使用 JAX 构建强化学习 agent,并借助 TensorFlow Lite 将其部署到 Android 应用中


发布人:技术推广工程师 魏巍
在我们之前发布的文章《一个新的 TensorFlow Lite 示例应用:棋盘游戏》中,展示了如何使用 TensorFlow 和 TensorFlow Agents 来训练强化学习 (RL) agent,使其玩一个简单的棋盘游戏“Plane Strike”。我们还将训练后的模型转换为 TensorFlow Lite,然后将其部署到功能完备的 Android 应用中。本文,我们将演示一种全新路径:使用 Flax/JAX 训练相同的强化学习 agent,然后将其部署到我们之前构建的同一款 Android 应用中。我们已经在 tensorflow/examples 代码库中开放了完整的源代码以供您参考。
Flax
https://flax.readthedocs.io/
JAX
https://jax.readthedocs.io/
tensorflow/examples
https://github.com/tensorflow/examples/blob/master/lite/examples/reinforcement_learning/ml/tf_and_jax/training_jax.py
简单回顾一下游戏规则:我们基于强化学习的 agent 需要根据真人玩家的棋盘位置预测击打位置,以便能早于真人玩家完成游戏。如需进一步了解游戏规则,请参阅我们之前发布的文章。
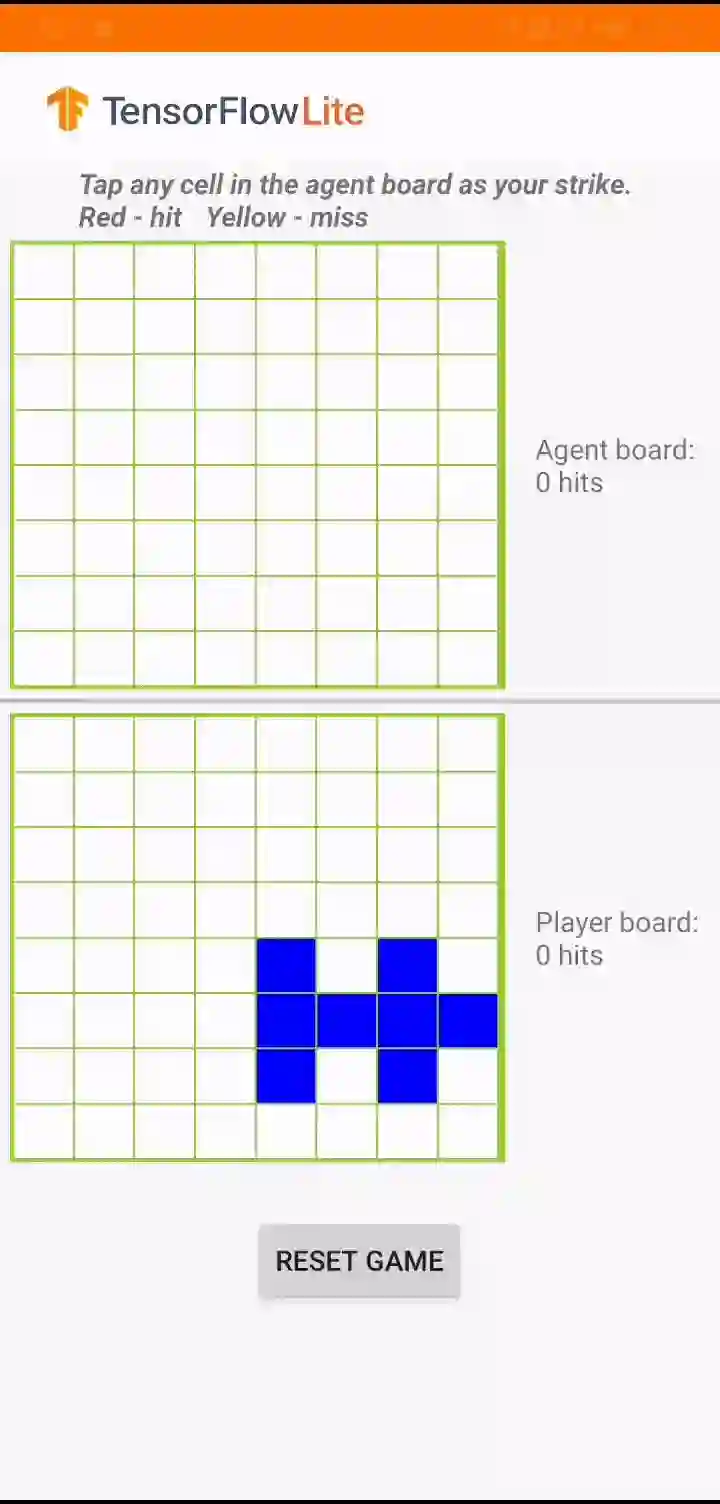
“Plane Strike”游戏演示

JAX 是一个与 NumPy 类似的内容库,由 Google Research 部门专为实现高性能计算而开发。JAX 使用 XLA 针对 GPU 和 TPU 优化的程序进行编译。
JAX
https://github.com/google/jax
XLA
https://tensorflow.google.cn/xla
TPU
https://cloud.google.com/tpu
而 Flax 则是在 JAX 基础上构建的一款热门神经网络库。研究人员一直在使用 JAX/Flax 来训练包含数亿万个参数的超大模型(如用于语言理解和生成的 PaLM,或者用于图像生成的 Imagen),以便充分利用现代硬件。
Flax
https://github.com/google/flax
PaLM
https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html
Imagen
https://imagen.research.google/
如果您不熟悉 JAX 和 Flax,可以先从 JAX 101 教程和 Flax 入门示例开始。
JAX 101 教程
https://jax.readthedocs.io/en/latest/jax-101/index.html
Flax 入门示例
https://flax.readthedocs.io/en/latest/getting_started.html
2015 年底,TensorFlow 作为 Machine Learning (ML) 内容库问世,现已发展为一个丰富的生态系统,其中包含用于实现 ML 流水线生产化 (TFX)、数据可视化 (TensorBoard),和将 ML 模型部署到边缘设备 (TensorFlow Lite) 的工具,以及在网络浏览器上运行的装置,或能够执行 JavaScript (TensorFlow.js) 的任何装置。
TFX
https://tensorflow.google.cn/tfx
TensorBoard
https://tensorboard.dev/
TensorFlow Lite
https://tensorflow.google.cn/lite
TensorFlow.js
https://tensorflow.google.cn/js
在 JAX 或 Flax 中开发的模型也可以利用这一丰富的生态系统。方法是首先将此类模型转换为 TensorFlow SavedModel 格式,然后使用与它们在 TensorFlow 中原生开发相同的工具。
SavedModel
https://tensorflow.google.cn/guide/saved_model
如果您已经拥有经 JAX 训练的模型并希望立即进行部署,我们整合了一份资源列表供您参考:
视频 “使用 TensorFlow Serving 为 JAX 模型提供服务”,展示了如何使用 TensorFlow Serving 部署 JAX 模型。
https://youtu.be/I4dx7OI9FJQ?t=36
文章《借助 TensorFlow.js 在网络上使用 JAX》,对如何将 JAX 模型转换为 TFJS,并在网络应用中运行进行了详细讲解。
https://blog.tensorflow.org/2022/08/jax-on-web-with-tensorflowjs.html
本篇文章演示了如何将 Flax/JAX 模型转换为 TFLite,并在原生 Android 应用中运行该模型。
总而言之,无论您的部署目标是服务器、网络还是移动设备,我们都会为您提供相应的帮助。
将目光转回到棋盘游戏。为了实现强化学习 agent,我们将会利用与之前相同的 OpenAI gym 环境。这次,我们将使用 Flax/JAX 训练相同的策略梯度模型。回想一下,在数学层面上策略梯度的定义是:
OpenAI gym
https://github.com/tensorflow/examples/tree/master/lite/examples/reinforcement_learning/ml/tf_and_jax/gym_planestrike/gym_planestrike/envs
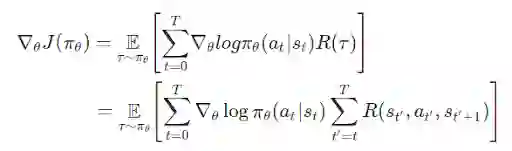
其中:
T:每段的时步数,各段的时步数可能有所不同
st:时步上的状态 t
at:时步上的所选操作 t 指定状态 s
πθ:参数为 θ 的策略
R(*):在指定策略下,收集到的奖励
我们定义了一个 3 层 MLP 作为策略网络,该网络可以预测 agent 的下一个击打位置。
class PolicyGradient(nn.Module):
"""Neural network to predict the next strike position."""
@nn.compact
def __call__(self, x):
dtype = jnp.float32
x = x.reshape((x.shape[0], -1))
x = nn.Dense(
features=2 * common.BOARD_SIZE**2, name='hidden1', dtype=dtype)(
x)
x = nn.relu(x)
x = nn.Dense(features=common.BOARD_SIZE**2, name='hidden2', dtype=dtype)(x)
x = nn.relu(x)
x = nn.Dense(features=common.BOARD_SIZE**2, name='logits', dtype=dtype)(x)
policy_probabilities = nn.softmax(x)
return policy_probabilities在我们训练循环的每次迭代中,我们都会使用神经网络玩一局游戏、收集轨迹信息(游戏棋盘位置、采取的操作和奖励)、对奖励进行折扣,然后使用相应轨迹训练模型。
for i in tqdm(range(iterations)):
predict_fn = functools.partial(run_inference, params)
board_log, action_log, result_log = common.play_game(predict_fn)
rewards = common.compute_rewards(result_log)
optimizer, params, opt_state = train_step(optimizer, params, opt_state,
board_log, action_log, rewards)在 train_step() 方法中,我们首先会使用轨迹计算损失,然后使用 jax.grad() 计算梯度,最后,使用 Optax(用于 JAX 的梯度处理和优化库)来更新模型参数。
Optax
https://github.com/deepmind/optax
def compute_loss(logits, labels, rewards):
one_hot_labels = jax.nn.one_hot(labels, num_classes=common.BOARD_SIZE**2)
loss = -jnp.mean(
jnp.sum(one_hot_labels * jnp.log(logits), axis=-1) * jnp.asarray(rewards))
return loss
def train_step(model_optimizer, params, opt_state, game_board_log,
predicted_action_log, action_result_log):
"""Run one training step."""
def loss_fn(model_params):
logits = run_inference(model_params, game_board_log)
loss = compute_loss(logits, predicted_action_log, action_result_log)
return loss
def compute_grads(params):
return jax.grad(loss_fn)(params)
grads = compute_grads(params)
updates, opt_state = model_optimizer.update(grads, opt_state)
params = optax.apply_updates(params, updates)
return model_optimizer, params, opt_state
@jax.jit
def run_inference(model_params, board):
logits = PolicyGradient().apply({'params': model_params}, board)
return logits这就是训练循环。如下图所示,我们可以在 TensorBoard 中观察训练进度;其中,我们使代理指标“game_length”(完成游戏所需的步骤数)来跟踪进度:若 agent 变得更聪明,它便能以更少的步骤完成游戏。
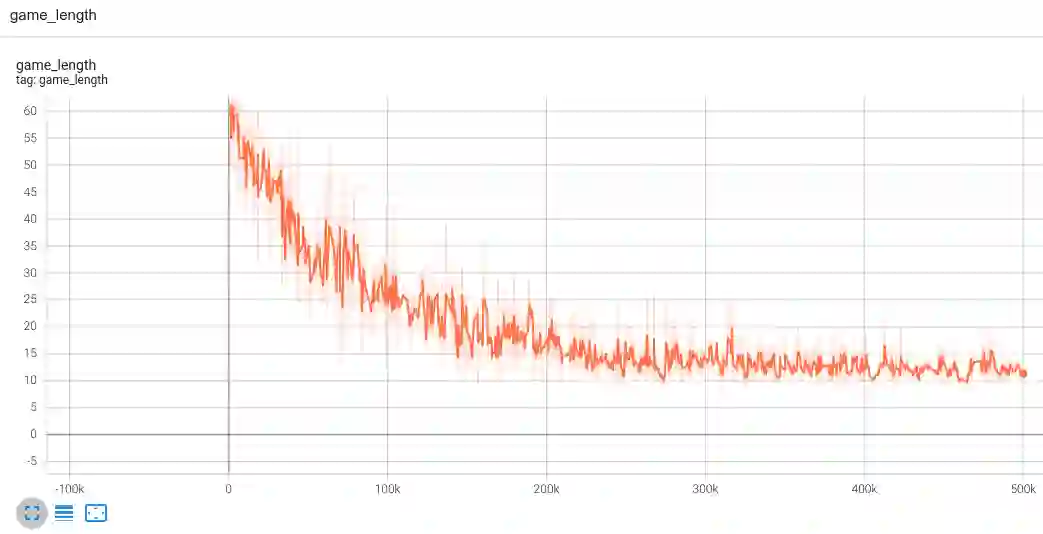
完成模型训练后,我们使用 jax2tf(一款 TensorFlow-JAX 互操作工具),将 JAX 模型转换为 TensorFlow concrete function。最后一步是调用 TensorFlow Lite 转换器来将 concrete function 转换为 TFLite 模型。
jax2tf
https://github.com/google/jax/tree/main/jax/experimental/jax2tf
# Convert to tflite model
model = PolicyGradient()
jax_predict_fn = lambda input: model.apply({'params': params}, input)
tf_predict = tf.function(
jax2tf.convert(jax_predict_fn, enable_xla=False),
input_signature=[
tf.TensorSpec(
shape=[1, common.BOARD_SIZE, common.BOARD_SIZE],
dtype=tf.float32,
name='input')
],
autograph=False,
)
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[tf_predict.get_concrete_function()], tf_predict)
tflite_model = converter.convert()
# Save the model
with open(os.path.join(modeldir, 'planestrike.tflite'), 'wb') as f:
f.write(tflite_model)经 JAX 转换的 TFLite 模型与任何经 TensorFlow 训练的 TFLite 模型会有完全一致的行为。您可以使用 Netron 进行可视化:

使用 Netron 对 Flax/JAX 转换的 TFLite 模型进行可视化
我们可以使用与之前完全一样的 Java 代码来调用模型并获取预测结果。
convertBoardStateToByteBuffer(board);
tflite.run(boardData, outputProbArrays);
float[] probArray = outputProbArrays[0];
int agentStrikePosition = -1;
float maxProb = 0;
for (int i = 0; i < probArray.length; i++) {
int x = i / Constants.BOARD_SIZE;
int y = i % Constants.BOARD_SIZE;
if (board[x][y] == BoardCellStatus.UNTRIED && probArray[i] > maxProb) {
agentStrikePosition = i;
maxProb = probArray[i];
}
}本文详细介绍了如何使用 Flax/JAX 训练简单的强化学习模型、利用 jax2tf 将其转换为 TensorFlow Lite,以及将转换后的模型集成到 Android 应用。
现在,您已经了解了如何使用 Flax/JAX 构建神经网络模型,以及如何利用强大的 TensorFlow 生态系统,在几乎任何您想要的位置部署模型。我们十分期待看到您使用 JAX 和 TensorFlow 构建出色应用!

点击“阅读原文”访问 TensorFlow 官网
不要忘记“一键三连”哦~

分享

点赞

在看