![]()
本文约5300字,建议阅读10分钟。
本文为大家介绍了 ACL 学会的工作进展,NLP 领域的技术趋势以及未来重要的发展方向。
[ 导读 ] 7月29日,ACL 2019在意大利佛罗伦萨开幕。在开幕仪式上,ACL 主席、微软亚洲研究院副院长周明博士做了主题演讲,为大家介绍了 ACL 学会的工作进展,NLP 领域的技术趋势以及未来重要的发展方向。
大家好,欢迎大家来到美丽的佛罗伦萨参加 ACL 2019大会。提起佛罗伦萨,人们很自然地会联想到文艺复兴,这场改变了世界文明的文化运动就是兴起于这里。很高兴 ACL 会议可以在这样一座暨拥有悠久而辉煌的历史又充满现代活力的城市举行。
图1:微软亚洲研究院副院长、ACL主席周明
在今天的演讲中,我想谈谈两个相互关联的话题:首先,我想总结一下 ACL 学会在2018年所取得的进展;然后,我来回顾一下近年来 NLP 领域的技术趋势,分析当前技术面临的挑战,并分享我对未来发展方向的一些看法。
国际计算语言学协会(ACL)是计算语言学(CL)和自然语言处理(NLP)领域最重要的国际学术组织。ACL 学会成立于1962年,最初为机器翻译和计算语言学协会(AMTCL),并于1968年更名为 ACL。ACL 的历史几乎就是 NLP 的历史,经历了许多起伏,从 NLP 早期基于规则的方法,到基于统计学习的方法,直到当前基于 DNN 的方法。经过几代人的努力,现在 NLP 已经形成了一套扎实的理论和先进的技术,并被广泛认为是人工智能的明珠。
目前,ACL 有三个区域性分会,包括1982年成立的欧洲分会(EACL)、2000年成立的北美分会(NAACL)和2018年成立的亚太分会(AACL)。ACL 还下设有21个特殊兴趣小组(SIGs),涵盖几乎所有重要领域。三大分会和许多 SIGs 都会举办年度会议或研讨会。
ACL 的日常运营机构是由13人组成的 ACL 执行董事会。从2011年开始,ACL 每年都会评选 ACL Fellow,以表彰他们对该领域的科学和技术贡献,以及为学会做出的巨大贡献。我很高兴地宣布,在2018年,有5名成员被选为 ACL Fellow——Robert Dale、Jason Eisner、Mari Ostendorf、Dragomir Radev、Ellen Riloff。
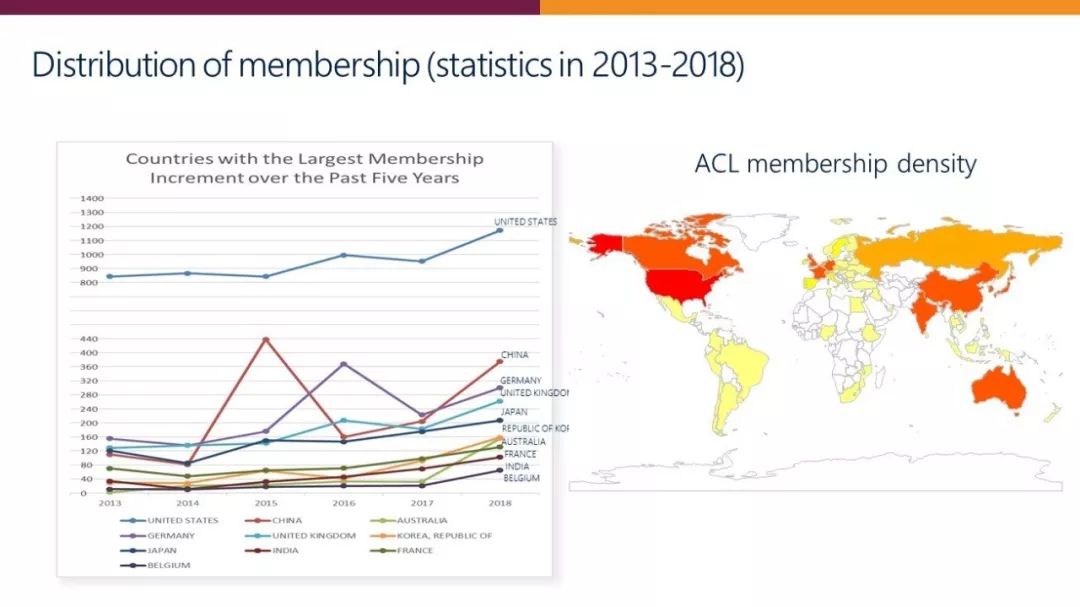
自2014年以来,ACL 会员数量在过去5年有了大幅增长。截止到2018年,包括普通会员和学生会员在内的会员总数比2015年增加了一倍,北美、欧洲和亚洲三个地区的会员数量均有大幅增长,而亚洲地区的增幅最大。
![]() 图2:ACL 会员增长趋势
图2:ACL 会员增长趋势
拥有 ACL 会员最多的十个国家和地区分别是美国、中国、德国、英国、日本、韩国、澳大利亚、法国、印度和比利时。但是,我们也看到成员的增长在不同国家相当不均衡。除了这10个国家,其他国家的增长相对缓慢,仍然有不少国家和地区成员很少甚至没有成员。除此之外,论文的接受情况在不同国家的不平衡问题也非常明显。
图3:ACL 会员的国家和地区分布
造成这种发展不均衡的原因包括:国家的政治和经济水平、英语语言障碍、缺乏足够的支持和帮助等。
近年来,由于会议数量、会议的主题数量、数据集数量、神经网络数量、算法数量、以及研究人员、教授和学生人数的激增,我们见证了 ACL 论文提交数量的暴涨,这也带来了巨大的挑战。作者会将被拒的论文稍作修改,甚至不做修改就重新提交到其他会议上,直至被接受。这造成了社会资源的巨大浪费。这个问题对论文评审系统、评审过程和审稿人提出了巨大挑战。
近20年来,我们共同见证了 ACL 和 NLP 在亚洲的快速发展,我想分享一下我对此的一些看法,希望能够对大家有所帮助。
亚洲许多国家和地区都拥有 NLP 协会,而亚洲自然语言处理联合会(AFNLP)将亚洲几乎所有 NLP 协会联系在一起,并且每两年举办一次 IJCNLP。此外,还有一些国家间的联合活动,例如自从2001年以来每年一度的中日联合 NLP 研讨会。还有其他亚洲国家之间的联合研讨会。这些研讨会有助于加强各国之间的交流,促进亚洲的人才发展。
亚洲国家和地区的每个 NLP 协会都会举办年度会议。比如,在中国,每年有两个 NLP 旗舰会议——中国计算机学会(CCF)举办的 NLPCC 和中国中文信息学会(CIPS)举办的 CCL。这两个学会每年还会联合举办语言与智能高峰论坛。
除了这些会议之外,微软亚洲研究院早在2002年发起了一个 NLP 暑期课程。次年开始与哈尔滨工业大学合作举办长达十年之久。这个暑期学校在5年前交由中国中文信息学会运营。这个暑期学校自从开办以来每年都邀请许多世界知名的研究人员做学术讲座。
ACL 大会先后在亚洲举办过七次,这极大地促进了促进亚洲 ACL 会员的增长,AACL 也应运而生。成立于2018年的 AACL 服务亚太地区57个国家和地区的 ACL 会员,明年计划举行首届 AACL 会议。AACL 的成立进一步推动了亚洲 NLP 的发展和 ACL 成员的增长。
ACL 学会一直致力于推动 NLP 领域的均衡、包容和多样化发展。为此,ACL 学会已经在以下6个方面做了很多努力,但是显然,我们还做得不够,在未来我们还需要更加多的投入。
-
-
ACL 学会及分会在培养学生方面,发挥积极的作用,包括提供更多的暑期学校和实习机会;
-
倡导 ACL 会议及分会会议在更多国家和地区举行;
-
为低资源语言开发相关数据、工具和应用程序,更好地帮助到这些国家和地区的研究者;
-
-
推进学会的 IT 系统建设,改进论文审稿系统以应对快速增长的投稿需求,加大区域分会之间、各类会议之间的统一协调。
目前已经成立了信息工作委员会、促进公平委员会、公共关系委员会、职业规范委员会、文库委员会。在明天下午的 ACL 学会业务工作会议上,大家可以听到 ACL 学会的各个职能机构的报告、各个区域分会的报告、未来的会议ACL 2020、ACL 2021的筹备情况的报告。此外还将有一个专门讨论论文评审的研讨会。请大家积极参加,献计献策。
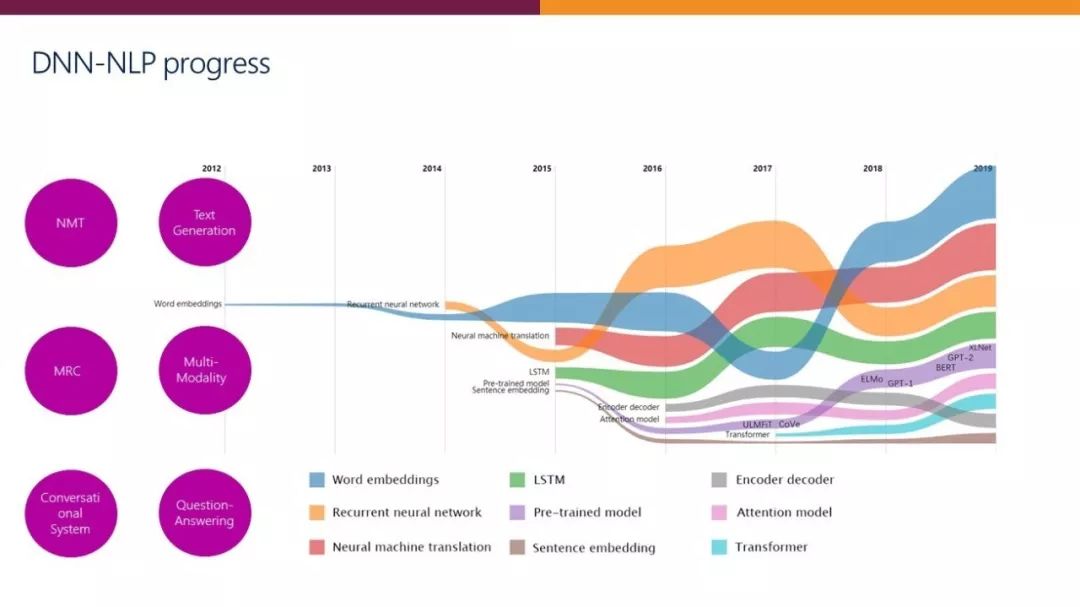
近年来,NLP 研究和技术发生了巨大变化。自2012年以来,最令人印象深刻的进展是基于深度神经网络的 NLP——DNN-NLP。目前,DNN-NLP 已经形成了一整套相关技术,包括词向量、句向量、编码器- 解码器、注意力机制、transformer 和各种预训练模型。DNN-NLP 在机器翻译、机器阅读理解、聊天机器人、对话系统等众多 NLP 任务中取得了重大进展。
图4:基于深度神经网络的 NLP 发展
词向量是表达单词含义的低维向量。2014年,Mikolov 提出了两种获取词向量的方法,一个是 CBOW(Continuous Bag-of-Words),用周围的词预测当前的词;另一个是 Skip-gram,用当前的词预测周围的词。通过大规模的学习训练,就可以得到每个词稳定的多维向量,作为它的语义表示。
有了词的语义表示,我们就可以进而生成句子的语义表示,也叫句子的编码。一般通过 RNN(循环神经网络)或者 CNN(卷积神经网络)来做。基于这样的表征,我们就可以用编码器-解码器将输入序列映射到输出语句。随后又引入了注意力模型和 Transformer,进一步提高编码器和解码器的性能。
目前大热的预训练模型以无监督的方式学习具有大语料库的语境词向量。ELMo、BERT、GPT 等模型已经被广泛使用。基于 BERT 和 GPT,人们又开发了一系列的新的方法,如 XLNet、UNILM、MASS、MT-DNN 和 XLM 等。
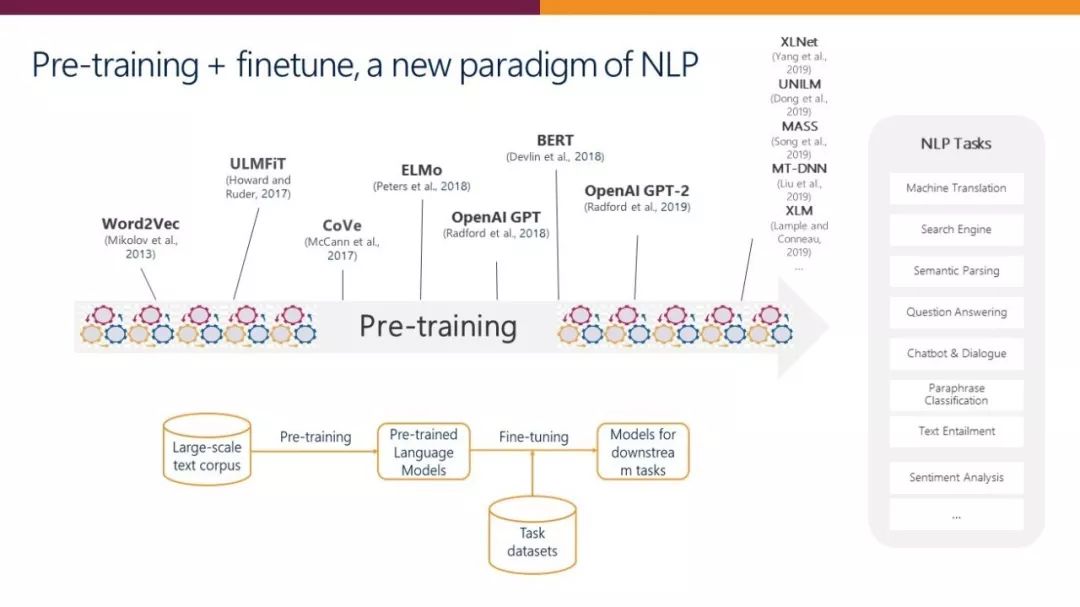
现在,已经形成了一种新的 NLP 范式——使用大规模文本语料库进行预训练,然后使用特定任务的小数据集进行微调。这种新范式使得研究人员能够专注于特定任务。适用于各种任务的通用端到端训练模型降低了每个 NLP 任务的难度,从而加快了创新步伐。
图5:NLP 新范式
但是,我一直在思考 NLP 的未来方向在哪里。DNN-NLP 的进展令人兴奋,然而,DNN-NLP 极大地依赖于算力和标记数据,并且在建模、推理和可解释性方面面临巨大挑战。
首先,研究人员面临许多数据问题,如数据偏差、侵犯用户隐私等。数据有隐含歧视的问题,通过数据分析,可能会得到歧视性的结果。
其次,计算资源的军备竞赛。AI 芯片的新军备竞赛使 AI 研究非常昂贵。预训练模型特别耗资源,但其产出并不总是与计算成本成比例。例如,根据 Strubell 的论文,使用1个 TPU v2芯片训练 NAS 需要大约15万美元,而与 Transformer big 相比,它只能带来0.2个 BLEU 改进。另外,太依赖算力还会对环境产生很大的影响。
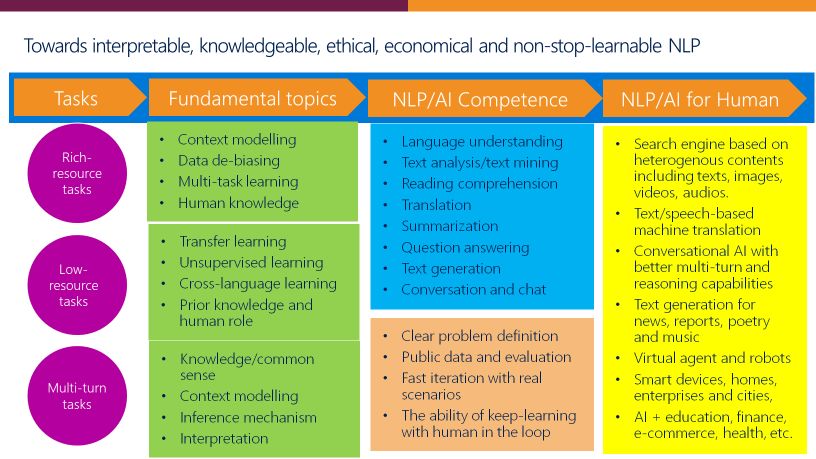
接下来,我们来仔细分析 DNN-NLP 模型在三个典型任务中的表现以及存在的问题。第一个是 Rich Resource Tasks,即有足够资源的任务;第二个 Low Resources Tasks,即资源很少或没有资源;第三个是 Multi-turn Tasks,就是多轮任务。
首先,针对资源丰富的 NLP 任务,我们以中英机器翻译为例说明目前存在的问题。首先做一个中-英神经网络机器翻译错误分析。
图6:大语料库训练出的中-英神经网络机器翻译错误分布
上图是9个大类的错误分布,其中翻错词、语法错误、丢词、实体转换是错误最集中的领域。此外,NMT 还在词序、事实、词重复、搭配等方面犯了错误。
所以即使在这样的足够资源的算法里面,仍然存在众多的问题要研究:
-
上下文建模。对较长的上下文进行建模,这对于文档翻译、跨文档摘要和聊天机器人等任务非常有用;
-
数据纠偏。解决训练和测试数据集的偏差问题,以获得更加鲁棒的模型;
-
多任务学习。了解不同任务之间的关系以及任务之间相互促进的方法;
-
人类知识的理解,将现有的语言知识和领域知识整合到模型中。
-
一些任务具有有限的训练数据,但它们与具有丰富训练数据的其他任务高度相关。对于此类任务,可以使用迁移学习作为解决方案;
-
有些任务在一个语言上的训练数据非常有限,但却有其他语言丰富的训练数据。此类任务可以使用跨语言学习;
-
对于既没有相关任务也没有其他语言训练数据的任务,无监督学习似乎是目前唯一的方法,利用种子进行迭代学习。
最后是多轮任务问题,多轮任务在处理常识和推理方面的能力较弱。举一个例子:
图7:计算机在多轮任务中缺乏常识和推理能力
在这个例子中,鉴于“ACL 2019在佛罗伦萨举行”的事实存储在知识库中,计算机可以回答第一个问题,而对于小孩子来说很简单的后三个问题,计算机却不知道该怎么回答。其原因在于目前的自然语言处理还没有很好地解决常识和推理的问题。
上下文、知识和推理算法在推理中起着关键作用:1)上下文提供诸如说过什么话,答过什么问题,干过什么事等信息;2)知识提供关于通过预训练从大规模语料库中学习的客观事实、常识和表征的一般信息;3)推理模块通过一系列推理步骤利用输入的上下文和知识库来获得结果。
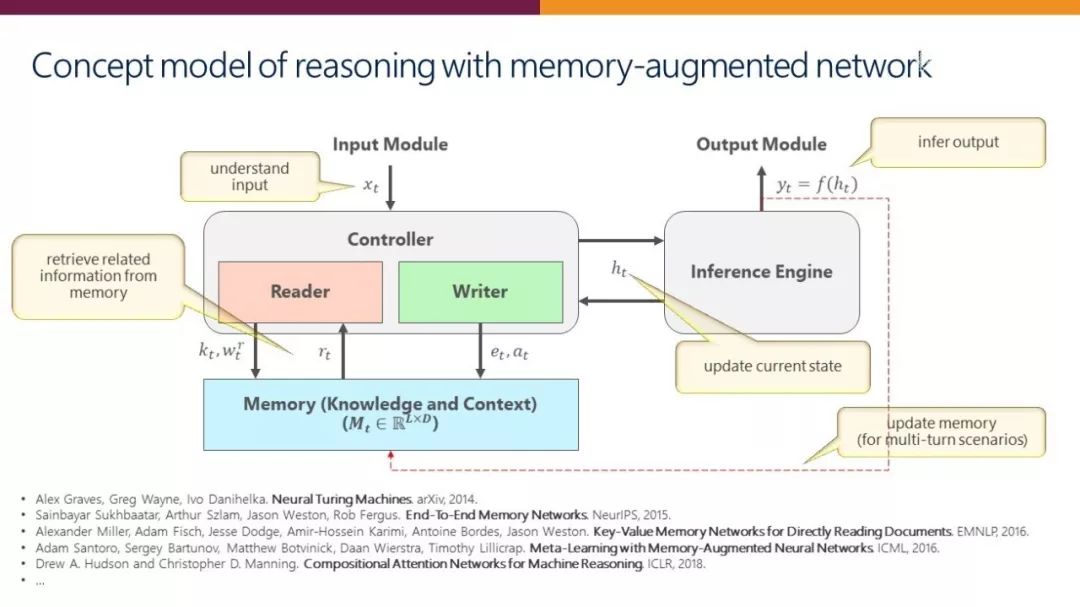
支持推理的典型框架称为“记忆增强神经网络(MANN)”。给定输入话语, MANN 首先通过将其转换为向量表示来理解它;然后,Reader 使用输入表示和先前状态从存储知识和上下文信息的存储器中检索相关信息;接下来,MANN 基于先前状态和检索到的信息更新当前状态,基于此,还通过整合当前状态的信息来更新存储器;最后,在几轮迭代之后,推理引擎得到最终输出结果,该输出结果也将用于更新存储器以支持下一轮的理解。
图8:MANN 网络架构
-
-
-
-
如何使神经模型可解释?这对于调试和改进这些模型非常重要。
我们未来到底需要什么样的自然语言处理系统呢?我认为要做出可解释、有知识、有道德、可不断学习的 NLP 系统。要实现这一目标还有很长的路要走,但我们可以从刚才提到的三项任务的难题开始。
图9:NLP 的未来之路
对于基础任务,我认为其中的关键问题是需要为各种模型的构建训练和测试数据集。在设计良好的数据集上,每个人都可以提出新的方法,不同的模型之间可以相互竞争。
如果在这些任务上有所推进的话,我们的认知智能就会进一步提升,包括语言的理解水平、推理水平、回答问题能力、分析能力、解决问题的能力、写作能力、对话能力等等。然后再加上感知智能的进步,声音、图象、文字的识别和生成的能力,以及多模态文、图交叉的能力,通过文字可以生成图象,根据图象可以生成描述的文字等等,我们就可以推进很多应用的落地,包括搜索引擎、智能客服、AI教育、AI金融等等各个方面的应用。
在这里,我想强调两个重要的方向:1)深度学习和语言学应该相互促进。虽然对此存在一些争论或疑虑,但我相信总有一种方法可以让这两者互相提升。例如,深度学习模型可以找到隐藏的句法树结构,而语言规则可用于帮助标注数据,然后用于训练神经网络;2)多模态为 NLP 打开了一个新的世界。NLP 可以与图像处理和语音处理相结合,以便更好地进行搜索、QA 等多模态处理。其他模态的算法可以帮助 NLP 任务,而 NLP 的新算法也可以扩展到其他模态。
在数据、算力和新算法(尤其是 DNN-NLP)的支持下,我们正处于 NLP 的黄金时代,但我们还有很长的路要走。NLP 的可持续发展需要算力、数据、模型、人才、合作和应用程序这六个重要支柱。
-
计算能力
:继续加大在芯片、计算能力、管理、模型压缩和加速度等的研发投入;
-
数据
:鼓励人们提供更多的开源数据和共享任务,找到有效的数据收集、数据标注、数据纠偏和去噪的方法,并进行隐私保护学习的研究;
-
模型
:继续研究新的学习方法,包括监督学习、半监督学习、无监督学习等,改进各种预训练模型,将神经网络和知识结合以获得更好的推理和可解释性能力;
-
人才
:NLP 的下一代人才应该以新的方式接受培训。我们应该改革课程体系,加强系统建设能力,鼓励学生参加国际学术会议和国际交流,以获得国际视野;
-
合作
:我们应该加强大学与产业的合作,促进跨学科合作和国际合作;
-
应用
:学术研究人员应该了解实际应用场景,牢记以结果为导向的解决问题的思维方式,了解人和机器在一个真实的系统里如何相得益彰、互相配合,实现人工智能和人类智能的双向结合。NLP 研究人员还应该知道如何进行市场分析和商业模式研究,能及时调整自己的研究方向。
通过我们所有人的共同努力,我们将拥有一个既有竞争又有合作的良好发展环境,共同应对 NLP 的挑战。
最后我引用文艺复兴时代伟大诗人但丁的名句作为结尾:
我们一起攀登,直到我透过一个圆洞看得见一些美丽的东西显现在苍穹。我们于是走出这里,看见了满天繁星。
让我们大家一起努力拥抱 ACL 和 NLP 的光明未来。
演讲PPT链接:
https://www.msra.cn/wp-content/
uploads/2019/08/ACL-MingZhou.pdf


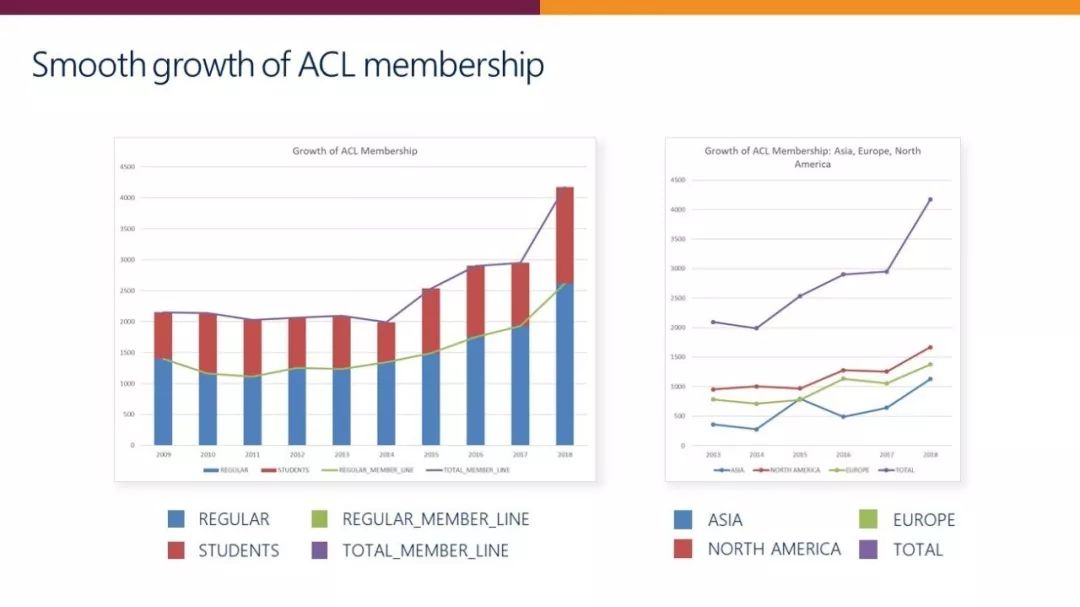 图2:ACL 会员增长趋势
图2:ACL 会员增长趋势