ICCV 2019 | 旷视研究院11篇接收论文抢先读

两年一度的国际计算机视觉大会 ICCV 2019 ( IEEE International Conference on Computer Vision) 将于 10 月 27 日 - 11 月 2 日在韩国首尔举行。近期,大会官方公布了最终的论文接收决定,旷视研究院共有 11 篇论文被收录,研究领域涵盖通用物体检测及数据集、文字检测与识别、半监督学习、分割算法、视频分析、AI 影像处理、行人及车辆再识别、模型压缩、度量学习、强化学习、元学习等众多领域。本文把 11 篇论文汇在一起,逐篇做了亮点抢先解读。
1. 论文名称:Objects365: A Large-scale, High-quality Dataset for Object Detection
论文链接:暂无
开源链接:https://www.objects365.org/overview.html
关键词:物体检测、数据集
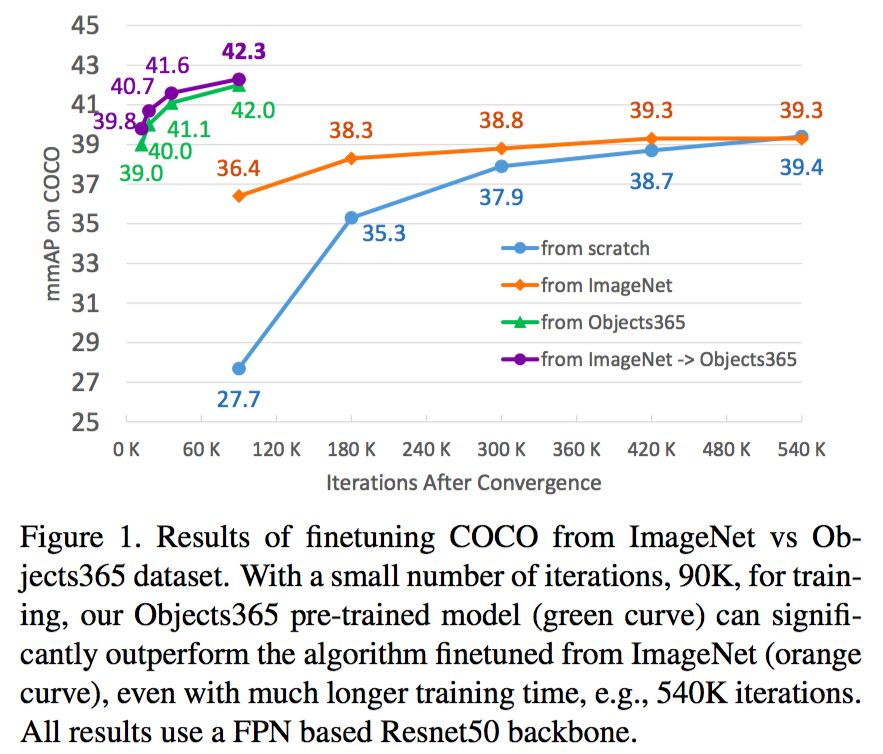
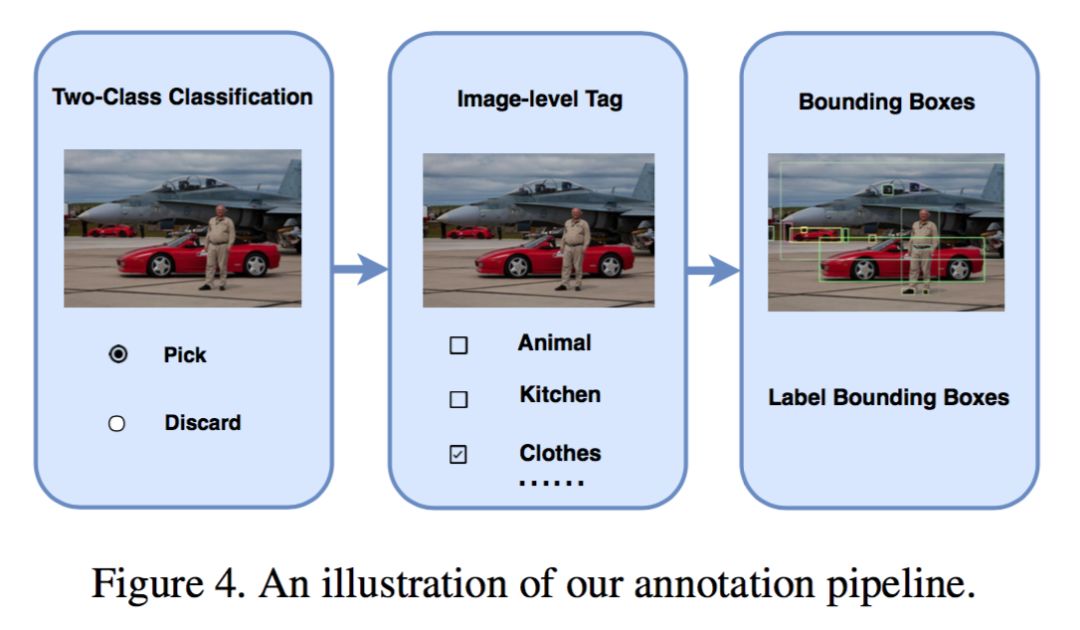
在本文中,我们介绍了一个新的大型物体检测数据集Objects365,它有超过60万张图片,365个类别,超过1000万个高质量的边界框。由精心设计的三步注释管道手动标记,它是迄今为止最大的物体检测数据集(带有完整注释),并为社区建立了更具挑战性的基准。Objects365可以作为更好的特征学习数据集,用于目标检测和分割等定位敏感任务。Objects365预训练模型明显优于ImageNet预训练模型:在COCO上训练90K / 540K次迭代时AP提高了5.6(42 vs 36.4)/ 2.7(42 vs 39.3)。同时,当达到相同的精度时,fine-tune时间可以大大减少(最多10倍差距)。在CityPersons,VOC Segmentation和ADE中也验证了Object365更好的泛化能力。我们将发布数据集以及所有预训练的模型。
2. 论文名称:ThunderNet: Towards Real-time Generic Object Detection
论文链接:https://arxiv.org/abs/1903.11752
关键词:通用物体检测
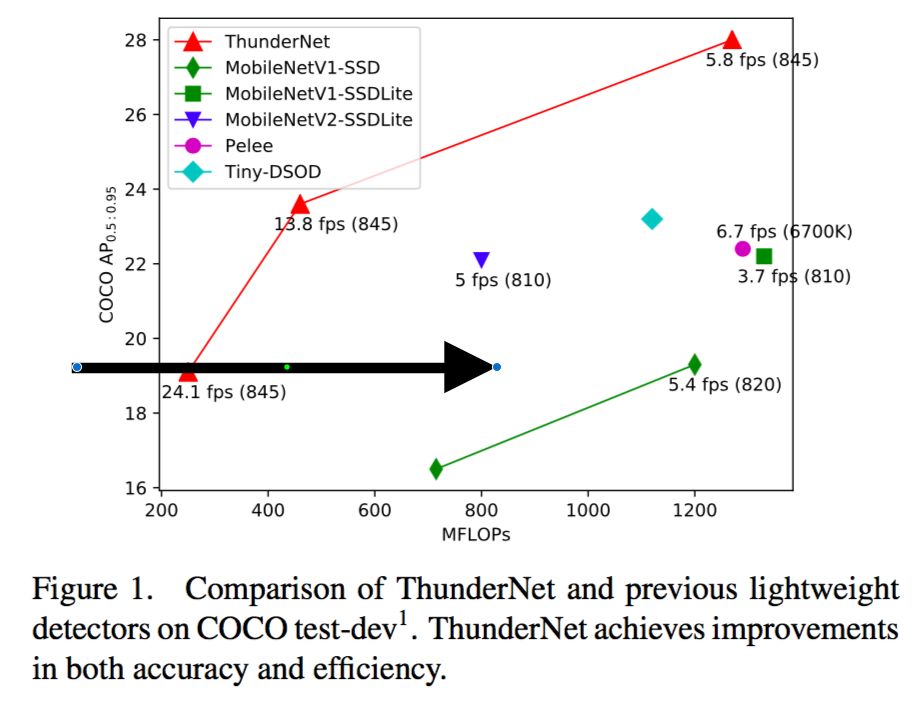
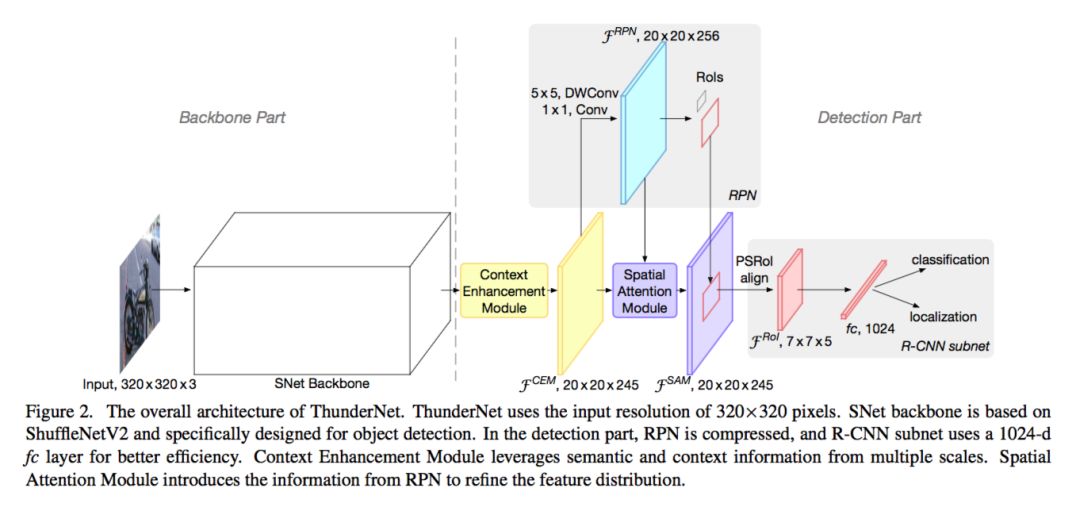
在计算机视觉领域中,如何在移动设备上实现实时目标检测是一个非常重要而又十分有挑战性的任务。然而,目前基于CNN的目标检测网络往往都需要巨大的计算开销,导致这些网络模型无法在移动设备上进行部署应用。在这篇文章中,我们探索了两阶段目标检测模型在移动端实时目标检测任务上的有效性,并提出了一种轻量级的两阶段目标检测模型ThunderNet。在骨干网部分,我们分析了之前的轻量级骨干网络的缺点,并提出了一种针对目标检测任务设计的轻量级骨干网络。在检测网部分,我们采用了极为简洁的RPN和检测头的设计。为了产生更有判别性的特征表示,我们设计了两个网络模块:上下文增强模块(CEM)和空间注意力模块(SAM)。最后,我们探讨了轻量级目标检测模型的输入分辨率、骨干网和检测头之间计算开销的平衡关系。与之前的轻量级一阶段目标检测模型相比,ThunderNet仅仅需要40%的计算开销就可以在Pascal VOC和COCO数据集上实现更好的检测精度。ThunderNet还在移动设备上实现了24.1fps的实时检测。据知,这是在ARM平台上报告的第一个实时检测模型。
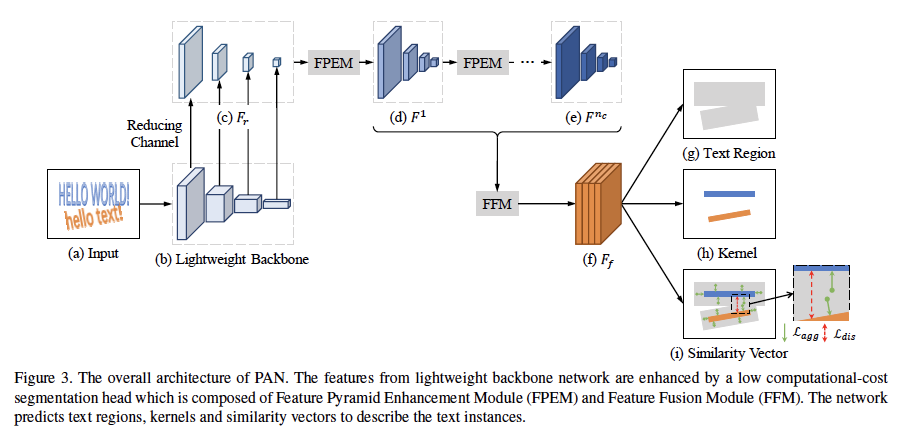
3. 论文名称:Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network
论文链接:暂无
关键词:文本检测
场景文本检测是场景文本阅读系统的重要一步,随着卷积神经网络的快速发展,场景文字检测也取得了巨大的进步。尽管如此,仍存在两个主要挑战,它们阻碍文字检测部署到现实世界的应用中。第一个问题是速度和准确性之间的平衡。第二个是对任意形状的文本实例进行建模。最近,已经提出了一些方法来处理任意形状的文本检测,但是它们很少去考虑算法的运行时间和效率,这可能在实际应用环境中受到限制。在本文中,我们提出了一种高效且准确的任意形状文本检测器,称为PSENet V2,它配备了低计算成本的分割模块和可学习的后处理方法。更具体地,分割模块由特征金字塔增强模块(FPEM)和特征融合模块(FFM)组成。FPEM是一个可级联的U形模块,可以引入多级、信息来指导更好的分割。FFM可以将不同深度的FPEM给出的特征汇合到最终的分割特征中。可学习的后处理由像素聚合模块(PA)实现,其可以通过预测的相似性向量精确地聚合文本像素。几个标准基准测试的实验验证了所提出的PSENet V2的优越性。值得注意的是,我们的方法可以在CTW1500上以84.2 FPS实现79.9%的F-measure。据我们所知,PSENet V2是第一种能够实时检测任意形状文本实例的方法。

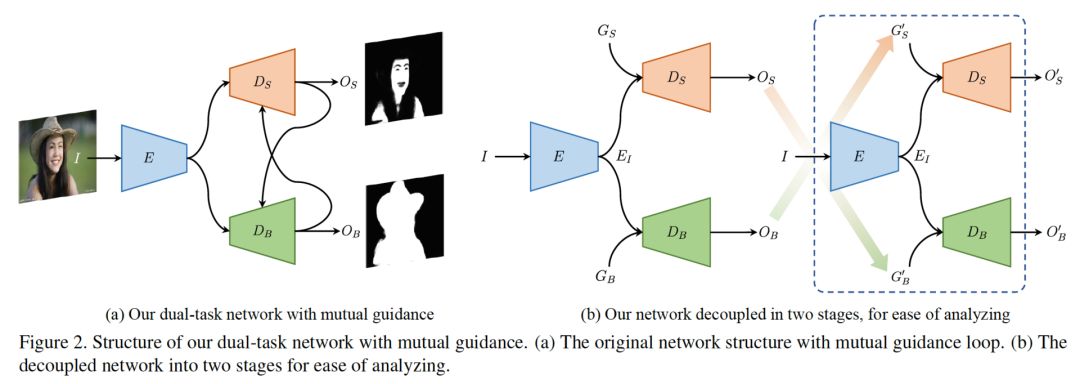
4. 论文名称:Semi-supervised Skin Detection by Network with Mutual Guidance
论文链接:暂无
关键词:半监督学习、皮肤分割
我们提出一种新的数据驱动的皮肤分割方法,可以从单张人像图中鲁棒地算出皮肤区域。不像先前的方法,我们利用人体区域作为弱语义引导,考虑到大量人工标注的皮肤数据非常难以获得。具体说来,我们提出了一种双任务的网络通过半监督的学习策略来联合地检测皮肤和身体。该网络包含了一个共享的编码器、两个独立的解码器分别检测皮肤和身体。对于任意一个解码器,其输出也扮演着另外一个解码器引导的角色。这样以来,两个解码器实际上是相互引导。大量实验证明了相互引导策略的有效性,并且结果也显示该方法在皮肤分割的任务上比现有方法更好。

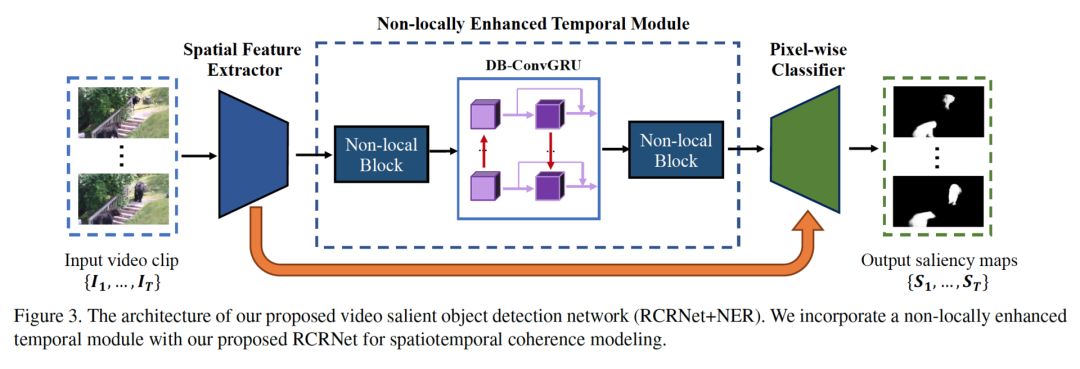
5. 论文名称:Semi-Supervised Video Salient Object Detection Using Pseudo-Labels
论文链接:暂无
关键词:半监督学习、视频检测
基于深度学习的视频重点区域检测已经超过了大量无监督的方法。但该方法依赖大量人工标注的数据。在本文中,我们利用伪标签来解决半监督的视频重点区域检测问题。具体说来,我们提出了一个视频重点区域检测器,其包含了一个空间信息改良网络和一个时空模块。基于这样的结构以及光流,我们提出了一个从稀疏标注的帧中生成像素级伪标签的方法。利用生成的伪标签以及部分人工标注,我们的检测器学习到了时空中对比度和帧间一致性的线索,从而得到了准确的重点区域。实验证明了本方法在多个数据集上大幅度超过了现有的全监督的方法。

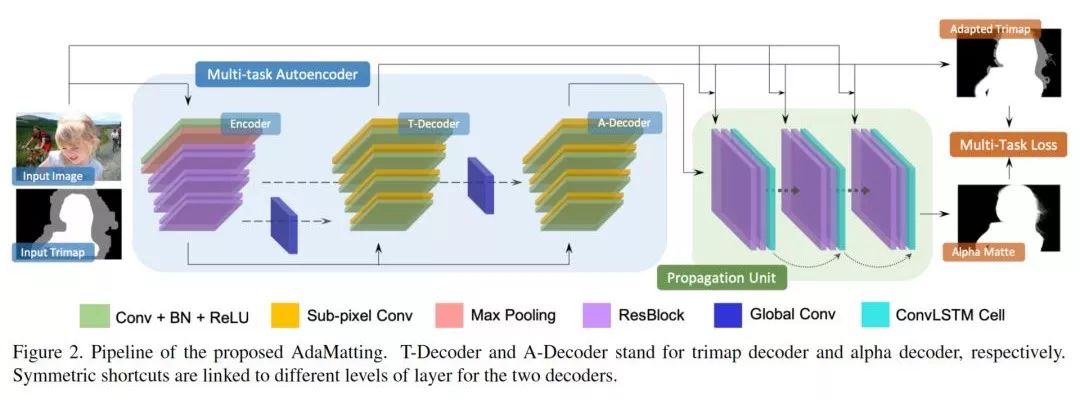
6. 论文名称:Disentangled Image Matting
论文链接:暂无
关键词:图像去背
我们提出了图像去背 (Image Matting) 问题的一种全新框架。多数之前的图像去背算法根据输入三分图 (trimap) 在图像的指定区域中计算阿法值 (alpha)。对于被划入三分图待确认 (unknown) 区域中的完全背景和前景像素,这些方法期望精确地产生 0 和 1 的阿法值。本文指出,之前解法实际上将两个不同的问题混在了一起:1. 区分待确认区域中的前景、背景和混合像素; 2. 为混合像素精确地计算阿法值。其中我们称第一个任务被称为三分图调整 (Trimap Adaptation),第二个任务为阿法值估计 (Alpha Estimation)。其中三分图调整是典型的分类问题,阿法值估计是典型的回归问题,本文提出的端到端的 AdaMatting 框架,通过使用多任务学习 (Multi-task Learning) 的方式分开解决这两个问题,在多个图像数据集上的所有常用指标中取得了目前最佳的结果。
7. 论文名称:Re-ID Driven Localization Refinement for Person Search
论文链接:暂无
关键词:行人搜索
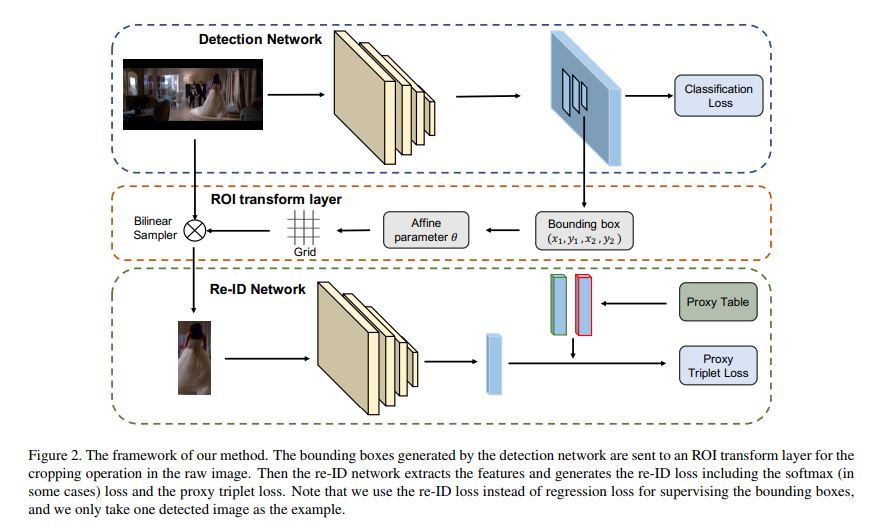
在很多应用中,检测器作为上游任务,其结果直接影响下游任务,尤其检测框的定位精度。目前的主流做法是将检测器单独进行训练,而没有考虑下游任务,因此得到的检测框对下游任务未必最优。在本文中,我们以行人搜索任务为例,提出了一种新的优化检测框定位精度的方法,使其更加适合给定任务。行人搜索旨在从完整的图片中检测并识别行人,分为检测和行人重识别(Re-ID)两个任务。文章提出一种re-ID驱动的定位调整框架,用re-ID loss对检测网络产生的检测框进行微调。文章设计了一个可导的ROI转换模块,能够根据检测框的坐标从原图中crop出对应位置图片,再送入re-ID网络。由于整个过程可导,re-ID loss能够对检测框的坐标进行监督,从而使检测网络能够生成更适合行人搜索这个任务的检测框。通过大量的实验结果证明,论文的方法多个数据集上取得了当前最先进的性能。

8. 论文名称:Vehicle Re-identification with Viewpoint-aware Metric Learning
论文链接:暂无
关键词:车辆再识别、度量学习
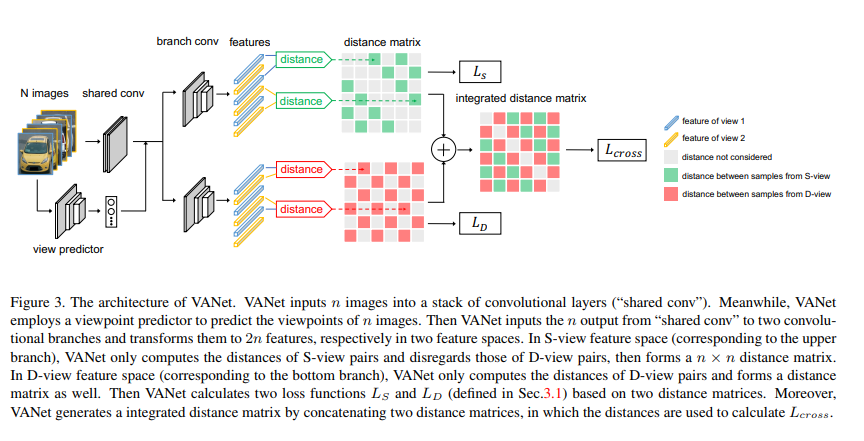
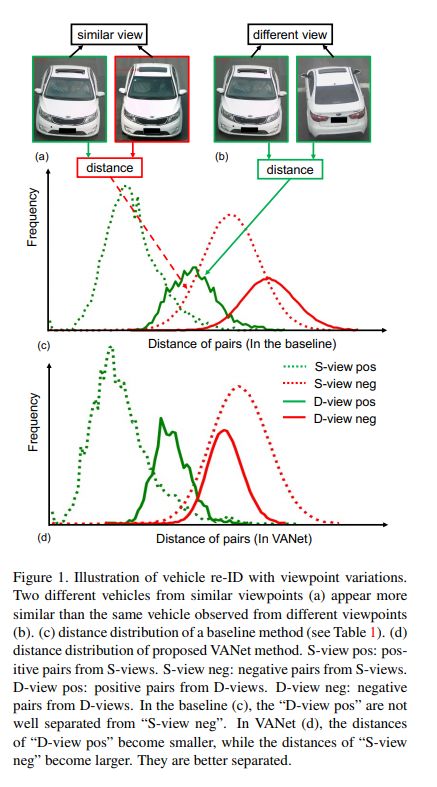
在车辆重识别任务中,极端的视角变化(变化视角可达180度)给现有的方法带来了巨大挑战。受到人类识别车辆时认知方式的启发,我们提出了一种基于视角感知的度量学习方法。该方法针对相似视角和不同视角,分别在两个特征空间学习两种度量标准,由此产生了视角感知网络(VANet)。在训练过程,我们施加了两种约束进行联合训练。在测试过程,我们首先估计车辆的视角,并基于估计结果采用对应的度量方式进行度量。实验结果证实了VANet能够显著地提高车辆重识别的准确度,在识别拍摄视角不同的车辆对时效果更为明显。我们的方法在两个基准数据集上都实现了目前最好的结果。
9. 论文名称:MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning
论文链接:https://arxiv.org/abs/1903.10258
关键词:模型压缩、元学习
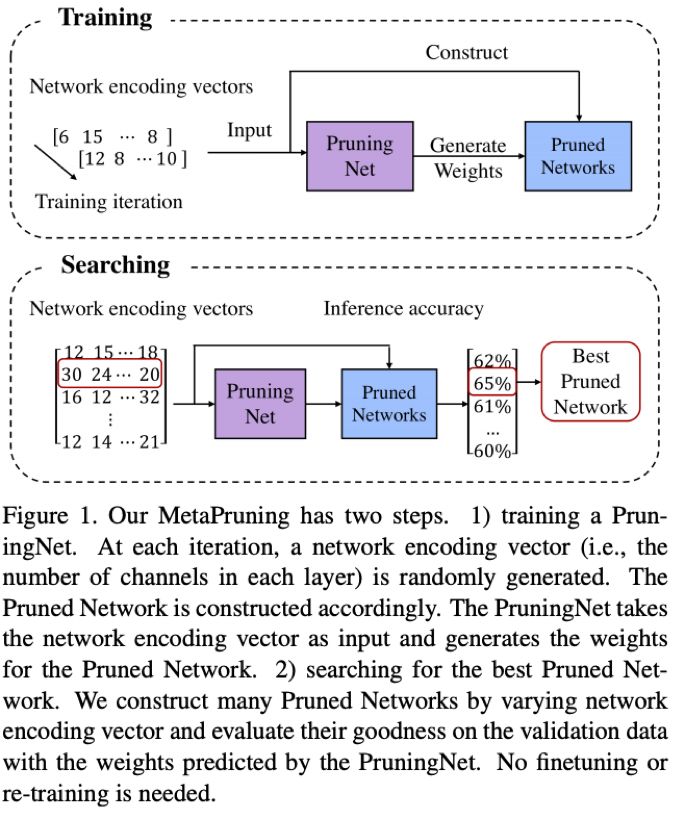
Channel Pruning 是一种有效的模型压缩方法,我们的方法 MetaPruning 提出了一种新的Pruning思路。传统Pruning往往需要人工或基于一些经验准则设定各层的压缩比例,然后迭代选择去除哪些channel,这个过程较耗时耗力。MetaPruning,跳过选择哪个channel,直接搜索每层保留多少channel。为了既高效又准确地找到最优的每层channel组合,MetaPruning 首先训练一个PruningNet,用meta-learning预测各个可能的裁剪后网络(PrunedNet)的精度。借用Network Architecture Search的思想,用进化算法搜索最优的PrunedNet。PruningNet 直接为PrunedNet预测了可靠的精度,使得进化搜索非常高效。最后MetaPruning 比MobileNet V1/V2 baseline精度提升高达9.0%/9.9%。相比于当前最优的AutoML-based Pruning 方法,MetaPruning也取得了更高的精度。并且MetaPruning非常灵活,可以适用于FLOPs限制下的pruning或者针对特定硬件速度限制的pruning。
10. 论文名称:Symmetry-constrained Rectification Network for Scene Text Recognition
论文链接:暂无
#关键词:文字识别
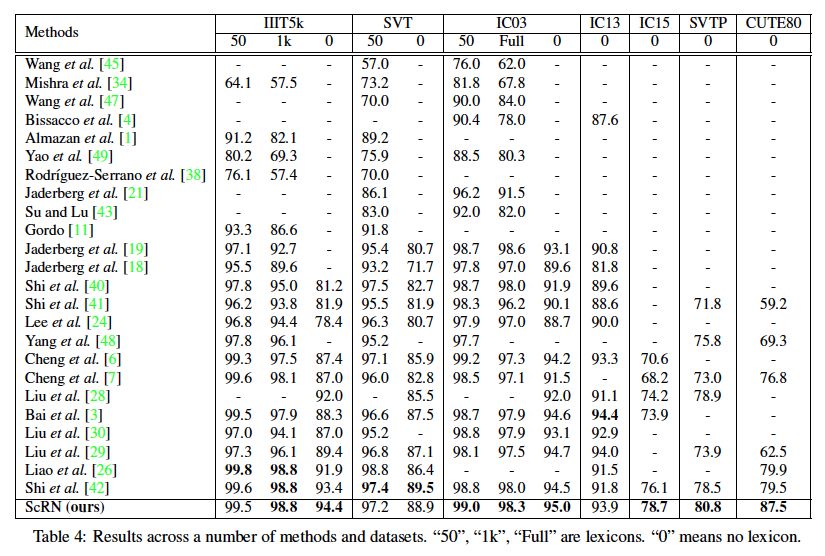
由于文字字体、形状的多样性以及自然场景的复杂性,自然场景的文字识别一直是一项十分具有挑战性的任务。近些年来,不规则形状场景文字的识别问题吸引了越来越多研究者的目光,其中一个有效且直观的研究方向,就是对文字区域进行识别前的矫正,即在识别之前把不规则的文字进行矫正成正常形状。然而,简单的文字矫正可能会对极度变形或者弯曲的文字失去作用。为了解决这一问题,我们提出了ScRN(Symmetry-constrained Rectification Network),一个利用文字对称性约束的文字矫正网络。ScRN利用了文字区域的很多数学属性,包括文字的中心线、字符大小以及字符方向信息。这些信息可以帮助ScRN生成精确的文字区域描述,使得ScRN获得比已有方法更优的矫正效果,从而带来更高的识别精度。我们在多个不规则数据集上(ICDAR 2015, SVT-Perspective, CUTE80)都取得了较高的识别精度提升。
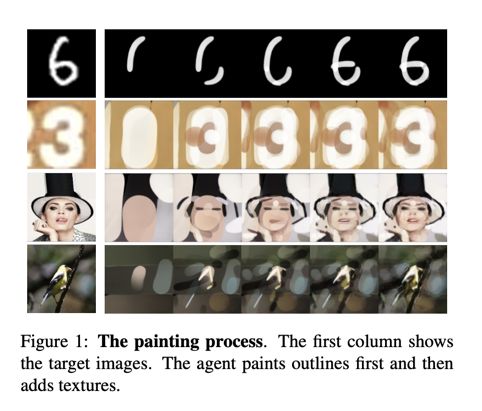
11. 论文名称:Learning to Paint with Model-based Deep Reinforcement Learning
论文链接:https://arxiv.org/abs/1903.04411
开源代码:https://github.com/hzwer/ICCV2019-LearningToPaint
关键词:强化学习、绘画
如何让机器像画家一样,用寥寥数笔创造出迷人的画作?结合深度强化学习方法和神经网络渲染器,我们让智能体在自我探索中学会用数百个笔画绘制出纹理丰富的自然图像,每一个笔画的形状、位置和颜色都是由它自主决定的。智能体的训练过程不需要人类绘画的经验或笔画轨迹数据。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。




