CVPR2019:中国企业斩获无数冠军,见证华人星耀时刻!
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
为中华之崛起
文 | 杨鲤萍
本文授权转载自:雷锋网

6 月 18 日,三大世界顶级计算机视觉会议之一「计算机视觉与模式识别会议」(Conference on Computer Vision and Pattern Recognition 2019,CVPR 2019)在美国长滩拉开帷幕,顶会吸引全球超过9200位顶尖专家、学者以及产业界人士,共同推进 CV 技术的发展与落地。
相比 2018 年,本届 CVPR 的论文提交数量增加了 56%,但论文接收率却下降了 3.9%,可见论文入选难度加大;而学术比赛报名人数也保持持续增长。但无论在论文方面还是学术比赛中,今年多家中国企业都取得了可喜的成绩,这些成绩不仅体现了这些企业的发展水平,也代表了国人的科技进步。雷锋网 AI 科技评论现将其成果整理报道如下。
商汤科技 CVPR 2019 录取论文在多个领域实现了突破,其中代表性论文有:《基于混合任务级联的实例分割算法》、《基于特征指导的动态锚点框生成算法》(高层视觉核心算法——物体检测与分割);《基于网络参数插值的图像效果连续调节》、《基于光流引导的视频修复》(底层视觉核心算法——图片复原与补);《PointRCNN: 基于原始点云的 3D 物体检测方法》(面向自动驾驶场景的 3D 视觉);《基于人体本征光流的姿态转换图像生成》(面向 AR/VR 场景的人体姿态迁移);《基于条件运动传播的自监督学习》(无监督与自监督深度学习前沿进展)等。这些突破性的计算机视觉算法不仅有着丰富的应用场景,也为 AI 行业的发展做出了巨大的贡献。
而在 CVPR 2019 Workshop NTIRE 2019 视频恢复比赛中(包含两个视频去模糊和两个视频超分辨率),来自商汤科技、香港中文大学、南洋理工大学、中国科学院深圳先进技术研究院组成的联合研究团队使用 EDVR 一套算法,获得了全部四个赛道的所有冠军,并且每个结果都大幅超越赛道第二名。
在论文《EDVR: Video Restoration with Enhanced Deformable Convolutional Networks》中,作者介绍了这种新型算法,通过一种新的网络模块 PCD 对齐模块,使用 Deformable 卷积进行视频的对齐,可以实现整个过程端到端的训练;而在挖掘时域(视频前后帧)和空域(同一帧内部)的信息融合时,作者又提出了一种时空注意力模型,来进行更好的信息融合。
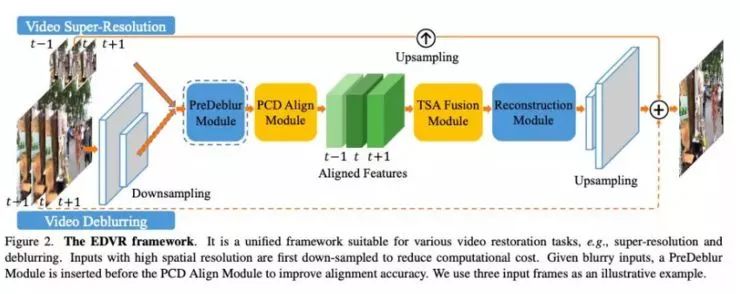
EDVR 算法架构
因此,在将 EDVR 算法视频超分辨率与目前行业最好的图像超分辨算法 RCAN 恢复来对同一区域进行处理时,可以明显看到 EDVR 算法视频超分辨能给到更多的细节。(该方法的代码已开源)
另外,商汤科技还在 AI CITY Challenge(CVPR 2019 Workshop)异常检测赛道中获得冠军。城市智慧交通一直都面临着数据质量差、标签数据少、缺乏高质量算法模型以及从边缘到云端的计算资源不足等挑战,而比赛中,商汤科技的设计更多地通过迁移学习、无监督和半监督的方法检测交通异常,如道路事故、车辆故障等,从而达到更好的帮助城市交通变得安全和智能这一目的。
EDVR 论文地址
https://arxiv.org/abs/1905.02716v1
EDVR 开源地址
https://github.com/xinntao/EDVR
百度 17 篇论文被大会收录,
获 10 项 CVPR 2019 竞赛冠军
在今年的 CVPR 上,百度共有 17 篇论文被接收,内容涵盖了语义分割、网络剪枝、ReID、GAN 等诸多方向,并且其中很多技术都设计到无人驾驶相关场景。
其中包括《Taking A Closer Look at Domain Shift: Category-level Adversaries for Semantics Consistent Domain Adaptation》(https://arxiv.org/abs/1809.09478)中,提到了结合了联合训练和对抗训练来处理虚拟图像与真实图像之间语义分割网络训练差异的问题,将该技术应用在自动驾驶中,可以大大减少数据标注和采集的工作量。
《Sim-Real Joint Reinforcement Transfer for 3D Indoor Navigation》(https://arxiv.org/abs/1904.03895)中提出的视觉特征适应模型和策略模拟模型,可以有效将机器人在虚拟环境中学习到的策略和特征迁移到实际场景中;《ApolloCar3D: A Large 3D Car Instance Understanding Benchmark for Autonomous Driving》一文提出目前已知自动驾驶领域最大规模的三维车辆姿态数据集,可以更好的对单张图像的车辆姿态估计。
而在 CVPR 相关竞赛任务中,百度一共获得了 10 项冠军,涵盖众多热门领域——
视觉领域下的视频理解与分析:包括视频动作提名、视频动作检测两项任务的冠军,以及新增任务 EPIC-Kitchens 动作识别挑战赛中获两项测试集冠军(Seen kitchens 和 Unseen kitchens);
目标检测:「Objects365 物体检测」国际竞赛 Full Track 冠军,NTIRE 竞赛中获得图像超分辨项目冠军;
人体检测:Look Into Person 国际竞赛中三项人体精细化解析竞赛单元(Track1:Single-Person Human Parsing,Track3:Mult-Person Human Parsing,Track4:Video Multi-Person Parsing)中,均获得第一名;
人脸活体检测:在 CVPR-19-Face Anti-spoofing Attack Detection Challenge 上,百度击败了 300 多个队伍,最终获得第一的好成绩;
智能城市车辆识别:AI-city 公开赛城市范围多摄像头车辆重识别任务第一名;
在 CVPR 2019 上,百度 Apollo 还首次曝光 L4 级自动驾驶纯视觉解决方案。Apollo 技术委员会主席王亮就 L4 级全自动驾驶(Fully Autonomous Driving)环境感知技术方案进行了讲解,并公开了环视视觉解决方案百度 Apollo Lite。并表示经过前期的技术研发投入和 2019 年上半年的路测迭代,依靠这套 10 相机的感知系统,百度无人车已经可以在城市道路上实现不依赖高线数旋转式激光雷达的端到端闭环自动驾驶。
旷视 14 篇论文被接收,
并斩获 CVPR2019 挑战赛 6 项世界冠军
在 CVPR 2019 上,旷视研究院通过 Oral、Poster、Workshop、Demo、Booth 等形式,同世界分享在计算机视觉理论与应用领域的最新进展。
相比去年旷视科技有 8 篇论文被收录,今年他们又多了 6 篇被 CVPR 所接收。这 14 篇论文涉及行人重识别、场景文字检测、全景分割、图像超分辨率、语义分割、时空检测等技术方向。
并在顶会的 CVPR 2019 WAD(Workshop on Autonomous Driving)、CVPR 2019 FGVC(Workshop on Fine-Grained Visual Categorization)、CVPR 2019 NTIRE(New Trends in Image Restoration and Enhancement workshop)3 项挑战赛中,击败 Facebook、通用动力、戴姆勒等国内外一线科技巨头与知名高校,一举拿下 6 项世界冠军,内容涵盖自动驾驶、新零售、智能手机、3D 等众多领域。
其中挑战赛 NTIRE 2019 真实图像降噪比赛,致力于恢复与增强图像质量。到目前为止,已连续举办了 3 年。今年 NTIRE 挑战赛下设 11 项比赛,旷视研究院参赛的「真实图像降噪(Real Image Denosing Challenge)」中,共有来自全球的 216 位选手、12 支队伍。和往年不同,今年的图像降噪赛是针对真实而非合成的图像去评估图像降噪器。该项比赛根据图像储存的两种格式——原始传感器数据(raw)和标准 RBG(sRGB),分为对应的两项子赛。
旷视研究院参战 raw 图像去噪,提出了针对 raw 图像的基于 U-Net 框架的「拜尔阵列归一化与保列增广」方法。团队精心设计了一种数据预处理方法,使得不同输入图像间的数据能保持网络输入一致性,从而应用到具有不同拜耳模式的输入上,在保证性能的前提下用更大的图像集合训练网络。此外,团队还提出了适用于 raw 图像的数据增广方法,这些优势可以帮助网络获得更好的泛化能力。
而且旷视的冠军算法已成功落地于 OPPO Reno 10 倍变焦版。OPPO Reno 10 倍变焦版搭载了基于旷视 MEGVII 超画质技术研发的「超清夜景 2.0」功能,能够为用户提供更好的夜拍体验。这也是旷视超画质技术首次运用在大规模量产机型上。
京东 AI 在 CVPR 2019 共发表 12 篇论文,
斩获 3 项冠军和 2 项亚军
本次京东 AI 研究院在 CVPR 2019 上一共发表 12 篇论文,其中 4 篇论文入选了 oral presentation(oral presentation 的入选率只有 5%),入选 oral presentation 的四篇论文包含:
《ScratchDet: Exploring to Train Single-Shot Object Detectors from Scratch》(https://arxiv.org/abs/1810.08425v3)
《Transferrable Prototypical Networks for Unsupervised Domain Adaptation》(https://arxiv.org/abs/1904.11227)
《Unsupervised Person Image Generation with Semantic Parsing Transformation》(https://arxiv.org/abs/1904.03379)
《Gaussian Temporal Awareness Networks for Action Localization》(https://docs.wps.cn/view/p/35402862179?from=docs&source=docsWeb)
其中京东 AI 研究院提出的 ScratchDet,则从优化的角度出发,通过实验解释了梯度稳定手段之一的 BatchNorm 如何帮助随机初始化训练检测器,进而结合了 ResNet 与 VGGNet 来加强对小物体的检测。并将这一技术成功运用在了其他任务上,如人脸检测、文字检测等,这对于计算机视觉的发展有着重大的意义。
在学术比赛方面,京东 AI 研究院在 CVPR 2019 上共获得三项第一,分别是:视频动作识别、商品图片识别,以及精细粒度蝶类图片识别;而在多人人体解析、菜品类图像识别竞赛中获得第二名。
视频动作识别被视为 ActivityNet 中最核心、最基础的任务。在本届 ActivityNet 视频动作识别任务(Kinetics)比赛中,共有 15 支来自于美国卡耐基梅隆大学、百度、Facebook 人工智能研究院、上海交通大学 MVIG 实验室等国际知名研究机构的参赛队伍。而京东 AI 凭借着他们所提出的一种新框架——通过局部和全局特征传播(LGD)学习视频中的空间、时间特征,最终在众多强劲参赛者中脱颖而出。
在精细图像识别 (Fine-Grained Visual Categorization) 学术比赛中,今年比赛图片数量和商品数据类别分别是去年的 5 倍和 40 倍,挑战性相应也有大幅度提升;全球共有 96 支队伍、152 位选手通过 1600 次提交参加了竞赛,而最终京东 AI 靠着基于自研的全新精细图像分类算法获得了冠军。该算法通过按块「破坏」图像中的结构信息,然后再令已经训练的神经网络进行重点视觉区域识别与抓取,进而识别物品本身;更值得注意的是,这一技术不光可以达到高准确率,同时还有很强的兼容性。相关研究成果更多详情可在论文《Destruction and Construction Learning for Fine-grained ImageRecognition》(https://docs.wps.cn/view/p/35402900346?from=docs&source=docsWeb)中获得。
阿里 AI 在该竞赛由谷歌、美国卡耐基梅隆大学、苏黎世联邦理工大学等机构联合全球视觉技术领域顶级学术会议 CVPR 发起的第三届图像识别竞赛 WebVision 中获得冠军,要求参赛的 AI 模型将 1600 万张图片精准分类到 5000 个类目中,最终阿里的识别准确率 82.54%,将万物识别领域的历史纪录提升了 3 个百分点。
而就在今年 3 月中,阿里与深圳大数据研究院、香港中文大学(深圳)、大连理工大学以及中国科学技术大学共同完成《Deep Reinforcement Learning of Volume-guided Progressive View Inpainting for 3D Point Scene Completion from a Single Depth Image》被收录为 Oral Presentation。
之后与哈尔滨工业大学、香港理工大学、深圳鹏城实验室联合设计的超分辨率算法——能够很好的应对模糊降质的 DPSR 技术(来自论文《Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels》),也被 CVPR 2019 所接收。并且该算法已经开源了代码(https://github.com/cszn/DPSR);在另一篇被接收的论文《ODE-Inspired Network Design for Single Image Super-Resolution》中,阿里与中科院、中科院大学也展示了他们一起在图像超分辨率方面做出相应研究
FGVC 全称为 Fine-Grained Visual Categorization,即区分不同的动物和植物、汽车和摩托车模型、建筑风格等,是机器视觉社区刚刚开始解决的最有趣和最有用的开放问题之一。细粒度图像分类在于基本的分类识别(对象识别)和个体识别(人脸识别,生物识别)之间的连续性;不同于传统的广义上的分类任务,FGVC 的挑战致力于子类别的划分,需要分类的对象之间更加相似,例如区分不同的鱼类、同一植物不同形态、不同的生活用品等。
在今年 CVPR 的 FGVC6 Workshop 赛区,共有十个挑战赛,每个都代表了细粒度视觉分类在某个细分领域的挑战。今年此次挑战赛共有来自全球 88 个团队参与,提交了超过 1300 份方案。而在 Kaggle 上举办的 CVPR 2019 Cassava Disease Classification(根据木薯的叶子区分不同种类的木薯疾病的任务)挑战赛中,DeepBlue AI 通过图像增强方法来降低过拟合的风险,并提高模型的鲁棒性,同时利用多个在 ImageNet 表现优异的模型,以集成方法提升精度,最终获得了冠军。
除了该项挑战赛,同期深兰科技还在在 CVPR 的另外两项比赛 2019 Workshop on Autonomous Driving (WAD) D²-City & BDD100K Tracking Domain Adaptation Challenge and the D²-City & BDD100K Detection Domain Adaptation Challenge.(目标检测迁移学习、目标跟踪迁移学习挑战赛和大规模检测插值探索赛)分获亚军和季军。
今年的 CVPR 上,机器学习图像压缩挑战赛(CLIC)由 Google 联合 twitter、Netflix 等赞助。如今由于手机像素的提升,占用大部分内存空间的图片对于移动存储设备和网站来说都是很大的负担;而对图片进行高效高质的压缩处理,已经成了众多互联网企业的极大需求。因此,在本届会议上,图像压缩也成了技术焦点之一。
在去年,图鸭科技曾夺得过该挑战赛的 MS-SSIM 与 MOS 两项第一;而今年,他们也带来了更强的技术,最终在 MS-SSIM、Transparent Track、PSNR、Perceptual Qualit 四项指标上均夺得桂冠,向世界展示了他们的技术硬实力,成为世界图像压缩历史大满贯赢家。
美团无人配送与视觉团队在本届 CVPR 上,也获得了很好的成绩,分别在障碍物轨迹预测挑战赛(Trajectory prediction challenge)中斩获第一名和商品识别挑战赛(iMaterialist Challenge on Product Recognition)获得第二名。
对于美团无人配送与视觉团队来说,这不光只是一种荣誉,也向我们展现出了他们在自动驾驶技术和视觉图像方面进行的大量研究和产品化探索,并在场景应用方面所积累的丰硕成果。
美图影像实验室 MTlab 此次参加了图像增强和图像去雾两个比赛,两个比赛均收到了超过 200 支团队报名。
最终,在图像增强赛道(Image Enhancement Challenge)中,美图影像实验室 MTlab 获得了冠军;在图像去雾赛道(Image Dehazing Challenge),美图影像实验室 MTlab 获得了季军。
本届 AI 城市大赛(AI City Challenge)共有来自全球超过 200 支顶尖队伍参与,滴滴在 CVPR AI 城市比赛(AI City Challenge)中最终获得了亚军,并携手加州大学伯克利分校 DeepDrive 深度学习自动驾驶产业联盟(BDD)一同举办了 CVPR 2019 自动驾驶研讨会,详细介绍了滴滴在自动驾驶领域的探索和实践。
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按关注极市平台
觉得有用麻烦给个在看啦~