例:
1. pix2pix
article: https://arxiv.org/abs/1611.07004
repo:torch版本https://github.com/phillipi/pix2pix;
tensorflow版本:https://github.com/affinelayer/pix2pix-tensorflow)
这篇文章的创新之处在于两点:一是generator的损失函数除了判别真伪以外,加入了L1损失;另一个技巧是在判别真伪时,不是在整个图像范围内判别,而是把图片按patch进行判别,作者称之为patchGAN。经过对比测试发现,在人脸数据上这个模型的效果和上面的基础模型差别不大,但是在facades和citycapes等数据集上,效果看起来要更真实(由于facades和citycapes数据集很小,我们的模型出现了过拟合现像)。
2. CycleGAN
article: https://arxiv.org/pdf/1703.10593.pdf repo:https://github.com/hardikbansal/CycleGAN
基础模型以及pix2pix模型要求配对的训练样本,但是实际上常常很难找到大量的此类样本,CycleGAN的作者提出了另一种GAN变种, 主要贡献在于发挥无监督学习的作用,只要提供两类数据集即可,不要求严格配对(比如普通马转斑马)。模型较复杂(需要用到2个判别器和两个生成器),感兴趣的可参阅https://hardikbansal.github.io/CycleGANBlog/
3. DualGAN
Article: https://arxiv.org/abs/1704.02510
把对偶学习思想和GAN结合起来,思路和上面的CycleGAN有点类似,也用于解决训练样本不足的问题,用到两套GAN,一套GAN生成的图像作为另一套GAN的输入网络结构如下。
总的来说,使用神经网络进行图像翻译,简单高效,结合GAN网络,只要较少的训练样本就可以让生成图像非常逼真,大家可以尝试在更多图像对偶场景下应用图像翻译的思路,发挥深度学习的威力。
(本文作者是泰康保险集团数据信息中心刘世强)
【号外】新智元正在进行新一轮招聘,飞往智能宇宙的最美飞船,还有N个座位
点击阅读原文可查看职位详情,期待你的加入~



