AI不是万灵神药!看看普林斯顿大学的这份“假AI防骗报告”
新智元报道
新智元报道
来源:cs.princeton.ed
编辑:小芹、大明
【新智元导读】普林斯顿大学教授最新报告《如何区分AI“万灵假药”》近日火了,很多宣称采用AI算法预测社会后果的技术,实际不比线性回归模型好多少。你怎么看AI“万灵假药”?来新智元 AI 朋友圈和AI大咖们一起讨论吧。
AI不是万灵药,但越来越多的人把它说成是万灵药,在这些人的鼓吹下,更多的人可能真的会把AI当成万灵药。
那么,如何在周围人都在吹的氛围下冷静下来,分辨真假?近日,普林斯顿大学计算机系Arvind Narayanan副教授撰写了一份报告,题目就是《如何区分AI“万灵假药”》。

报告全文要点如下:
1、有很多与AI无关的东西都被打上AI标签,目前已经诞生的真正的、有社会影响力的AI技术无意间充当了这些冒牌货的保护伞。
2、很多宣称采用AI算法的技术涉及对社会后果的预测。事实是,我们并不能预测未来,但当涉及AI时,这个常识似乎就我们无视了。
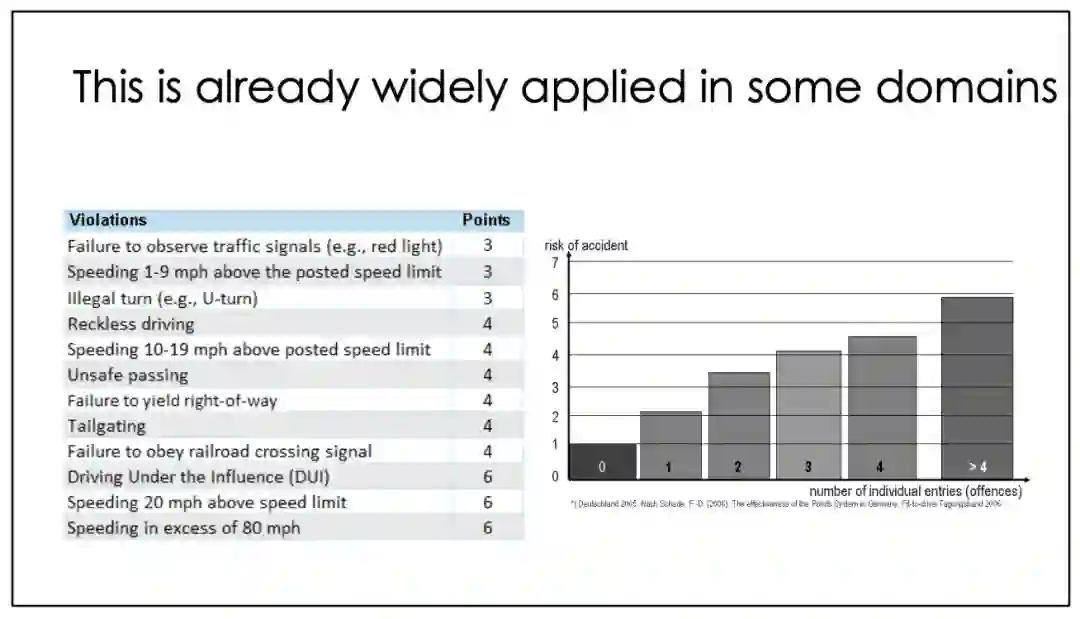
3、在风险行为预测上,手动评分要比AI评分靠谱得多。比如违规驾驶,人工计分,到一定程度吊销驾照,这个计分还是要交给人来做。
作者首先举了个例子。下边这个网站宣称,只用一段30秒的短视频,就能评估出你的职业前途和工作的稳定程度。听起来是不是很神奇?只要拍一段视频传上去,网站就会自动评估出多个指标,可视化呈现后给出一个综合评分。
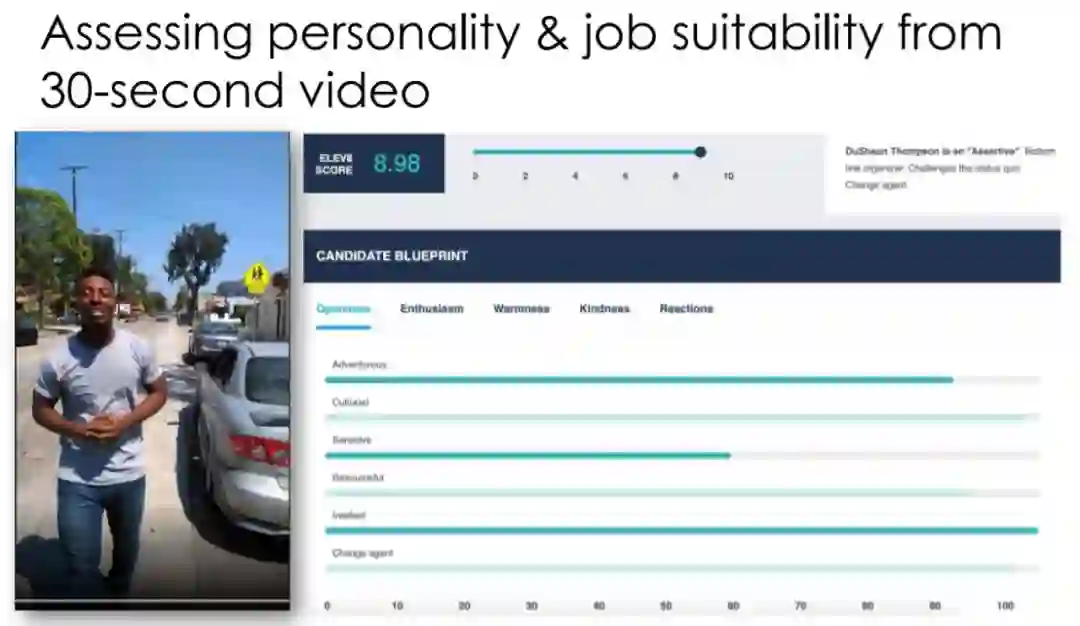
它声称,评估分数结果和视频中的你说的内容甚至都没关系,完全是AI算法根据肢体语言、讲话的方式和风格这些东西得出的。
而实际上,这只是个加了外壳的“随机数生成器”。你的职业是否稳定,全看运气。
为什么这种包装成AI的假货这么多?
第一、 现在的“AI”是个时髦的保护伞,和AI沾边可以提升身价。
第二、 一些AI技术确实实现了真正的、获得大众认可的巨大进步。
第三、 大部分群众不懂AI,企业可以把任何东西贴上AI标签,再卖出去。
这个例子只是说明在HR领域的问题,实际上在其他领域内,这种对AI技术的故意夸大的现象可能更严重。在这份报告中,作者将现在的AI应用模式大体分为3类。

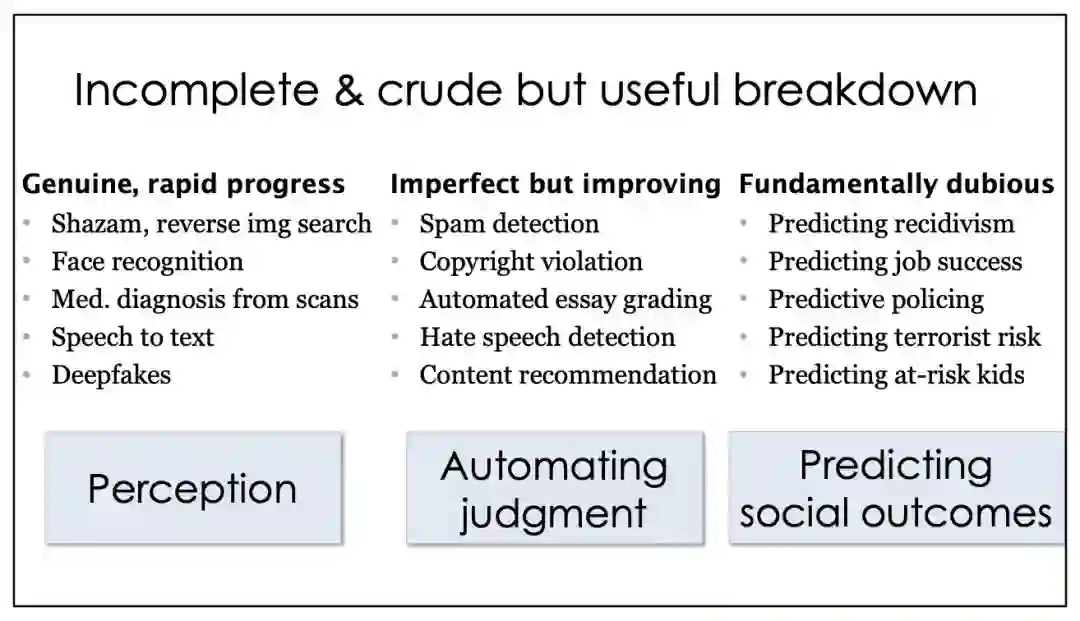
第一类:认知类AI技术。主要包括内容识别(包括反图片搜索)、人脸识别、基于医疗影像的辅助诊断、文本-语音转换,以及DeepFake等。作者认为,这类技术基本上属于货真价实的快速技术进步,甚至DeepFake的过于逼真表现还引发了人们在道德上的担忧。
作者认为,这类AI技术造假或吹牛空间不大的主要原因是结果和判断标准的确定性。无论是人脸识别还是文本-语音转换,其对错标准是非常明确的。

第二类:自动化判断类AI技术。包括垃圾邮件检测、盗版内容检测、论文自动评分、内容推荐等。这类应用尽管还远远称不上完善,但是正在进步,应用前景在逐步拓宽。
对于这类AI来说,判断标准开始变得有些模糊,一篇文章写得好不好,一封电邮是不是垃圾邮件,对于这些问题,不同的人可能会有不同的看法,AI会逐步学习人类的判断和推理方式,但往往免不了犯错。

第三类:社会后果预测类AI。包括职业表现预测、惯犯行为预测、政策预测、恐怖袭击预测等。作者认为,这类AI基本上其真实性都是值得怀疑的。
作者认为,在我们自己尚且不能预测未来的情况下,却要把这个任务交给AI,并根据结果来制定政策,这种选择有违常识,而且很可能造成不良后果。
AI预测社会后果?效果比线性回归好不了多少
第三类AI应用有关预测社会后果,它们大多数时候从根本上就是可疑的:
预测犯罪惯犯
预测工作表现
预测警务
预测恐怖主义风险
预测问题儿童
Shazam(一款音乐识别应用)
反向图片搜索
人脸识别
基于医学成像的医疗诊断
语音转文本
Deepfakes
垃圾邮件检测
版权侵犯
自动论文评分
仇恨语音检测
内容推荐
预测累犯
预测工作成功
预测警务
预测恐怖主义风险
预测问题儿童

“脆弱家庭(未婚家长与孩子组成的家庭)与孩子福利”项目跟踪研究了1998-2000年出生在美国大城市的近5000名儿童(大约四分之三是未婚父母所生),这些儿童所在的“家庭”比普通家庭面临更大的分裂和贫困的危险。研究围绕四个方面展开:(1)未婚父母,尤其是父亲的条件和能力是什么?(2)未婚父母关系的本质是什么?(3)这些家庭出生的孩子是怎样生活的?(4)政策和环境条件如何影响这样的家庭和儿童? 该项目的人口研究数据档案办公室公开提供六组相关数据。

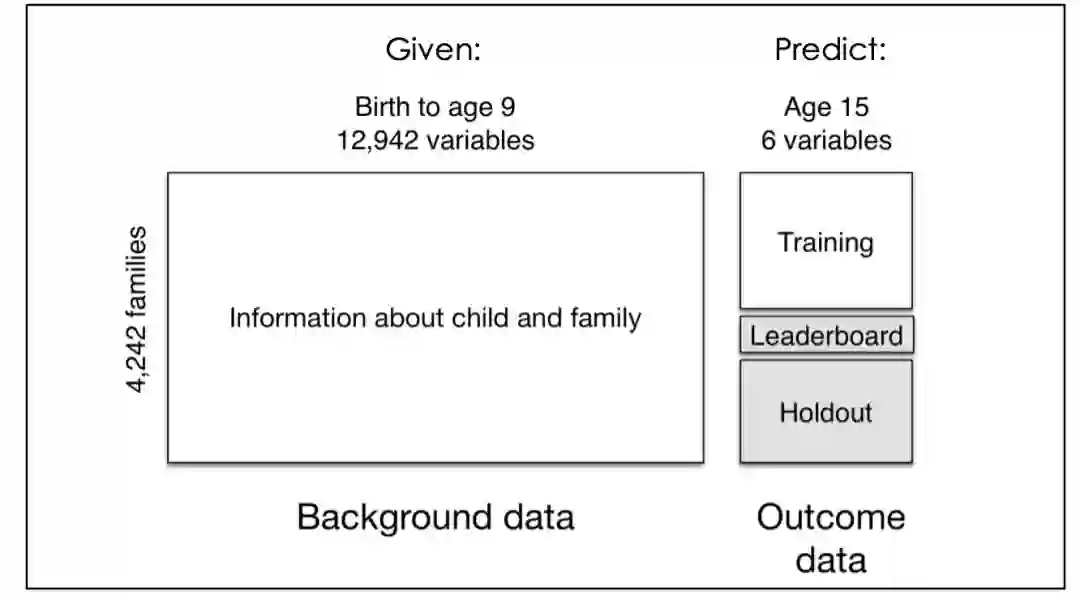
孩子的平均成绩(学业成绩)
孩子们的勇气(激情和毅力)
家庭的物质困难(衡量极端贫困的程度)
驱逐家庭(不支付租金或抵押)
照顾者的裁员
工作培训(如果主要照顾者将参加工作技能计划)
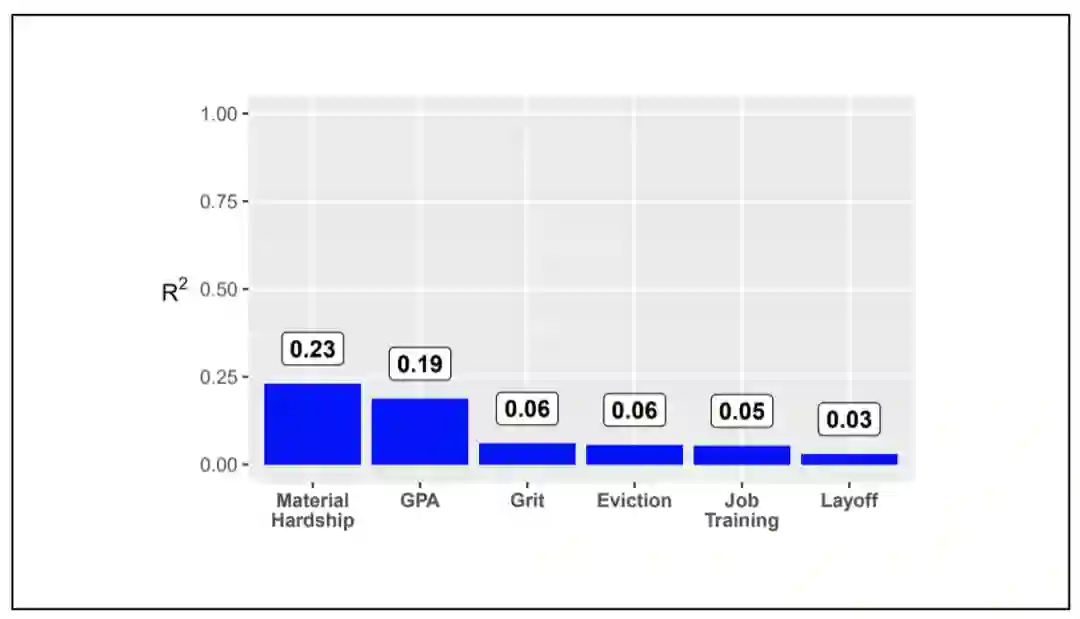
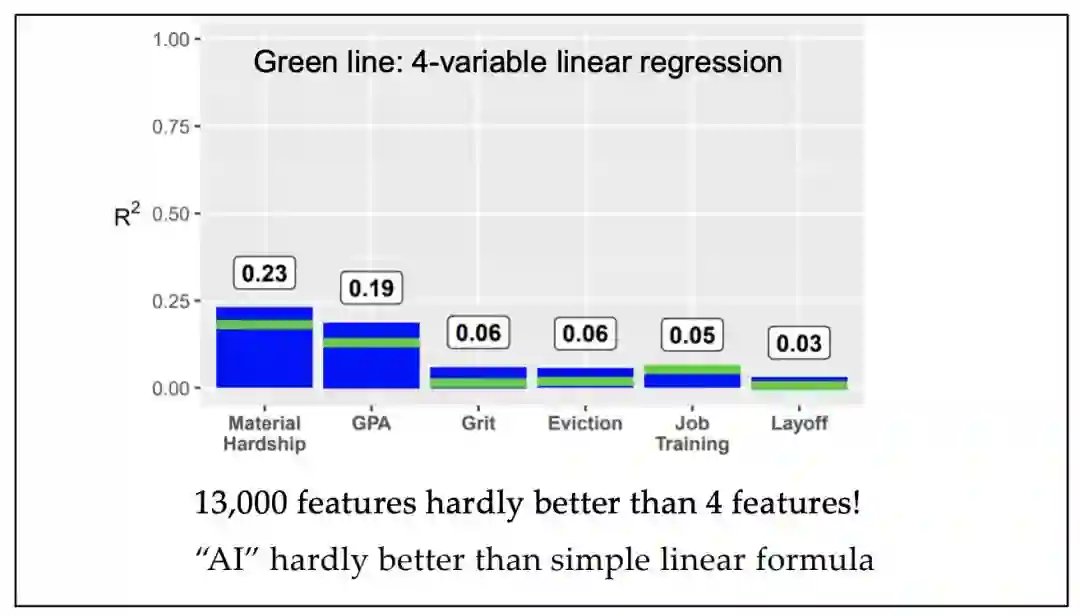


对个人数据的需求
权力从领域专家大规模转移到不负责任的科技公司手中
缺乏可解释性
影响干预
准确性流于表面
……
人工智能擅长某些任务,但无法预测社会后果。
我们必须抵制意图混淆这一事实的巨大商业利益。
在大多数情况下,手动评分规则同样准确,更加透明,值得考虑。

新智元AI朋友圈详细使用教程,8000名AI大玩家和实践者都在这里!



