Youtube推荐中的深度神经网络应用

广告推荐算法系列文章:
-
莫比乌斯: 百度的下一代query-ad匹配算法 -
百度凤巢分布式层次GPU参数服务器架构 -
DIN: 阿里点击率预估之深度兴趣网络 -
基于Delaunay图的快速最大内积搜索算法 -
DIEN: 阿里点击率预估之深度兴趣进化网络 -
EBR: Facebook基于向量的检索 -
阿里巴巴电商推荐之十亿级商品embedding -
TDM: 基于树的深度学习模型在阿里推荐系统中的应用 -
Youtube推荐中的深度神经网络应用(本篇)
Overall
从上述链接中可以看到,之前读的文章都是最近两年的。今天则给大家介绍一篇稍微久远点的,2016年的论文,追本溯源,或许能更好的理解推荐算法的变化和设计的初衷。
论文[1]中的Youtube的推荐是指在youtube首页上的推荐。
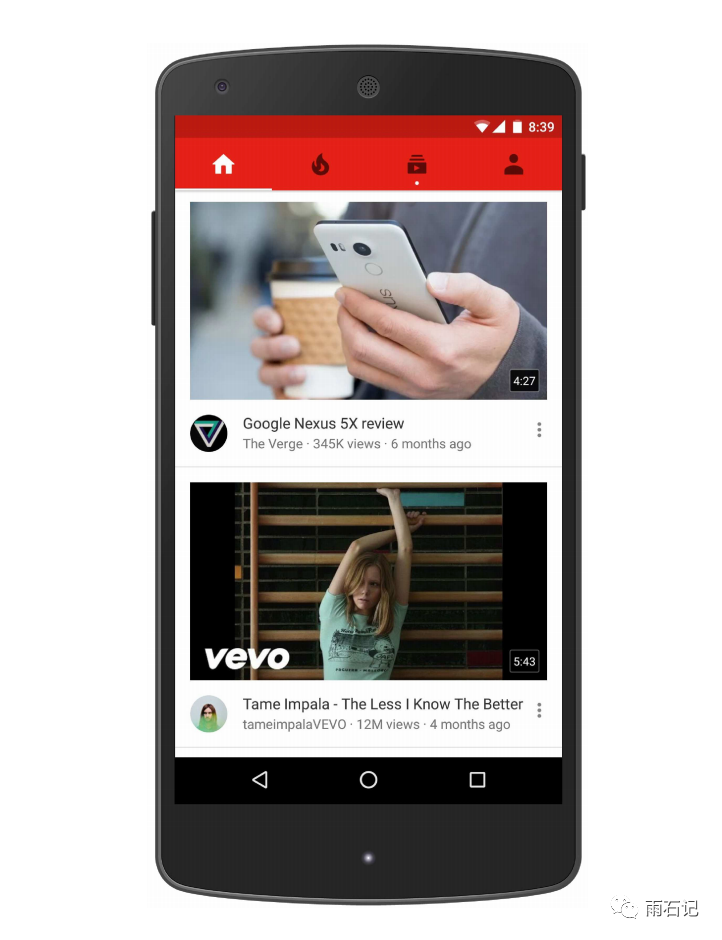
Youtube的推荐系统主要面临三个挑战:
-
Scale: 可扩展性,很多在小数据集上表现好的算法到了大数据集上表现不好。 -
Freshness: youtube上每秒上传的新视频非常多,但是这些视频却没有操作记录。如何对这部分视频做推荐很能影响用户在youtube上的使用时长。 -
Noise: 用户在youtube上的行为非常稀疏,有很多不可见的外部因素,因而预测很难。
系统架构
整个系统分为两部分,candidate generation和ranking。这点我们在之前已经多次讲过了,candidate generation负责生成候选集,ranking负责精排。
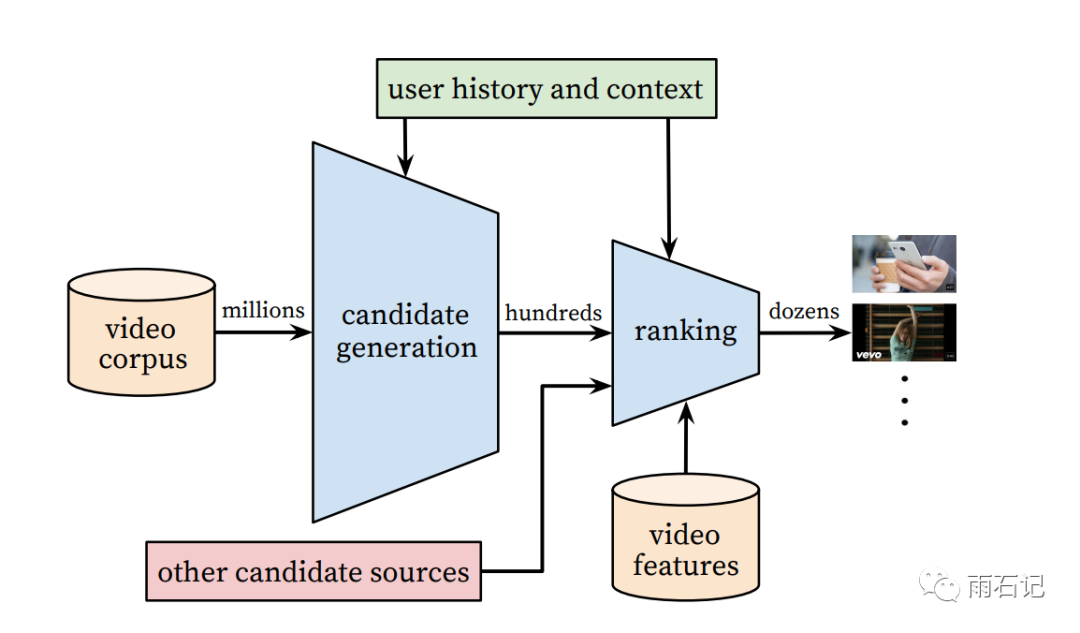
这种两个阶段的结构也能够很方便的利用之前的模块生成候选集合。
候选生成
16年往前,生成候选的方法是协同过滤,但是有了神经网络之后,自然要更新模型。在这里,把候选生成建模成了多分类问题。基于用户信息和上下文信息,对每个视频进行预测,看是不是要加入到候选集。
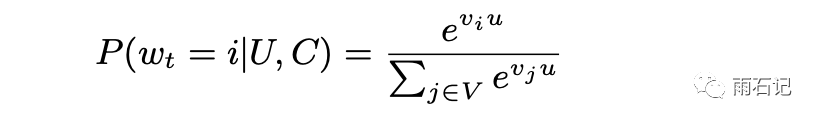
但是对所有视频都做预测显然不切实际,视频数据可能多达上亿。因此,在训练的时候会进行负采样,正例是用户看完的视频,负例是采样出来的,大概几百个。这样训练非常高效。
另一个可选的方法是层次softmax,但是实验表明这个效果不好。
而在预测阶段,显然线性遍历视频集合也是不可行的,所以使用基于哈希的方法来做最近邻搜索。
正例之所以使用看完的视频而不是点赞等其他行为,是因为其他行为都太稀疏。
候选生成的模型架构如下,首先,每个视频都有一个embedding,然后将用户观看历史中的最后N条做averaging,得到watch vector,同理,得到search vector以及其他特征。同时,为了降低非线性特征组合对模型的依赖,手动提取了一下非线性特征。得到了这么多特征后,拼接然后输入给多层神经网络。
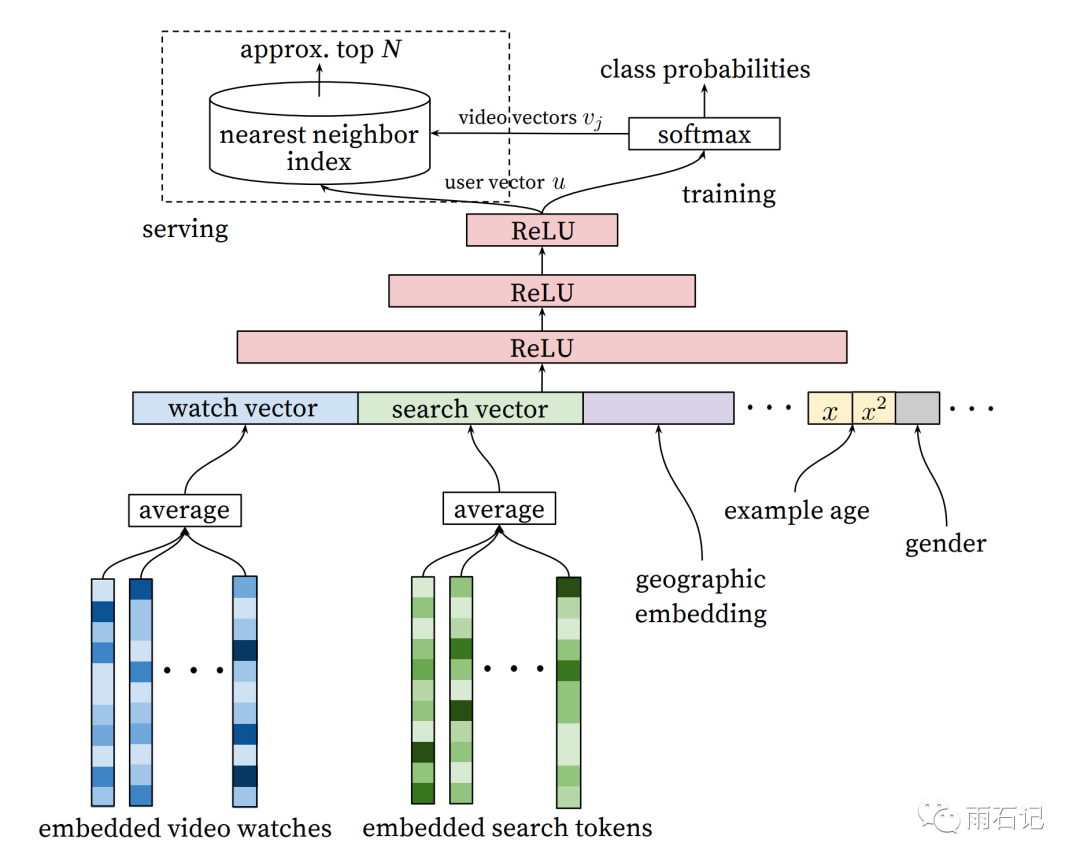
使用了DNN之后,一个很强的优势就是任意的连续的或者离散的特征都可以比较简单的添加进模型中来。如上所述,在这个模型中,搜索历史被处理的方式和观看历史的处理是很类似的,但搜索历史是字符串,因而,在embedding的时候,可以提取unigram,bigram等。
人口特征非常重要,因为他们决定了系统在新用户上的推荐效果。人口特征包括年龄,登录状态,性别等。
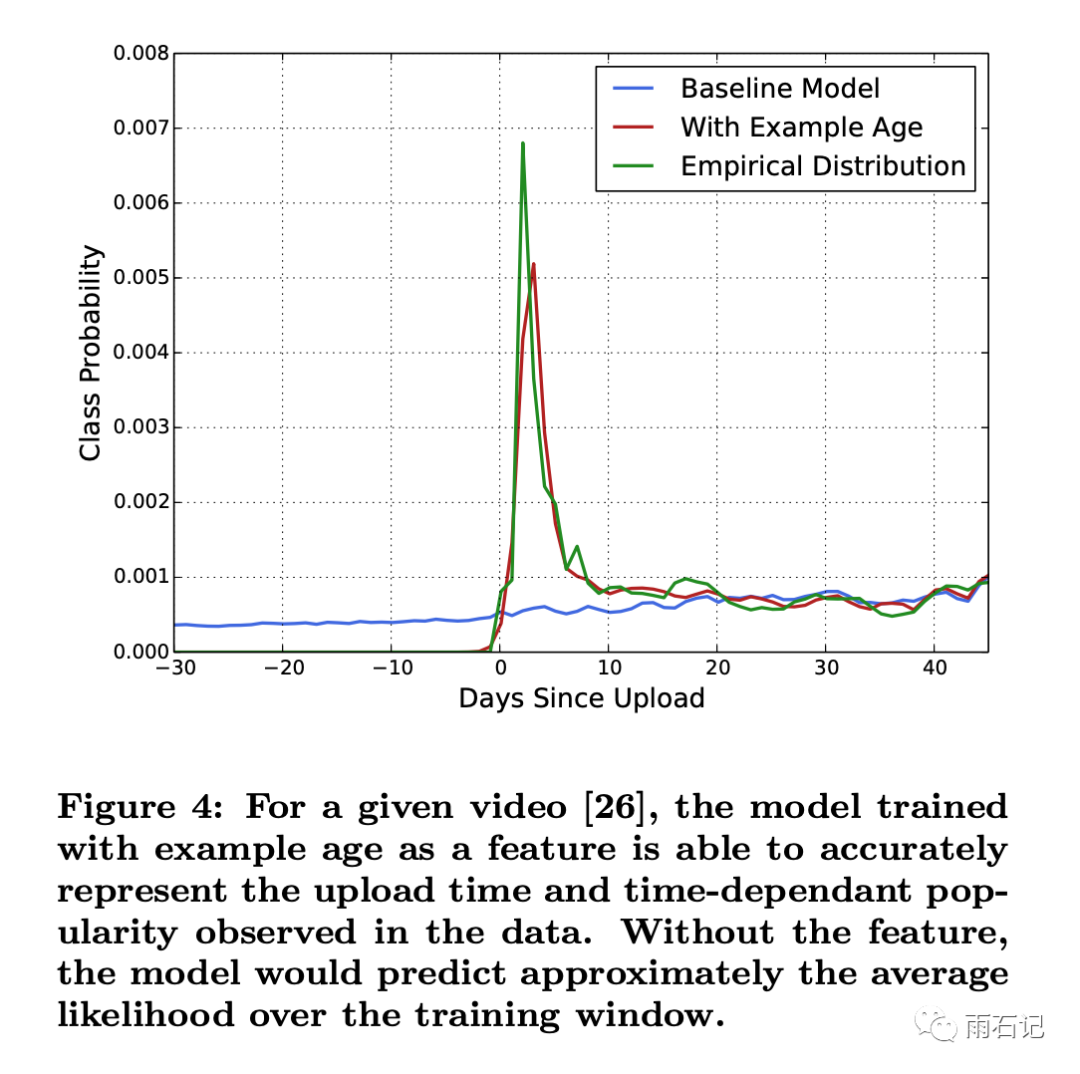
在youtube上,每秒都会有很多新的video被上传,如何对这些视频做推荐非常重要,这就是推荐系统中常遇到的Freshness问题。经过数据分析,发现用户比较倾向于新视频,甚至可以为了新视频而放弃部分相关度。如下图所示,视频被上传的时间和被观看的概率的关系如下,因此,在模型中,需要加入视频的年龄从而使得模型能够正确预测新视频被观看的概率。
排序
在这一阶段,需要对候选集中的视频进行精确的排序,因此,这一步骤中需要接触到更多的特征信息。
采用的模型如下,模型结构还是多层神经网络,重点在提取的特征。
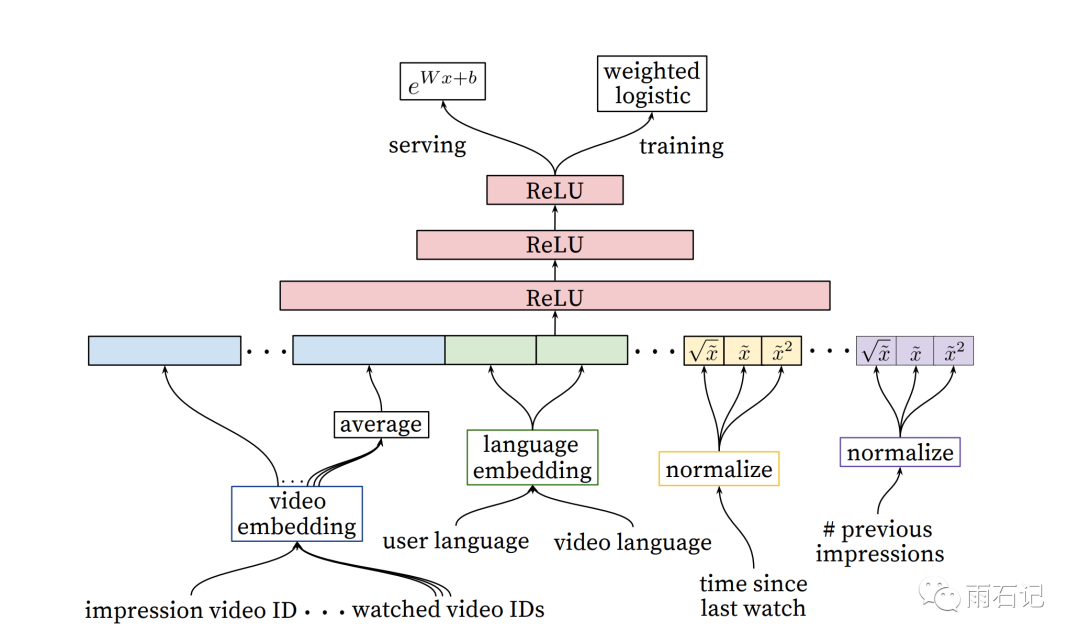
提取的特征可以分为两大类,连续特征和离散特征,这个模型中使用的特征有几百个。虽然深度学习可以大大缓解在特征工程方面的人力,但为了保证效果,这部分仍然花费了大量的人力。
这个模型中比较重要的特征大都是描述用户之前和这个视频或者类似视频的互动。比如,对于一个视频来说,用户观看过多少跟这个视频在同一个频道的视频?上次用户观看同主题视频的时间是什么?
除此之外,候选视频的来源也很重要,需要将候选视频的来源以及它被产生时的评分也作为特征加入进来。
还有,视频被展示的频次也应该被考虑进来,如果上次展示给用户但并没有被点击,那么下次推荐时就不应该再出现。
对于离散特征来说,跟候选生成模型类似,还是使用embedding来把离散特征转为密集特征,对于在一个空间里的特征,embedding可以共享。
提取完特征后,需要对特征进行归一化,因为模型对特征值的分布很敏感。同时,为了缓解模型的非线性学习压力,还会特意对某些特征做一些数学变换比如根号,平方等,将这些变换后的特征也输入给模型。
在目标函数上,需要优化的目标是观看时长最大,所以使用的损失函数是按照时长进行加权的,正例用时长加权,负例则使用单位权重。
总结
作为DNN在推荐系统上应用的比较早的工作,本文在候选生成和精排上分别介绍了DNN是如何做应用的,模型很简单,都是多层神经网络,但特征工程工作量很大,需要做很多的分析,比如视频年龄这个特征的发现。
本文之后,其他团队有更多的工作分别在候选生成和精排上继续深耕。例子可见本文开头的文章列表。
参考文献
-
[1]. Covington, Paul, Jay Adams, and Emre Sargin. "Deep neural networks for youtube recommendations." Proceedings of the 10th ACM conference on recommender systems. 2016.
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



