RAdam优化器又进化:与LookAhead强强结合,性能更优速度更快
鱼羊 编译整理
量子位 报道 | 公众号 QbitAI
上周,来自UIUC的中国博士生Liyuan Liu提出了一种兼具Adam和SGD两者之美的新优化器RAdam,收敛速度快,还很鲁棒,一度登上了GitHub趋势榜。

而今年七月,图灵奖得主Hinton的团队同样在优化器上下了功夫,对SGD进行改进,提出了一种新的优化器LookAhead,在各种深度学习任务上实现了更快的收敛。

那么,把两者结合起来又会发生什么呢?
那位盛赞RAdam为最先进AI优化器的架构师Less Wright不光这么想了,还真的这么干了。
并且他发现,将RAdam和LookAhead结合在一起,RAdam的效果又进一步优化了。
Less Wright将这一协同组合命名为Ranger,已开源并集成到FastAI中。

两强互补
RAdam的先进之处在于,能根据方差分散度,动态地打开或关闭自适应学习率,提供了一种不需要可调参数学习率预热的方法。它兼具Adam和SGD两者的优点,既能保证收敛速度快,也不容易掉入局部最优解,在较大学习率的情况下,精度甚至优于SGD。
量子位详细解读:https://mp.weixin.qq.com/s/scGkuMJ4lZULhmK69vWYpA

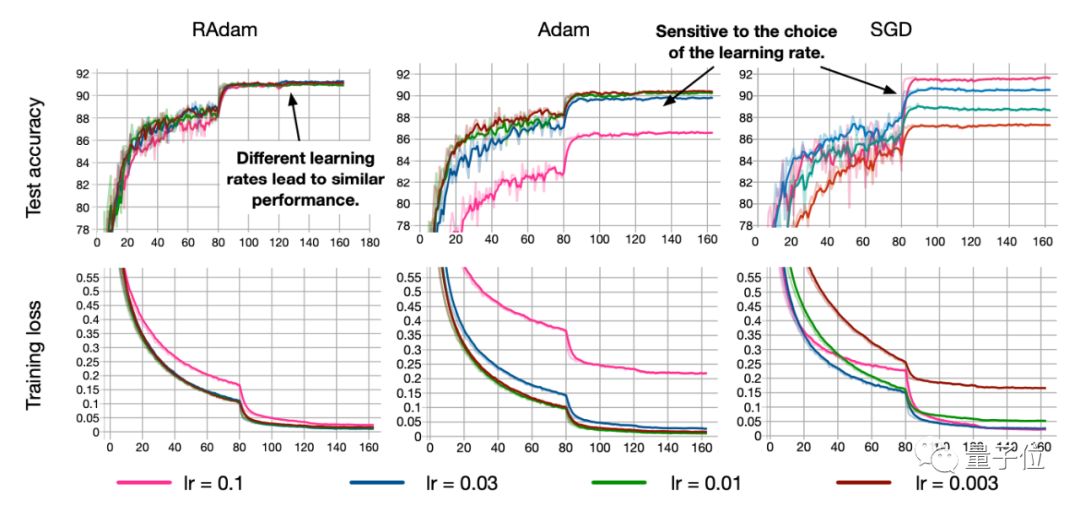
而LookAhead受到深度神经网络损失表面方面进展的启发,能够稳定深度学习训练和收敛速度。LookAhead团队是这样介绍的:
LookAhead减少了需要调整的超参数的数量,能以最小的计算开销实现不同深度学习任务的更快收敛。
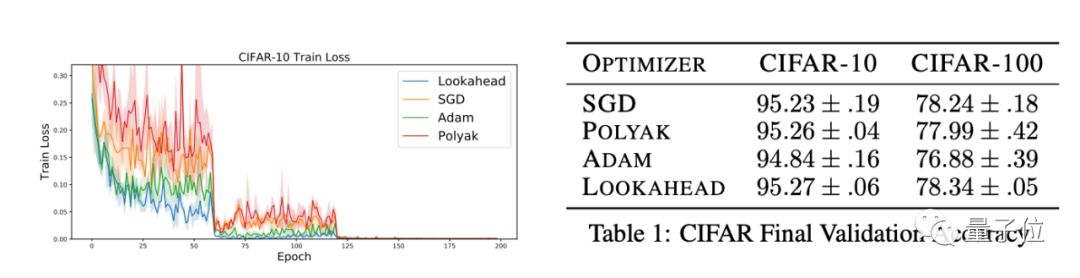
两者从不同的角度着手,各自在深度学习优化上实现了新的突破,而更妙的是,它们的组合具有高度协同性。
根据RAdam的特点,一旦方差稳定下来,在余下的训练阶段当中,RAdam基本等同于Adam和SGD。也就是说,RAdam的改进主要是在训练刚开始的时候。
而LookAhead的原理是,维护两组权重,然后在它们之间进行插值。它允许更快的权重集向前探索,而较慢的权重留在后面以提供更长期的稳定性。
也就是说,LookAhead实际上是保留了一个额外的权重副本,然后让内化的“更快”的优化器进行5或6个batch的训练。批处理的间隔是通过k参数指定的。
所以即使是在1000个epoch之后,LookAhead也依然可以超越SGD。

并且,这个和LookAhead一起运行以获得“快速”权重的优化器,可以是任何优化器。比如RAdam。
Ranger
于是,Less Wright愉快地将RAdam和LookAhead结合在了一起,形成名为Ranger的新优化器。
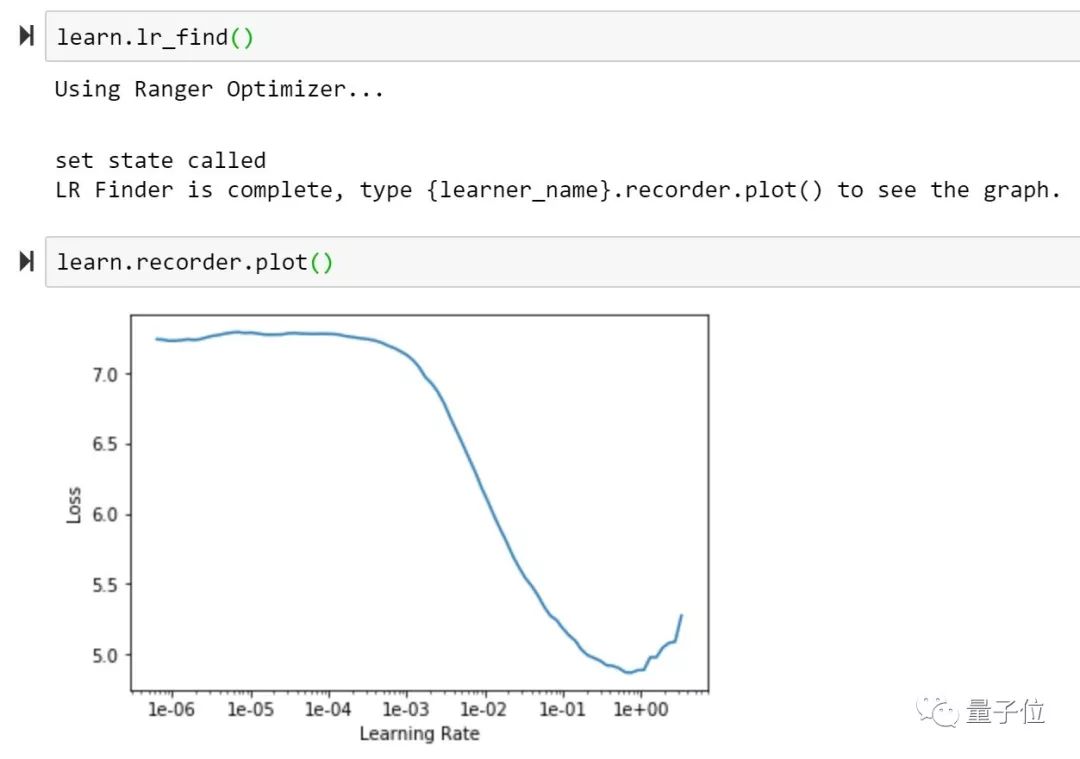
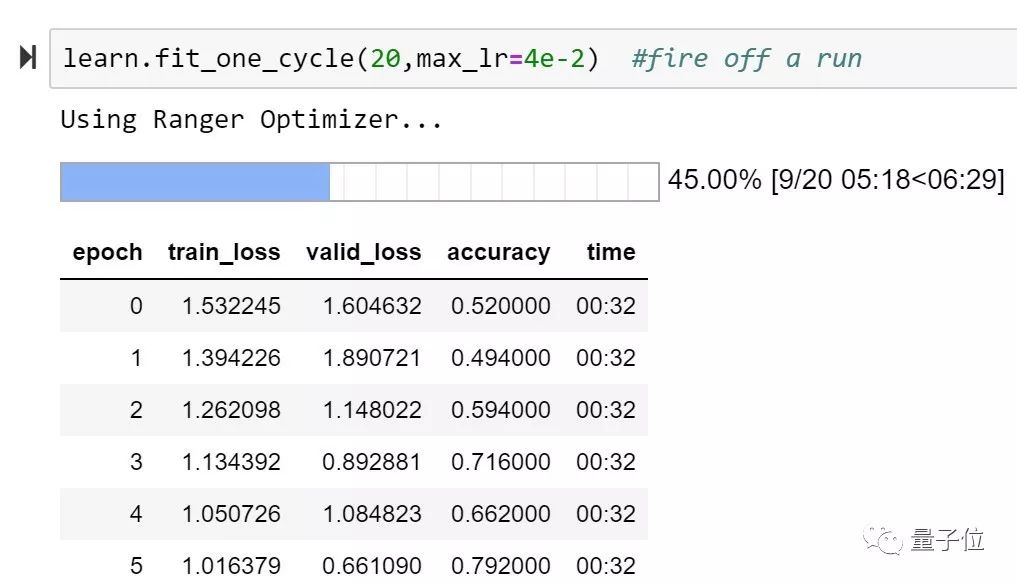
他在ImageNette上进行了测试,在128px,20epoch的测试中,Ranger的训练精度达到了93%,比目前FastAI排行榜榜首提高了1%。
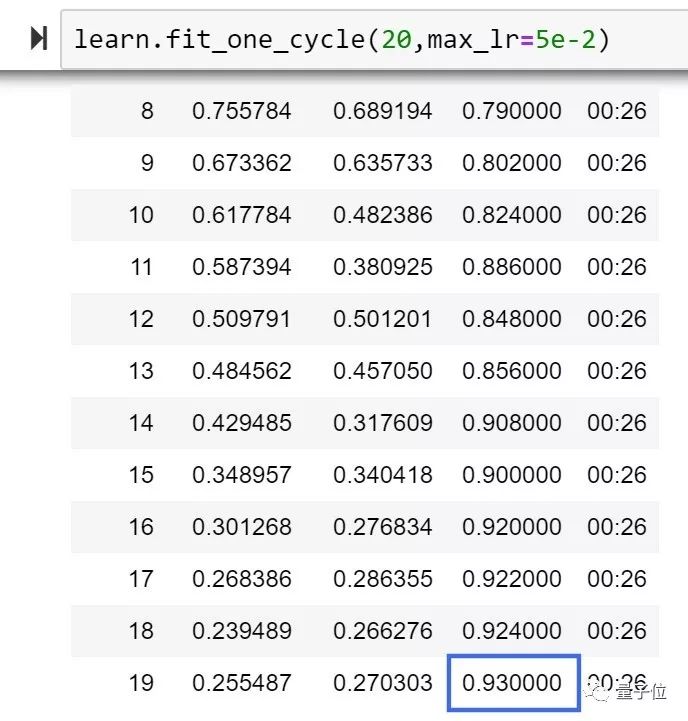

不过,Less Wright表示,在这一尝试当中,使用LookAhead的RAdam的k参数和学习速率还需要进一步测试优化。只是比起此前最先进的方法,RAdam + LookAhead需要手动调整的超参数已经减少了很多。
Ranger的代码实现已经开源,并且集成到了FastAI中,如果你也对这一尝试感兴趣,那么现在就可以自己动手实验一下了:
首先,复制ranger.py到工作目录。
然后import ranger。
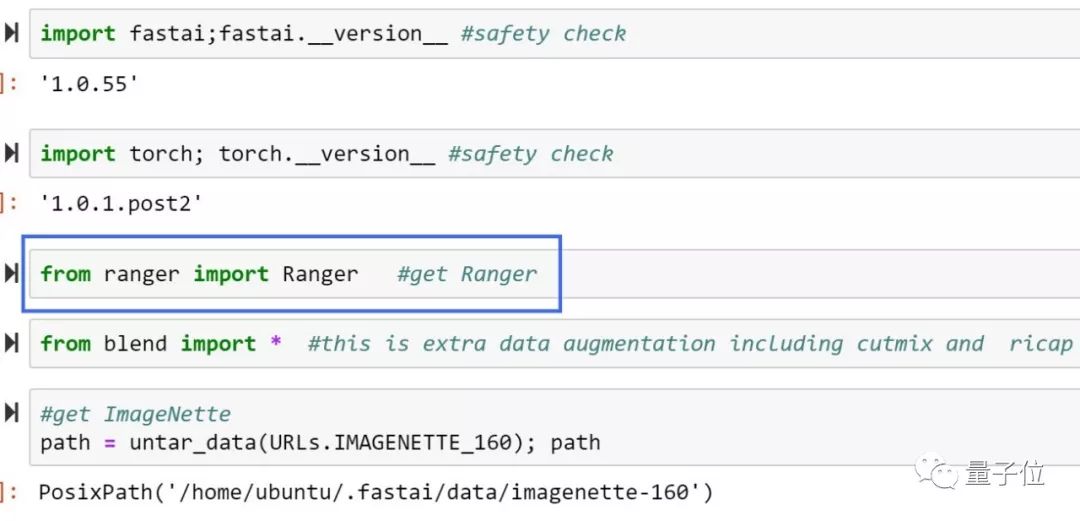
创建一个partial,准备在FastAI里使用Ranger,并将opt_func指向它。

就可以开始测试了。
传送门
GitHub地址:
https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer?source=post_page——-2dc83f79a48d———————————
博客地址:
https://medium.com/@lessw/new-deep-learning-optimizer-ranger-synergistic-combination-of-radam-lookahead-for-the-best-of-2dc83f79a48d
LookAhead论文地址:
https://arxiv.org/abs/1907.08610v1
RAdam论文地址:
https://arxiv.org/abs/1908.03265
— 完 —
加入社群 | 与优秀的人交流

小程序 | 全类别AI学习教程


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !


