使用 JAX,TFLite 和 Flutter 打造一个棋盘游戏


发布人:windmaple
JAX,TFLite 和 Flutter 是 Google 开源的三个不同的项目,这次我们来看看我们如何同时利用这三个项目来制作一个简单的棋盘游戏😃
因为这个棋盘游戏涉及到在棋盘里选择策略,所以我们需要使用强化学习来训练出一个 agent。大家可能已经知道除了 AlphaGo/AlphaStar 以外,强化学习也被很多游戏公司广泛应用,比如腾讯互娱使用强化学习测试 QQ 飞车,网易伏羲实验室使用强化学习打造易水寒对战 bot,Google Stadia 使用强化学习设计游戏角色的能力。此外,强化学习也被用来进行游戏质量和均衡性测试。
那我们今天就来看看如何使用强化学习制作一个简单的游戏 app,我们把这个小游戏叫做 Plane Strike。项目的代码已经在 GitHub 上开源,最终完成的 app 如下所示:
GitHu
https://github.com/windmaple/planestrike-flutter

这个游戏的规则非常简单(如果有同学玩过一个叫 Battleship 的棋盘游戏就会觉得非常熟悉):玩家和电脑各自拥有一个 8x8 的棋盘,游戏开始的时候双方会在各自的棋盘上放置一个飞机形状的物体,如上图动画中所示最开始左下角的绿色飞机就是玩家放置的飞机,当然飞机的位置对对手来说都是是保密的。玩家和电脑轮流猜测,每次射击对方棋盘的一个位置,如果这个位置碰巧是飞机的格子之一,那么该位置就会变红;如果不是就黄变黄。最终谁先找出对方棋盘上飞机的位置(也就是最开始的 8 个飞机格子),谁就获胜。游戏也会提示双方目前各自击中了对方的几个飞机格子。
下面我们就来看看如何制作这个游戏 app。在讨论具体细节之前,我们先简单介绍一下我们要使用的 3 个工具:
JAX
大家可能对 TensorFlow 比较熟悉,而 JAX 是由 Google Research 团队的 ML 科学家开源出的另一套机器学习框架。有人戏说 JAX 是 numpy on steroids(像吃了兴奋剂的 numpy),是非常高效,简洁,优雅的框架,加上支持 XLA,性能也非常快。这里我们会使用 Flax(JAX 的一个高层神经网络库,JAX-Flax 的关系类似 TensorFlow-Keras 的关系)来训练模型。当然你也可以使用 TensorFlow 或者其他的 JAX 高阶框架(比如 DeepMind 的 Haiku 或者 Google Brain 的 Trax)来训练这个模型。
Flax
https://github.com/google/flax
JAX
https://github.com/google/jax
Haiku
https://github.com/deepmind/dm-haiku
Trax
https://github.com/google/tra
TFLite
TFLite 是 TensorFlow 生态里的重要组件,是性能优越简单易用的移动端推理框架。TFLite 大家可能已经比较熟悉了,TensorFlow 公众号也有很多文章和案例,这里就不再多介绍。大家可以去 B 站收看 TFLite 系列视频教程。如果有兴趣加入 TFLite 兴趣小组,请扫码或添加 “hustwindmaple” 微信。
TFLite 系列视频教程
https://www.bilibili.com/video/BV1EK4y177Sn/

Flutter
Flutter 是 Google 开源的跨平台前端框架,因为简单易用,高效简洁被腾讯、阿里、字节跳动等各大公司广泛使用。Google 开发者公众号也有许多 Flutter 的技术文章,大家可以去进行学习。
Flutter
https://flutter.dev/
因为这个游戏本质上就是看玩家和电脑谁猜的快猜的准,所以我们需要训练一个 agent 来高效的猜出玩家所有的飞机格子。当然你可以通过手工写规则的方式来做这件事,但是那样就比较无趣了。我们在这里会使用强化学习中的一种 policy gradient(也叫 REINFORCE)来训练 agent。
为了实现 REINFORCE,我们首先随机初始化一个简单的 3 个全连接层的神经网络。使用 Flax 定义这个神经网络也非常简单:
class PolicyGradient(nn.Module):
@nn.compact
def __call__(self, x):
dtype = jnp.float32
x = x.reshape((x.shape[0], -1))
x = nn.Dense(features=2*BOARD_SIZE**2, name='hidden1', dtype=dtype)(x)
x = nn.relu(x)
x = nn.Dense(features=BOARD_SIZE**2, name='hidden2', dtype=dtype)(x)
x = nn.relu(x)
x = nn.Dense(features=BOARD_SIZE**2, name='logits', dtype=dtype)(x)
policy_probabilities = nn.softmax(x)
return policy_probabilities提醒大家注意的是 JAX/Flax 和 Keras 有一个显著的不同,那就是模型的参数并不是放在模型里面,而是放在优化器里面,这一点很不一样。
然后我们用这个神经网络来玩一局游戏。开始的时候这个神经网络玩的好坏不重要;只要我们能收集棋盘的位置,每次打击的位置以及是否击中飞机格子的信号就好,然后我们用收集到的这些信息来计算梯度并更新我们的模型参数来优化我们的 agent policy。这也是为什么这个方法叫 policy gradient 策略梯度。当然在计算梯度之前我们也会做一些 reward shaping,让模型学习更高效。
REINFORCE 算法最关键的公式是:
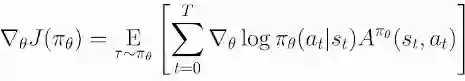
Source:https://spinningup.openai.com/en/latest/algorithms/vpg.html
def compute_loss(logits, labels, rewards):
one_hot_labels = jax.nn.one_hot(labels, num_classes=BOARD_SIZE**2)
loss = -jnp.mean(jnp.sum(one_hot_labels * jnp.log(logits), axis=-1) * jnp.asarray(rewards))
return loss
@jax.jit
def train_iteration(optimizer, board_pos_log, action_log, reward_log):
def loss_fn(params):
logits = PolicyGradient().apply({'params': params}, board_pos_log)
loss = compute_loss(logits, action_log, reward_log)
return loss
grad_fn = jax.grad(loss_fn)
grads = grad_fn(optimizer.target)
optimizer = optimizer.apply_gradient(grads)
return optimizer
大家注意compute_loss() 函数里的 “jnp.asarray(rewards)” 部分,它对应于公式中的 A(也就是 advantage)。这里我偷懒了没实现 advantage,而是直接使用了 reward。对于这个简单模型来说这不是什么问题。
然后我们使用 jax.grad() 函数来计算梯度并使用 apply_gradient() 函数来更新参数。这和 TensorFlow 的 custom training loop 很类似。
强化学习和监督学习有许多不同,比如没有 label。但对我们来说有一点就是我们无法通过查看损失函数值来观察训练进度,因为对强化学习来说损失函数并不能反映训练情况。所以在这里我们通过观察训练过程中游戏的长度(agent 打击了多少个格子才完成游戏)。如果我们训练的 agent 非常强,那么它应该在最少的步数里结束游戏。游戏长度越短,agent 越强。
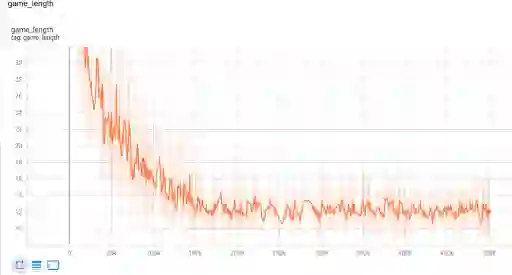
在这里我们可以看到,在大概 25 万次游戏以后,我们的 agent 基本上就收敛了。平均游戏长度大约在 13。也就是说 agent 平均来说只能猜错 5 个格子(因为飞机本身就占 8 个格子)。你也可以使用其他强化学习方法来训练,比如 DQN/PPO,但是 agent 最终的性能应该类似。
训练完成之后我们就可以将我们的 JAX/Flax 模型转化成 TFLite 模型。JAX 的 jax2tf 转化工具还在试验阶段,不过转化我们的模型完全没有问题:
jax2tf
https://github.com/google/jax/tree/master/jax/experimental/jax2tf
# Convert to tflite model
model = PolicyGradient()
predict_fn = lambda input: model.apply({"params": params}, input)
tf_predict = tf.function(
jax2tf.convert(predict_fn, enable_xla=False),
input_signature=[
tf.TensorSpec(shape=[1, BOARD_SIZE, BOARD_SIZE],
dtype=tf.float32,
name='input')],
autograph=False)
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[tf_predict.get_concrete_function()]
)
tflite_model = converter.convert()
with open('planestrike.tflite', 'wb') as f:
f.write(tflite_model)你也可以把模型转化成 SavedModel,然后就可以跟 TensorFlow 的其他组件打通,比如 TF Serving,TFJS 和 TFHub。
有了转化之后的 TFLite 模型,我们就可以把它部署进我们的app中。因为 TFLite 暂时没有提供官方的 Flutter plugin,所以我们可以使用社区开源的 tflite_flutter_plugin。Flutter 和这个插件非常容易使用,我只用了 3 天时间就完成了这个 app 的前端,而我之前一点 Flutter/Dart 都不会。因为 Flutter 自带的跨平台能力,我们很轻易的就能在 Android 和 iOS 上运行我们的小游戏(之后如果 plugin 也支持 desktop 和 web 平台,我也会添加对应的支持)。
tflite_flutter_plugin
https://github.com/am15h/tflite_flutter_plugin
我们的前端其实相对比较简单,只是根据棋盘状态来操作各个格子的颜色。通过 tflite_flutter_plugin 插件,运行 TFLite 模型只需一行代码,也就是这里的 _interpreter.run(input, output):
int predict(List<List<double>> boardState) {
var input = [boardState];
var output = List.filled(_boardSize * _boardSize, 0)
.reshape([1, _boardSize * _boardSize]);
// Run inference
_interpreter.run(input, output);
// Argmax
double max = output[0][0];
int maxIdx = 0;
for (int i = 1; i < _boardSize * _boardSize; i++) {
if (max < output[0][i]) {
maxIdx = i;
max = output[0][i];
}
}
return maxIdx;
}所以这大概就是我们制作这个 app 的主要部分。在这里我们同时使用了 JAX/TFLite/Flutter 来打造这样一个简单的棋盘游戏 app。这三个产品在各自的领域都非常非常的酷。
当然这个小游戏还有很多可以优化的地方,尤其是前端 UI 部分。但是对于演示目的来说我们在这里也展示一个端到端的过程,相信能够帮助大家起步,也欢迎大家到 GitHub 上查看完整代码。
GitHub
https://github.com/windmaple/planestrike-flutter

强化学习部分代码来自这篇文章:
https://www.efavdb.com/battleship

点击“阅读原文”访问 GitHub
不要忘记“一键三连”哦~

分享

点赞

在看




