强化学习实验里到底需要多少个随机种子的严格证明

AI 研习社按:在机器学习和深度强化学习研究中,可重复性成为了最近最为热门、最常被人诟病的话题之一。复现一篇基于强化学习的文章远比想象的难,具体分析可参照《lessons learned from reproducing a deep RL paper》(http://amid.fish/reproducing-deep-rl)。
事实上,一般情况下,源代码库并不总是被完整发布的,科学性的论文中时常会省略部分实现技巧。近期,Herderson 等人对造成复现困难的各种参数进行了深入的调查。他们使用了当下热门的深度强化学习的算法,如 DDPG、ACKTR、TRPO 和 PPO 等,并结合 OpenAI Gym 中的经典基准测试,如 Half-Cheetah, Hopper 和 Swimmer 等,研究代码库、网络大小、激活函数、奖励缩放或随机种子对性能产生的影响。结果中最令人惊讶的是,同样的算法、用同一组超参数进行训练时,每一次运行后的结果也会大相径庭。
也许最令人惊讶的是:使用相同的超参数和 10 个不同的随机种子运行相同的算法 10 次,其中 5 个种子的表现做平均和另外 5 个种子做平均,得到的两条学习曲线仿佛是来自两个不同的统计分布的。然后,他们展示了这样一个表格:
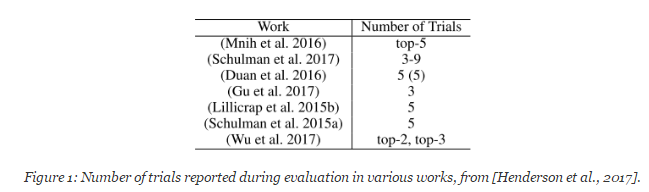
该表显示了 Henderson 等人参考的所有深度 RL 论文使用了少于5粒种子。更糟糕的是,一些论文实际上展现了最佳表现的平均值!正如 Henderson 等人刚才展示的那样,算法表现的不稳定性使得研究者可以通过挑选种子的方式声称某个算法比另一个算法的表现更好,即便事实上并不是这样。这个问题的解决方案是使用更多随机种子,以平均更多不同试验的结果,最终获得更稳健的算法性能度量。那么,到底使用多少才是合适的呢?应该使用 10 个,还是应该像 Mania 等人(https://arxiv.org/pdf/1803.07055.pdf)提出的那样使用 100?答案当然是,看情况。
如果您阅读此博客,我猜您肯定处于以下情况:您希望比较两种算法的性能,以确定哪种算法在给定环境中表现最佳。不幸的是,相同算法的两次运行通常会产生不同的性能数值。这可能是由于各种因素造成的,例如随机发生器产生的种子(随机种子,简称种子)、智能体的初始条件、环境的随机性等。
本文中描述的部分统计过程在 https://github.com/flowersteam/rl-difference-testing 。这篇文章的地址为 https://arxiv.org/abs/1806.08295 。AI 科技评论对全文进行了编译。
统计问题的定义
一段算法的表现可以通过数学建模成一个随机的变量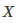
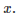
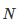
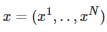
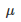
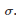
来表示特征。当然了,平均值和偏差都是未知的。但是可以计算的是它们的期望值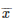
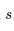
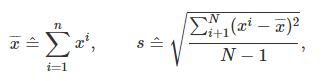
其中,
比较两个表现分别为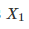
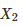
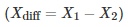
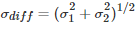
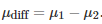
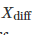
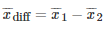
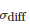
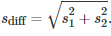
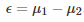
测试两个算法的性能差在数学上等同于测试它们运行结果的差值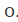
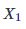
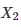
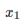
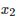
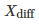
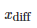
示例一
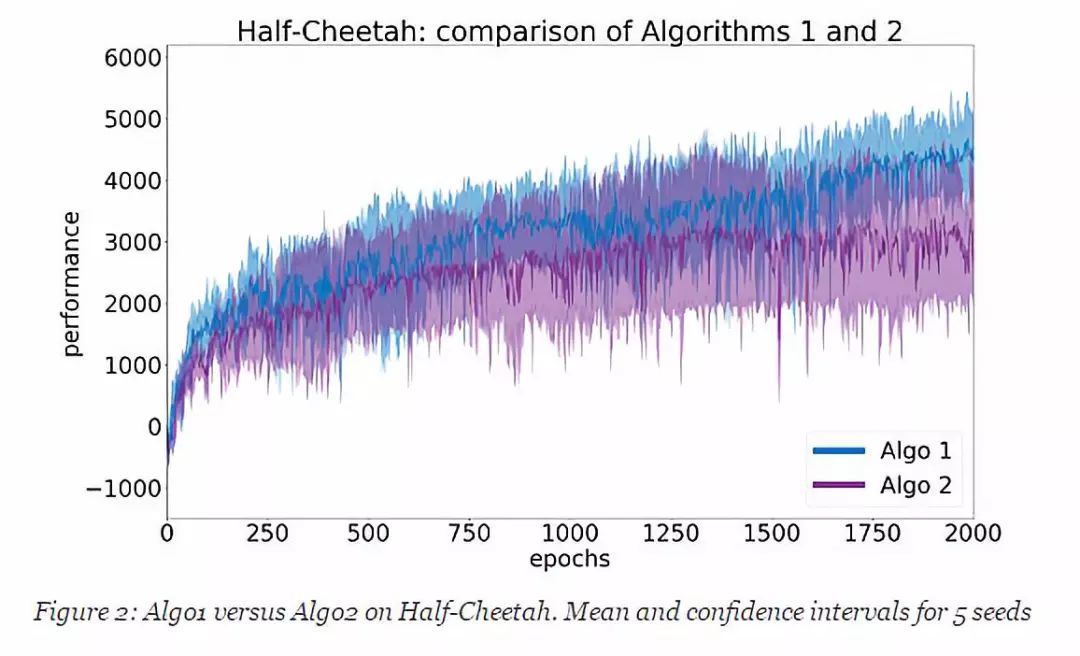
为了说明本文中提出的概念,采用两种算法(Algo1 和 Algo2),并在 OpenAI Gym 框架中的 Half-Cheetah 环境中进行比较。所使用的实际算法在这里并不那么重要,稍后会公布。首先,进行初步研究,对每个算法设定 N = 5 个随机种子,并在图2中绘制结果。该图显示了平均学习曲线与 95% 置信区间。学习曲线的每个点是 10 个评价时段中的奖励的累积值。该算法性能的度量值是过去 10 个点(即最后 100个评价时段)的平均性能。从图中可以看出,Algo1 的表现似乎优于 Algo2;而且,越靠近结尾的位置,置信区间的重叠也并不多。当然,我们需要在得出任何结论之前进行统计学的测试。
将性能与差异测试进行比较
在差异测试中,统计学家首先定义零假设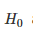
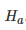
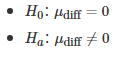
这些假设指的是双尾的情况。如果你有一个先验的算法表现最好,假设为Algo1,也可以使用单尾版本:
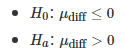
在一开始,统计学家经常会使用零假设。一旦一个样本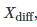
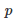
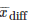
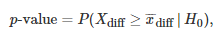
同样的,也可双尾描述:
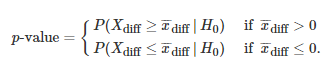
当这个概率变得非常低时,这意味着两个没有性能差异的算法产生收集的样本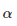
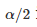
另一种看待这种情况的方法是考虑置信区间。可以计算两种置信区间:

统计中可以出现两种类型的错误:
第一种错误是在没有真正差异时声称算法优于另一算法的优越性。注意,我们称之为显着性水平和类型-I 误差 α 的概率,因为它们都指的是相同的概念。在统计检验的假设下,选择 α 的显着性水平强制执行I型误差 α 的概率。
第二种错误则是在有差异的时候忽略差异的出现,即在实际算法有性能差异的时候错过了发表问斩的机会。
选择适当的统计实验
为了进行性能评估,必须首先确认需要使用的统计实验。在 Herderson 的论文中,two-sample t-test 和自举置信区间试验可用于此目的。Herderson 等人也同时推荐了 Kolmogorov-Smirnov 实验,用于测试两个样本是否来自同一个分布区间。但这种测试不能用于比较 RL 算法,因为它不能证明任何顺序关系。
T-test 和 Welch's test
为了验证两个种群具有相同的均值的假设(零假设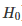
数据测量的规模必须是连续的和有序的,强化学习是满足条件的;
数据是通过从种群中收集代表性样本获得的,在强化学习中,是合理的;
测量是独立分开的,在强化学习中,看起来也是合理的;
数据是正态分布的,或至少呈钟型分布。正态法则是一个涉及无穷大的数学概念,没有任何事物是完全正常分布的。此外,算法性能的测量可能遵循多模态分布。
基于这些假设,可以通过如下公式对统计值 t 和自由度 v 进行描述,这里使用 Welch–Satterthwaite公式:
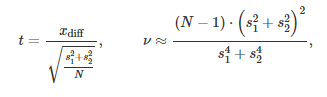
同时,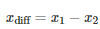
如下图,可以让人更好的理解这个原理。值得注意的是,这边是在单尾情况下,并得到了正差值。
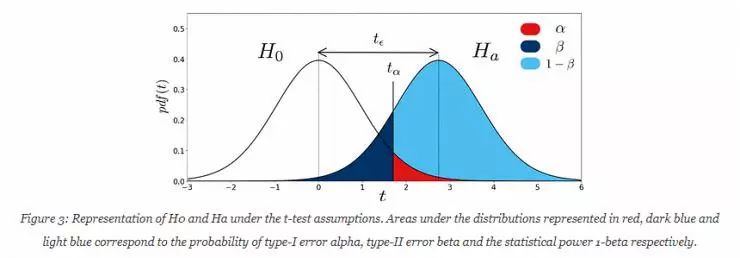
t-distribution 由其概率密度函数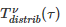

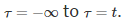
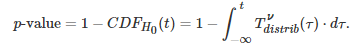
在上图中,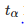
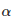
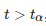
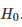
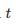
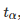
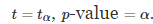
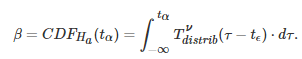
使用积分的转换属性,可以将β重写为:
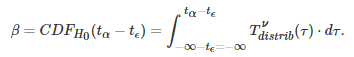
总结一下,给定两个样本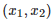
基于
计算自由度 v 和 t-statistics;
通过 t-table 查表获取
的值或使用 CDF 函数评估;
将 t-statistics 和
的数值进行对比。
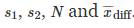
值得注意的是,
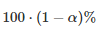
选择 t-test 的显著级别 α 会导致第一种错误的情况。但是,上图显示的是减少这种概率归结为提高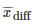
自举置信区间
Bootstrapped 置信区间是一种不对性能差异的分布做出任何假设的方法。它通过在实际收集的样本中重新采样并通过计算每个生成的样本的平均值来估计置信区间。
给定正态分布的真实平均μ和标准偏差σ,一个简单的公式给出95%置信区间。但在这里,考虑一个未知的分布F(给定一个算法的性能分布)。正如我们上面看到的,经验平均值是其真实均值的无偏估计,但是我们如何计算的置信区间?一种解决方案是使用Bootstrapp原理。
假设有一个测试样本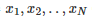
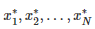
计算过程由如下几步实现:
从原始样本中提取并使用相同的bootstrap的样本数量和样本信息;
计算每个样本的经验平均值,即为
和
;
计算差值
;
使用公式
计算bootstrapped置信区间。范围通常在
和矢量
的概率百分比
之间(如α=0.05,范围则为2.5th和97.5th)。
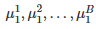
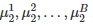
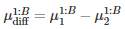
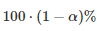
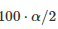
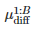
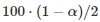
Bootstrap的样本数量B 需要选择相对较大的值(如1000)。如果置信区间的范围不包含0,这就意味着置信为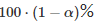
继示例一
这里,设置α=0.05会导致第一种错误的出现。对两个有5个随机种子样本进行Welch's test和bootstrap置信区间测试,p-value 为0.031,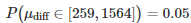
事实上,在实验时,确实碰到了第一种错误。如此确信的原因是:
实验中选取的Algo1和Algo2其实是两个完全相同的算法
它们都是权威的DDPG的实现算法。代码库可以从 https://github.com/openai/baselines 下载。这就意味着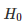
理论分析:样本大小选择所带来的功率
在实验实现环节,强制选择 α 作为显著等级的选择。第二种错误β现在需要进行估算。β是在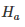
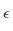
如前文中描述的那样,β 可以使用公式进行分析:
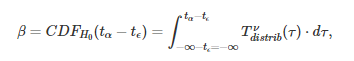
在这里,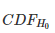
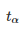
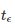
示例二
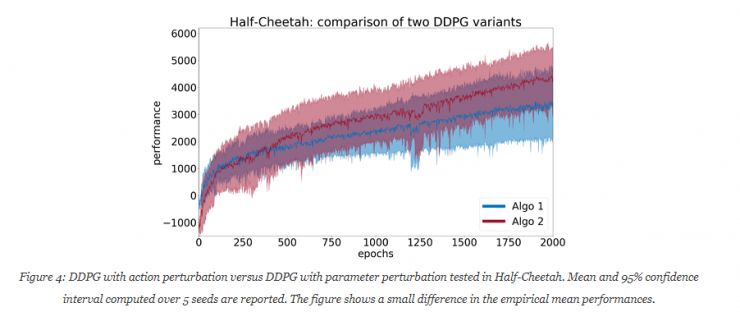
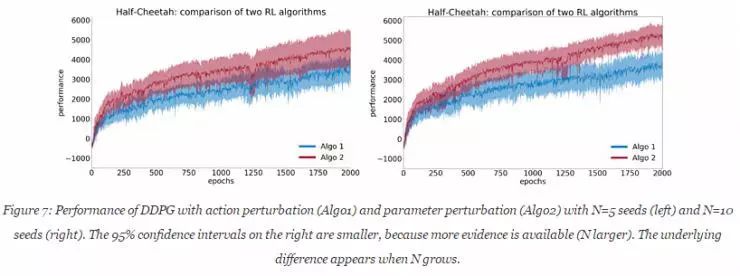
为了更好的理解本文的含义,使用两个DDPG的算法:一个有执行扰动(Algo1),一个有参数扰动(Algo2)。两个算法都在OpenAI Gym框架下的Half-Cheetah环境中执行。
步骤1 - 画图学习
为了实际的获得β,首先需要进行两个算法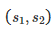
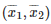
继示例二
这里,设置样本容量为n=5,经验平均值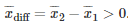
步骤2 - 选择样本大小
给定一个统计测试(如Welch's test),一个显著等级α(如 α =0.05)和Algo1、Algo2的经验估算标准偏差,可以计算得到β,通过基于样本容量 N 和影响因子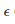
继示例二
若N 在[2, 50]中取,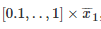
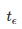
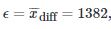
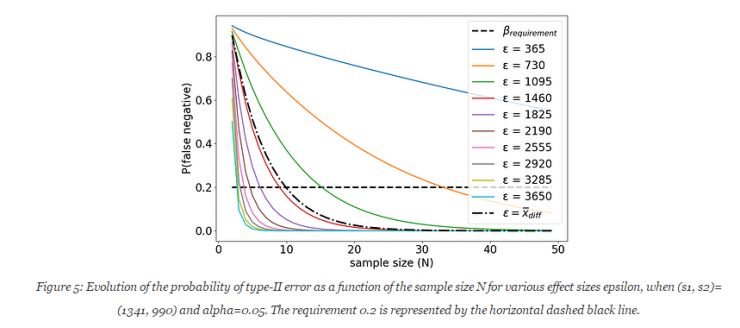
上述实验中,当N=10时,满足影响因子为1382的概率条件,并在welch's test的前提之下,使用的经验估算值为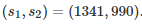
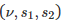
步骤三 - 进行统计测试
两个算法都需要被执行,以获取一个容量为 N 的新的样本
继示例二
这里,设置N=10,并执行Welch's test和bootstrap测试。通过实验,获得Algo1和Algo2的经验平均值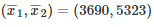
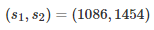

实践:从假设中产生偏差的影响
给定相应的假设,t-test 和 bootstrap 实验在选择显著等级为α 时,都面临第一种错误的问题。为了得到正确的错误概率信息,这些假设都需要被仔细的检查。首先,基于实验数据,需要计算第一种错误概率的经验评估,并展示:1)bootstrap测试对小样本容量极度敏感;2)t-test的结果可能会对非正太分布的数据有偏差。然后,在实验中,也验证了,低样本数导致了s1和s2的估算值的不准确性,并造成β 计算较大的误差,最终造成从实验中反馈的样本数量需求也偏低。
第一种错误的经验估算
给定样本数量N ,第一种错误的概率可以通过如下几个步骤进行估算:
对给定的算法进行双倍数的操作(2 X N)。这可以确保
是正确的,因为所有的测量都来源于同一个数据分布;
将 N 个样本随机的一分为二。并把每个部分当作是从两个不同的算法中分离出来的样本;
测试两种虚拟算法的差异并记录结果;
重复此过程T次(例如T = 1000);
计算H0被拒绝的时间比例。这是 α 的经验评价。
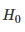
示例三
使用示例二中的Algo1算法。经过42次实验,如上的过程,N 的选择范围为[2,21]。下图展现了实验的结果。在α=0.05的情况下,当N取值过小时,经验估算的false positive的几率比基准值高出很多。
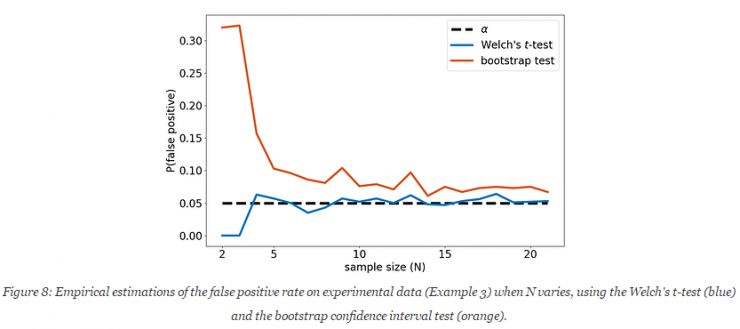
在实验中,bootstrap测试的置信区间不能使用在小样本量的计算中(<10)。即使是在这种情况下,产生第一种错误的概率在实验中被低估了(应为10%,而实验结果为5%)。Welch's test降低了这种影响力,但在样本容量很小的时候,反而更难得到正确的结果了。综上,在实验时,需将α 的值设置为0.05以下,以确保true positive的概率低于0.05。在示例一中,N=5,则遇到了第一种错误。在上图中,这种可能性在bootstrap测试中得到约10%的计算结果,Welch's测试中获得了高于5%的结果。
经验标准偏差的影响
基于样本容量 N 和标准偏差的经验估算值,Welch's test计算了 t 的统计信息和自由度 V 。当 N 的值很低时,S1和S2估算值低于实际的标准偏差值。这导致了更小的 V 和 更低的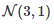
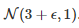
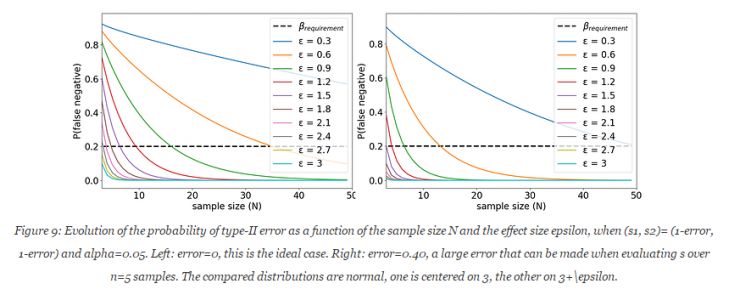
重要的是:
不应该盲目相信统计测试结果。这些测试是基于假设并不总是合理的。
α 必须是经验估计的,因为统计测试可能低估它,因为错误假设的基础分布或因为小样本容量。
第一种错误的Bootstrap测试评价强烈依赖于样本大小。不应使用Bootstrap测试进行低于20数量的样本。
小样本也会造成算法标准偏差估算的不准确,并最终导致对样本容量需求的低估。
结论
在本文中,详细的介绍了在比较两个强化算法的时候遇到的统计问题。并定义了第一种错误和第二种错误,同时还提出了ad-hoc统计测试的方法进行性能对比测试。最后,作者还介绍了在测试中选择正确的样本数量的方法,并通过实际案例进行了分析和描述。
本文最重要的意义并不仅限于方法和应用的介绍,而是基于本文的理论进行的后续的研究。通过挑战Welch's test和bootstrap测试的假设,作者发现了几个问题。首先,作者发现了在实验中,经验推断值和理论实际值的显著差异。为了规避这个问题,作者提出了N=20的最低样本容量要求,指出bootstrap测试必须使用在样本数量N>20的情况下,只有满足这样的要求,才能符合false positive几率的要求(<0.05)。其次,样本容量N的要求在计算中很大的取决于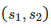
推荐的实验设定
使用 Welch's test 进行 bootstrap 置信区间的计算;
降低 α(<0.05)的值,来确保第一种错误出现的概率低于0.05;
正确的多重比较,以避免随着实验的数量线性增长的 false positive 几率;
使用至少 n=20 的样本进行曲线绘制,以获得基于两个算法的鲁棒的估算;
使用超过功率分析的样本数量。这可以带来更准确的准备偏差估算值并降低第二种错误出现的概率。
最后,作者非常谦虚的留言:需要注意的是,本文的作者并不是一个专业的统计学者,如果在文中发现任何统计学上的问题,请随时与作者联系~
via openlab-flowers.inria.fr,AI 研习社编译
想知道关于强化学习的更多知识?
欢迎点击“阅读原文”
或者移步 AI 研习社社区~





