图像分类器结构搜索的正则化异步进化方法
最近神经网络的成功不断扩展着模型的架构,并促成了架构搜索的出现,即神经网络自动学习架构。架构搜索的传统方法是神经演化,如今,硬件的发展能实现大规模的演变,生成可以与手工设计相媲美的图像分类模型。但是,新的技术虽然可行,却无法让开发者决定在具体的环境下(即搜索空间和数据集)使用哪种方法。
在本篇论文中,研究人员使用流行的异步进化算法(asynchronous evolutionary algorithm)的正则化版本,并将其与非正则化的形式以及强化学习方法进行比较。硬件条件、计算能力和神经网络训练代码都相同,在这之中研究人员探索在不同的数据集、搜索空间和规模下模型的表现情况。以下是论智对论文的编译总结。
实验方法
我们使用不同的算法搜索神经网络分类器的空间,进行基线研究后,所得到的最好的模型将被扩大尺寸,以生产更高质量的图像分类器。我们在不同的计算规模上执行搜索过程。另外,我们还研究了非神经网络模拟中的进化算法。
1.搜索空间
所有神经进化和强化学习实验都使用基线研究的搜索空间设计,它需要寻找两个类似于Inception的模块体系结构,这两个结构在前馈模式中堆叠以形成图像分类器。
2.架构搜索算法
对于进化算法,我们使用联赛选择算法(tournament selection)或正则化的变体。标准的联赛选择算法是对训练模型P的数量进行周期化的改进。在每个循环中,随机选择一个S模型的样本。样本的最佳模型将生成具有变化架构的另一模型,它将被训练然后添加到模型样本中。最差的模型将被删除。我们将这种方法称为非正则进化(NRE)。它的变体,正则化进化(RE)则是一种自然的修正:无需删除样本中最差的模型,而是删除样本中最老的模型(即第一个被训练的模型)。在NRE和RE中,样本初始化的架构都是随机的。
3.实验设置
为了对比进化算法和强化学习算法,我们将在不同的计算规模上进行实验。
小规模试验
首先进行的实验可以在CPU上进行,我们部署了SP-I、SP-II和SP-III三种搜索空间,利用G-CIFAR、MNIST或者G-ImageNet数据集进行实验。
大规模实验
然后再部署基线研究的设置。这里仅用SP-I搜索空间和CIFAR-10数据集,两种模型各在450个GPU上训练将近7天。
4.模型扩展
我们要将进化算法或强化学习发现的架构转化为全尺寸、精确的模型。扩展后的模型将在CIFAR-10或ImageNet上进行训练,程序与基线研究的相同。
实验结果
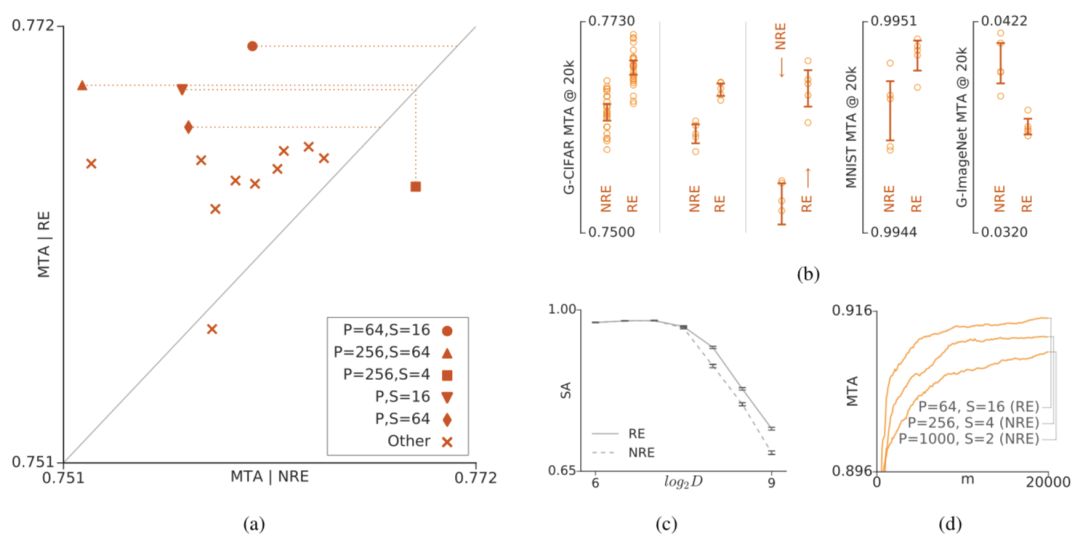
正则化与非正则化进化的对比。(a)表示在G-CIFAR数据集上非正则化进化和正则化进化用不同的元参数进行的小规模实验结果对比。P代表样本数量,S代表样本大小。(b)表示NRE和RE在五种不同情况下的表现,从左至右分别为:G-CIFAR/SP-I、G-CIFAR/SP-II、G-CIFAR/SP-III、MNIST/SP-I和G-ImageNet/SP-I。(c)表示模拟结果,竖轴表示模拟的精确度,横轴表示问题的维度。(d)表示在CIFAR-10上进行的三次大规模试验。
接着,我们在不同的情况下对强化学习和进化算法进行了小规模实验,结果如下:
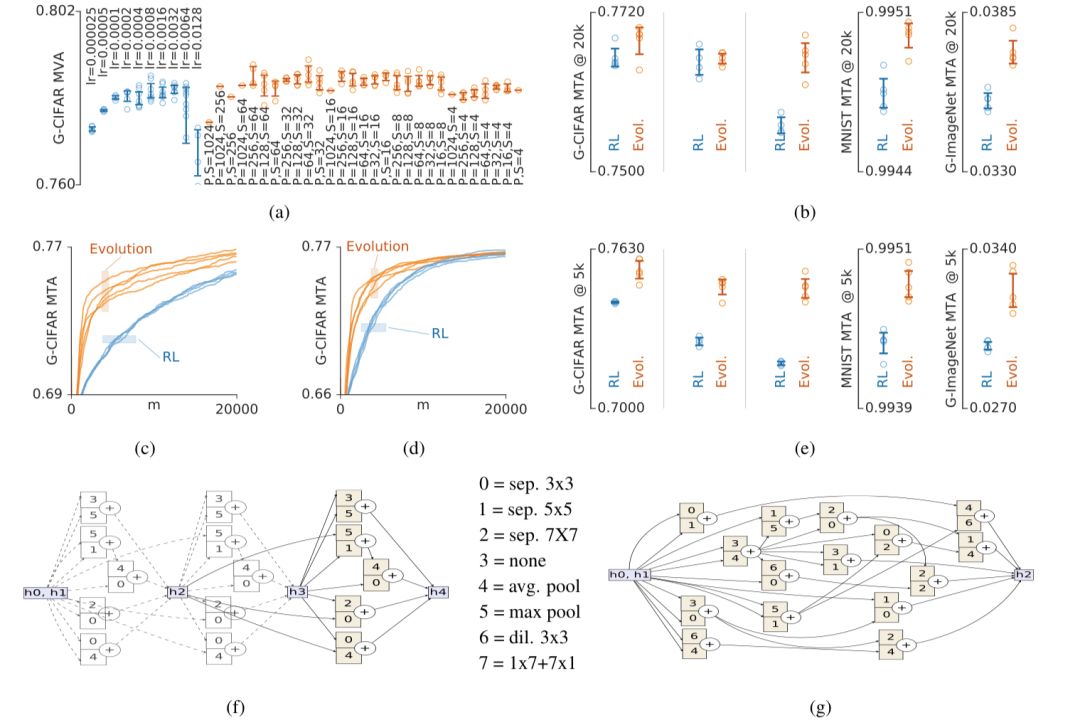
(a)显示了在G-CIFAR上对超参数进行优化的实验总结,竖轴表示实验中前100名的模型的平均有效精度。结果表明所所有方法都不够敏感。(b)同样是在模型五种不同情况下的表现:G-CIFAR/SP-I、G-CIFAR/SP-II、G-CIFAR/SP-III、MNIST/SP-I和G-ImageNet/SP-I。(c)和(d)表示模型分别在G-CIFAR/SP-II和G-CIFAR/SP-III上的表现细节,横轴表示模型的数量。(e)表示在资源有限的情况下,可能需要尽早停止实验。说明了在初始状态下,进化算法的精确度比强化学习增长得快得多。(f)和(g)分别是SP-I和SP-III最顶尖的架构。
比较完小规模实验,接着进行的是大规模实验。结果如下图所示,黄色代表进化算法,蓝色代表强化学习:
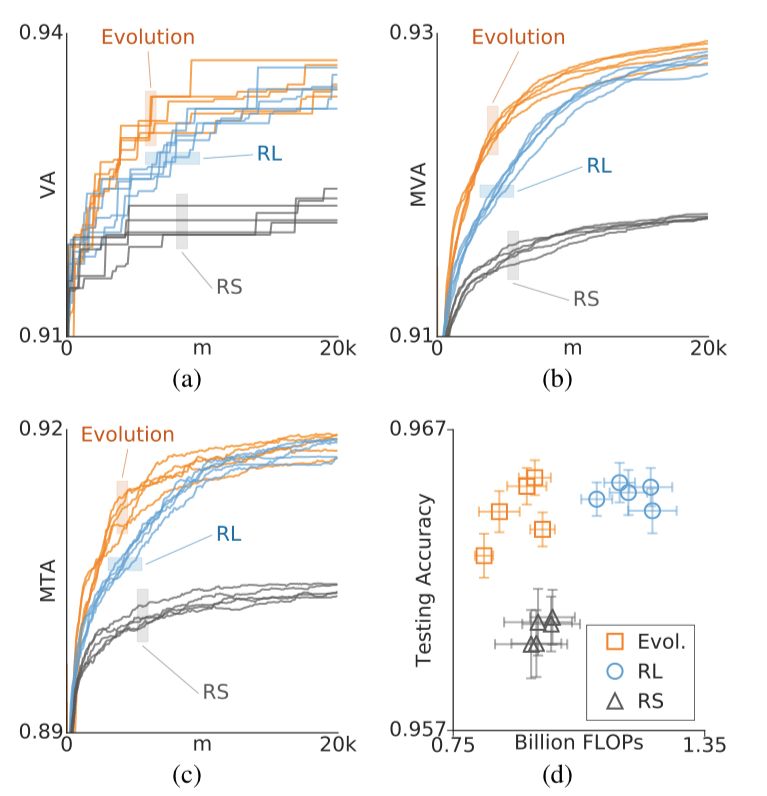
除了(d)图,所有横轴均表示模型的数量(m)。(a)、(b)、(c)三图分别展示了三种算法在五次相同实验的情况,进化算法和强化学习实验使用了最佳元参数。
经过进化实验,我们确定了最佳模型并将其命名为AmoebaNet-A。通过调整N和F,我们可以降低测试错误率,如表1所示:
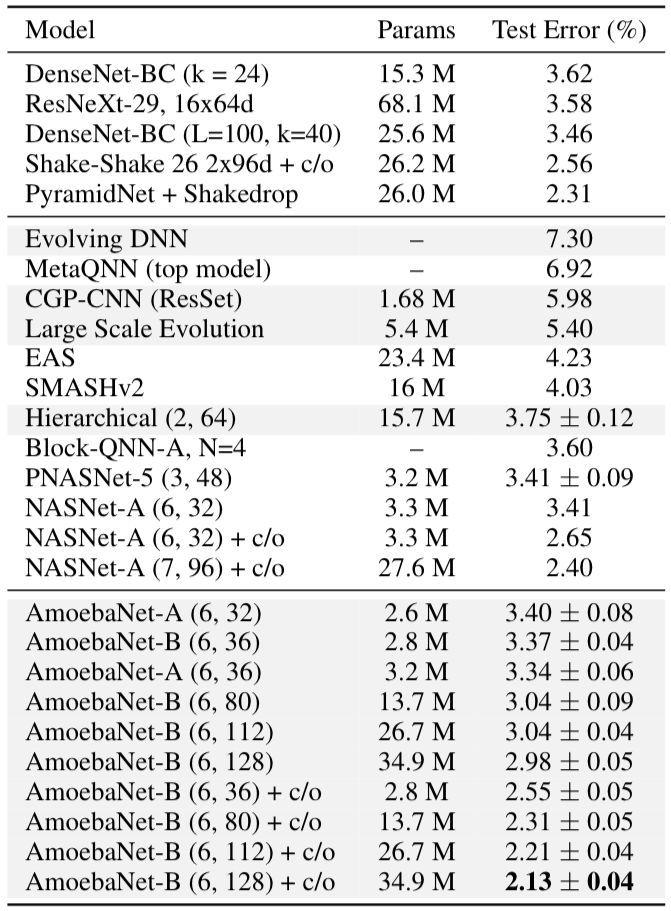
在相同的实验条件下,基线研究得到了NASNet-A。表2显示,在CIFAR-10数据集中,AmoebaNet-A在匹配参数时错误率较低,在匹配错误时,参数较少。同时在ImageNet上的表现也是目前最好的。
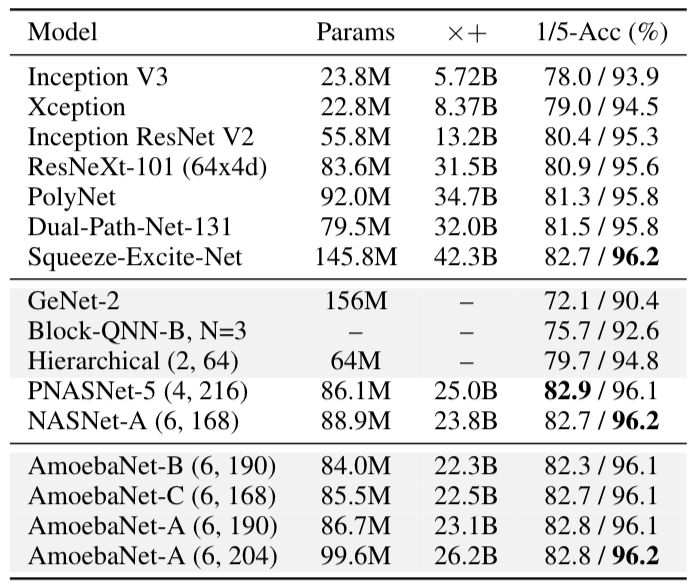
最后我们对比了手动设计、其他架构以及我们模型的性能对比,准确率均高于其他两种。
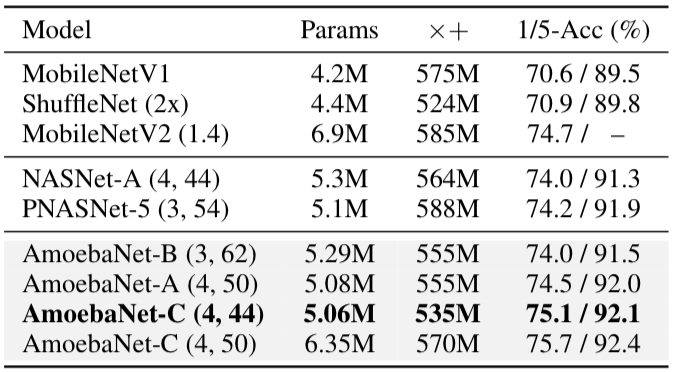
结语
大规模的实验过程图表明,强化学习和进化算法都接近一般精度渐近线,所以我们需要关注的是哪个算法更快到达。图中显示强化学习要用两倍的时间到达最高精度的一半,换句话说,进化算法的速度大约比强化学习快一倍。但是我们忽略了进一步量化这一效果。另外,搜索空间的大小还需进一步评估。大空间所需专业资源较少,而小空间能更快更好地获得结果。因此,在较小空间中很难区分哪种搜索算法更好。
不过,这一研究仅仅是在特定环境下分析进化算法和强化学习之间关系的第一个实证研究,我们希望今后的工作能进一步总结二者,阐释两种方法的优点。
原文地址:arxiv.org/pdf/1802.01548.pdf





