DNN在搜索场景中的应用
DNN在搜索场景中的应用潜力,也许会比你想象的更大。 --《阿里技术》
1.背 景
搜索排序的特征在于大量的使用了LR,GBDT,SVM等模型及其变种。主要在特征工程,建模的场景,目标采样等方面做了很细致的工作。但这些模型的瓶颈也非常的明显,尽管现在PS版本LR可以支持到50亿特征规模,400亿的样本,但这看起来依然是不太够的,现在上亿的item数据,如果直接使用id特征的话,和任意特征进行组合后,都会超出LR模型的极限规模,对于GBDT,SVM等模型的能力则更弱,而我们一直在思考怎么可以突破这种模型的限制,找到更好的特征;另外,及时LR模型能支持到上亿规模的特征,在实时预测阶段也是有极大的工程挑战,性能与内存会有非常大的瓶颈。
所以我们第一考虑到的是降维,在降维的基础上,进一步考虑特征的组合。所以DNN(深度神经网络)很自然进入了我们的考虑范围。再考虑的是如果把用户行为序列建模起来,我们希望是用户打开手淘后,先在有好货点了一个商品,再在猜你希望点了一个商品,最后进入搜索后会受到之前的行为的影响,当然有很多类似的方法可以间接实现这样的想法。但直接建模的话,LR这类的模型,很难有能力来支持这类特征,所以很容易就想到了RNN模型。
2.相 关 工 作
同时前人有很多工作给予了我们提示。Deep Learning over Multi-field Categorical Data这篇paper开始使用id类的特征进行CTR预估。
Google也推出Wide & Deep Learning for Recommender Systems的Wide&Deep模型用于推荐场景。在FNN的基础上,又加上了人工的一些特征,让模型可以主动抓住经验中更有用的特征。


3. Deep Learning模型
在搜索中,使用了DNN进行了尝试了转化率预估模型。转化率预估是搜索应用场景的一个重要问题,转化率预估对应的输入特征包含各个不同域的特征,如用户域,宝贝域,query域等,各种特征的维度都能高达千万,甚至上亿级别,如何在模型中处理超高维度的特征,成为了一个亟待解决的问题,简单的线性模型在处理高维稀疏特征存在比较好的优势,但是单一的线性模型无法处理特征交叉的问题,比如,我们在转化率预估时并不能单独只考虑宝贝维度的转化率,而更需要考虑用户到宝贝的转化率或者query到宝贝的转化率,这种情况下,我们使用单一维度的线性模型就无法解决现有问题,而需要人工构造高阶的组合特征来完成,会消耗巨大的计算量。
大规模id特征实时深度神经网络模型,可以处理上亿维度的id类输入特征,并通过复杂神经网络结构对不同域的特征(用户,宝贝,query)进行特征组合,解决了单一线性模型无法处理特征交叉的问题,同时也避免了人工构造高阶组合特征的巨大计算量。
深度神经网络通过构造稀疏id特征的稠密向量表示,使得模型能有更好的泛化性,同时,为了让模型能更好的拟合大促期间商品特征数据的剧烈变化,在深度网络的最后一层增加商品id类特征,id组合特征和实时的统计量特征,使得整个网络同时兼顾泛化性和实时性的特点。

wide model
a. id feature: item_id, seller_id,学习已经出现过的商品,卖家在训练数据上的表现。
b. id cross feature: user_id x item_id , user_id x seller_id
连续值统计特征是非常有用的特征,Google的模型是把embedding向量和统计特征放到同一个DNN网络中学习,但实验发现这样会削弱统计特征的作用。我们为统计特征专门又组建了一个包含2个隐层的网路,并且为了增强非线性效果,激活函数从RELU改为TanH/Sigmiod。
Deep Model
a. 首先需要把离散特征(item_id,item_tag, user_id,user_tag,query_tag)embeding成连续特征。
b. 将embedding后的向量作为DNN的输入。考虑到最终线上预测性能的问题,目前我们的DNN网络还比较简单,只有1到2个隐层。
整体模型使用三层全连接层用于sparse+dense特征表征学习,再用两层全连接层用于点击/购买与否分类的统一深度学习模型解决方案:
第一层为编码层,包含商品编码,店家编码,类目编码,品牌编码,搜索词编码和用户编码。
在普适的CTR场景中,用户、商品、查询等若干个域的特征维度合计高达几十亿,假设在输入层后直接连接100个输出神经元的全连接层,那么这个模型的参数规模将达到千亿规模。直接接入全连接层将导致以下几个问题:1. 各个域都存在冷门的特征,这些冷门的特征将会被热门的特征淹没,基本不起作用,跟全连接层的连接边权值会趋向于0,冷门的商品只会更冷门。2. 模型的大小将会非常庞大,超过百G,在训练以及预测中都会出现很多工程上的问题。为了解决上述两个问题,本文引入了紫色编码层,具体分为以下两种编码方式:1. 随机编码 2. 挂靠编码,下面将对以上两种编码方式进行详细的描述。
随机编码
假设某一域的输入ID类特征的one-hot形式最大维度为N,其one-hot示意图则如下所示:
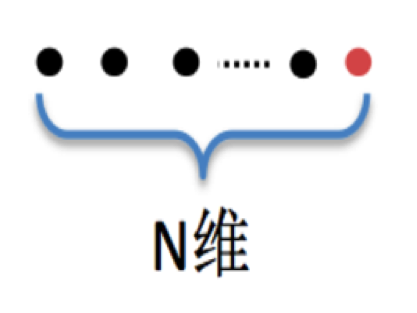
其中黑色为0,只有红色为1,该特征表达方式即为one-hot形式,在这种表达形式下有两个硬规则:1. 任何两个不同的特征都只有一个元素为1。 2. 没有交叉重叠的红色为1的元素。
倘若打破以上两个规则,让one-hot变成six-hot,并且让两两six-hot中最多允许有三个为1的元素是重叠的,那么对1w维的每个one-hot特征都可以找到一个随机的six-hot特征与其对应,并且可以将这six-hot的最高维设置为500,在这种情况下可以将1w维的one-hot特征压缩到500维,实现20倍的特征压缩,如果输入特征是N万维,则可以将其分成N段,并且在每一段里根据上述寻找到的随机码本进行特征压缩,最后N万维的one-hot特征可以采用以上six-hot形式将其压缩到N/20万维,并且保证两两特征最多只有三个为1的元素是重叠的,示意图如下所示:

通过以上任一一种的编码方式,都可以实现模型大小将近20倍的压缩,使得百亿规模的模型参数压缩到了几亿维规模,但几亿规模参数的模型前向将会达到秒级,对于几十亿样本的模型训练,以及CTR模型的前向来讲将会是一个灾难,接下来将描述如何采用红色稀疏全连接层进行模型前向以及后向的时间压缩。
挂靠编码
上述的随机编码对用户域非常适用,但对商品域而言,虽然冷门商品会一定概率跟热门商品重叠一些为1的元素共享一些连接边权值,缓解了冷门商品越冷门的问题。但这里并没有利用好相似商品的信息,如何利用相似商品的信息,将冷门的商品与非冷门的相似商品建立共享权值?假设非冷门商品采用one-hot编码,冷门商品采用M-hot编码,如果冷门商品能通过i2i找到对应的热门商品,则该冷门商品共享一维该热门商品的编码,另外M-1维编码采用随机编码;否则,直接对M维进行随机编码。假设非冷门商品A的one-hot编码最后一位为1,冷门商品B通过i2i找到相似非冷门商品A,冷门商品B采用six-hot编码,则其挂靠编码示意图如下:

分词编码
上述的两种编码很好的解决了用户域与商品域的编码问题,但对查询域还是不够。在对查询域做处理的时候,往常模型往往会对查询短语先进行ID化,然后通过近义词合并一些ID,再经过热门查询词统计来筛选出大概几百W的热门查询ID,然后就会输入到模型中。
在以上的流程中,无法处理有重叠词语的两个查询短语的关系,比如“红色连衣裙”,“红色鞋子”,这两个查询短语都有“红色”这个词语,但是在往常的处理中,这两者并没有任何关系,是独立的两个查询ID,如此一来可能会丢掉一些用户对某些词语偏好的pattern。
基于以上观察,可以对查询短语首先进行分词,然后对每个词语进行one-hot编码,最后针对每个查询短语进行合并词语编码,也就是每个查询短语元素为1的个数是不定长的,它元素1的个数是由自身能分成多少个词语来决定的。分词编码的示意图如下:

从第二层到第四层组成了“域间独立”的“行为编码网络”,其中第二层为针对稀疏编码特别优化过的全连接层( Sparse Inner Product Layer ),通过该层将压缩后的编码信息投影到16维的低维向量空间中,第三层和第四层均为普通全连接层,其输出维度分别为16和32。“行为编码网络”也可以被看做是针对域信息的二次编码,但是与第一层不同,这部分的最终输出是基于行为数据所训练出来的结果,具有行为上相似的商品或者用户的最终编码更相近的特性。
第五层为concat层,其作用是将不同域的信息拼接到一起。
第六层到第八层网络被称为“预测网络”,该部分由三层全连接组成,隐层输出分别为64,64和1。该部分的作用在于综合考虑不同域之间的信息后给出一个最终的排序分数。
最后,Softmax作为损失函数被用在训练过程中; 非线性响应函数被用在每一个全连接之后。
Online Update
双11当天数据分布会发生巨大变化,为了能更好的fit实时数据,我们将WDL的一部分参数做了在线实时训练。embeding层由于参数过多,并没有在线训练,其他模型参数都会在线学习更新。
deep端网络参数和wide端参数更新的策略有所不同,wide端是大规模稀疏特征,为了使训练结果有稀疏性,最好用FTRL来做更新。deep端都是稠密连续特征,使用的普通的SGD来做更新,学习率最好设置小一点。
和离线Batch training不同,Online learning会遇到一些特有的问题:
a. 实时streaming样本分布不均匀
现象:线上环境比较复杂,不同来源的日志qps和延迟都不同,造成不同时间段样本分布不一样,甚至在短时间段内样本分布异常。比如整体一天下来正负例1:9,如果某类日志延迟了,短时间可能全是负例,或者全是正例。 解决:Pairwise sampling。Pv日志到了后不立即产出负样本,而是等点击到了后找到关联的pv,然后把正负样本一起产出,这样的话就能保证正负样本总是1:9
b. 异步SGD更新造成模型不稳定
现象:权重学飘掉(非常大或者非常小),权重变化太大。解决:mini batch,一批样本梯度累加到一起,更新一次。




