【知识图谱】在刚刚结束的ACL 2019上,知识图谱领域都发生了哪些大事?
选自medium
对知识工程的研究贯穿于整个人工智能的发展史。 作为目前最为火热的先验知识组织、表征技术,知识图谱的相关工作在本届 ACL 上可谓万众瞩目。 本文将介绍本届 ACL 收录的一些知识图谱方向的优秀工作,希望对读者们有所启发。

说到对这种技术的预期,没有比 ACL 主席周明本人解释的更清楚了 - 在欢迎辞中,他强调了将知识图谱,推理和上下文融入到对话系统中的重要性。我还想补充一点:KG 可以提高智能体的答案的可解释性。因此,既然大会主席都提到了基于 KG 的对话系统,那么确实应该在这个领域做一些工作,对吧?是的,这正是我们现在在「Fraunhofer IAIS Dresden」( https://www.iais.fraunhofer.de/en/institute/dresden.html ) 和「Smart Data Analytics」( http://sda.cs.uni-bonn.de/ ) 研究小组所做的工作,致力于推动工业应用以及扩大基于 KG 的会对话平台的研究视野。

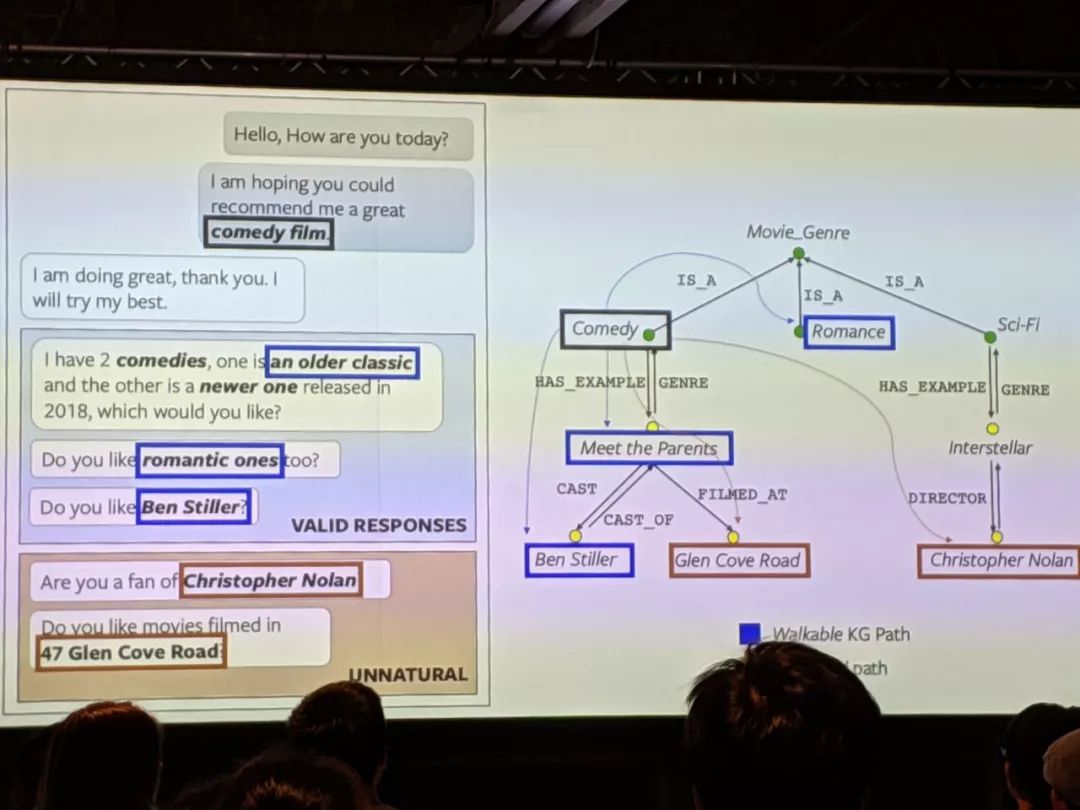
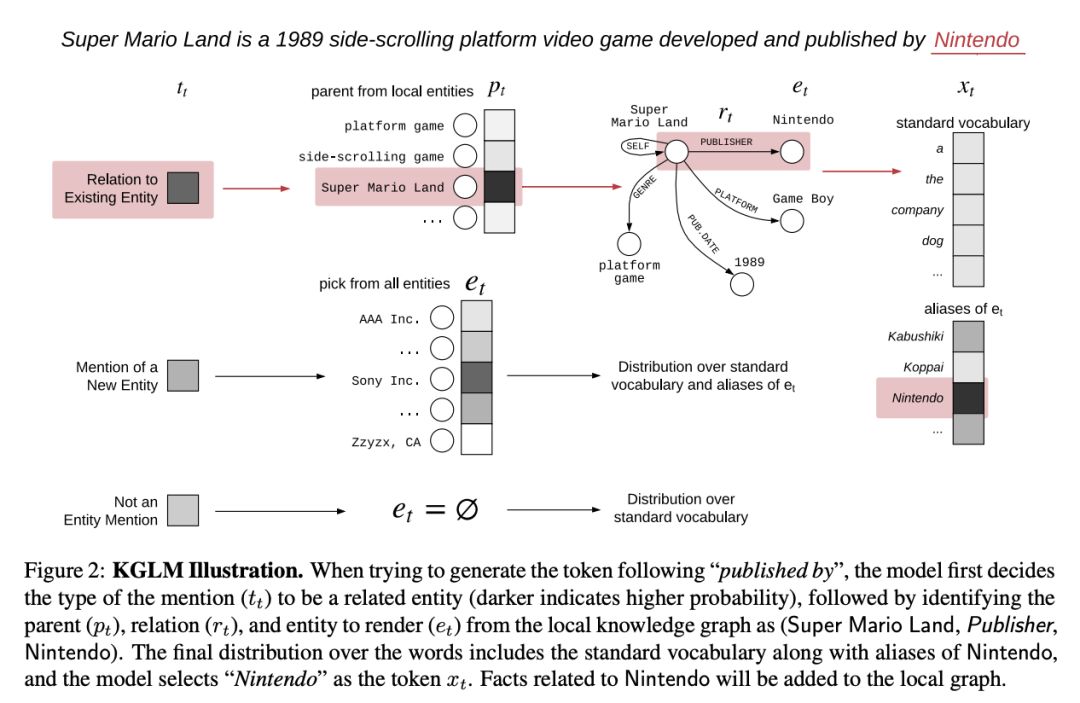
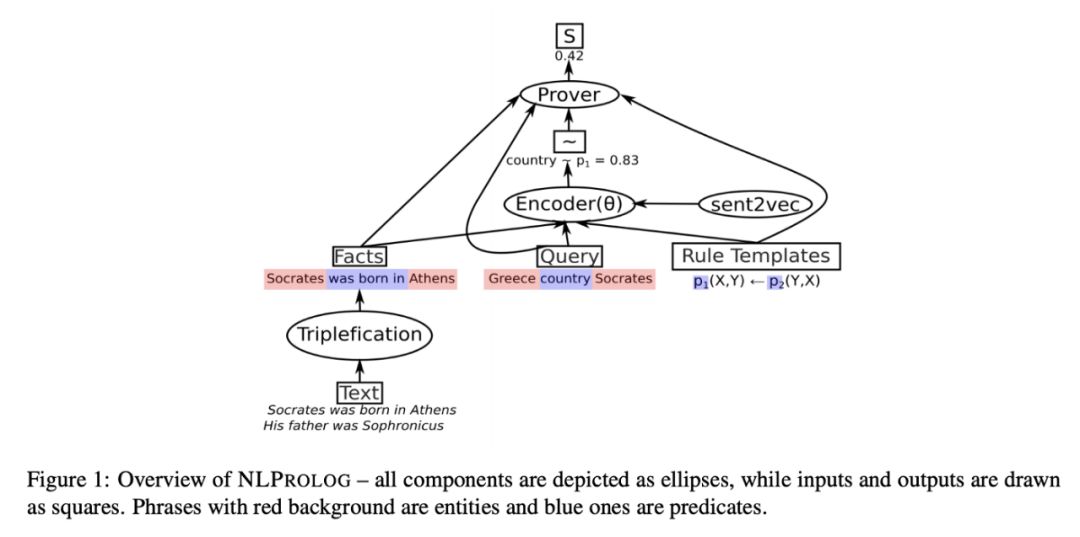
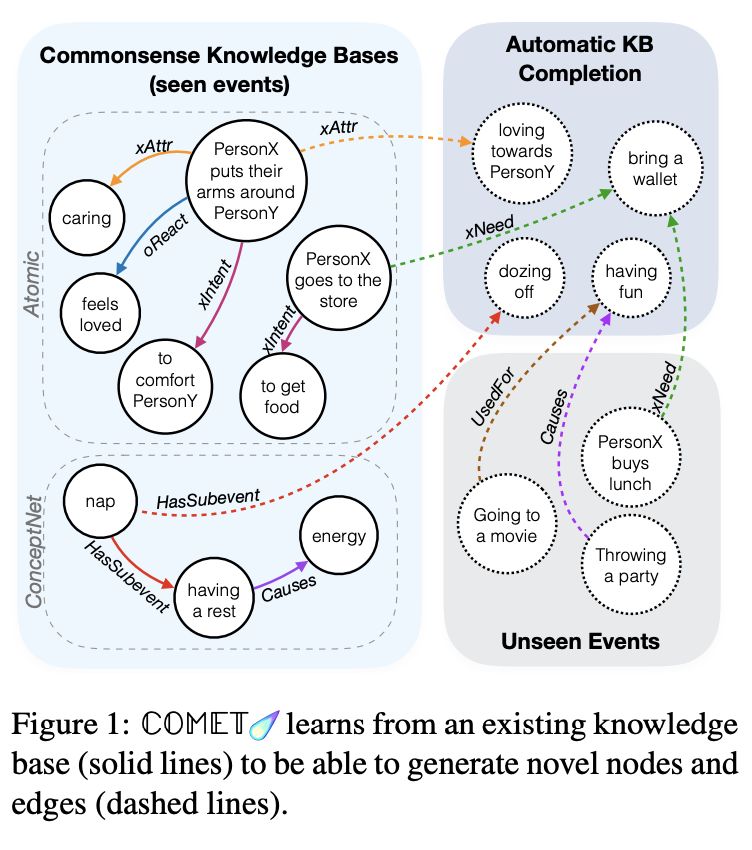
研究者们在「NLP for Conversational AI」研讨会(https://sites.google.com/view/nlp4convai/)上讨论更多的细节,华盛顿大学的 Yejin Choi(https://homes.cs.washington.edu/~yejin/)提出了一种在对话中整合知识种子常识推理的方法(本文的下面也给出了相关技术细节)。

亚马逊的 Ruhi Sarikaya(https://sites.google.com/site/ruhisarikaya01/home)证明了:Alexa 仍然必须在流水线模式下部分执行,从结构化的源头(例如,图结构)中提取知识。
微软研究院的 Jianfeng Gao(https://www.microsoft.com/en-us/research/people/jfgao/)解释 Xiaoice 如何利用结构化信息进行用户参与(Xiaoice 仍然保持聊天机器人最长对话轮次的记录)。


先进制造业+工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进制造业OT(自动化+机器人+工艺+精益)和工业互联网IT(云计算+大数据+物联网+区块链+人工智能)产业智能化技术深度融合,在场景中构建“状态感知-实时分析-自主决策-精准执行-学习提升”的产业智能化平台;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。

版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。




