参数量翻了10倍!Meta AI 祭出100亿参数的“新SEER”,为元宇宙铺路

来源:AI科技评论
本文约4268字,建议阅读8分钟
本文介绍了Meta AI 在自监督学习上的研究实践以及参数量翻了10倍的 SEER 模型的新花样。

不久前,Meta AI 宣称,其于去年3月提出的10亿参数自监督模型 SEER (SElf-supERvised)又取得了新突破:新的 SEER 参数量翻了10倍,达到了100亿参数,可以取得更优秀、更公平的性能表现!
以下我们暂且称新的 SEER 模型为“SEER 10B”。
根据 Meta AI 的团队介绍,他们将 SEER 10B 模型在50+个基准与多个不同未标记数据集上进行了测试。其中,SEER 10B 不仅在 ImageNet 上取得了高达 85.8% 的准确率(排名第一),与原先只有 10 亿参数量的 SEER (84.2%)相比性能提升了 1.6%。
此外,SEER 10B 在性别、肤色、年龄等三个公平基准上获得了更出色的识别效果,明显优于监督模型。

论文地址:https://arxiv.org/pdf/2202.08360.pdf
留意 Meta AI 的朋友不难发现:最近,Meta AI 首席科学家 Yann LeCun 与 Meta 创始人扎克伯格在公开发言中坚持强调自监督学习的优越性。上周,LeCun还提到自监督与世界模型,将 AI 最终能学会像人类一样学习与推理的希望寄托在这两个方法上。
所谓“自监督学习”,就是 AI 系统可以直接从文本、图像或其他类型的无标记数据中直接学习,主要针对解决监督学习所需的海量标记数据问题,因为在现实研究中,要获取大量的标记数据难度极高。
LeCun一直认为,自监督学习是构建具有背景知识或“常识”的机器、以解决远远超出当今 AI 任务的最有前景的方法之一。
但同时,也有读者评价 Meta 倡导的自监督本质上不过是强化学习。不久前,“怼王”Jürgen Schmidhuber 也发表文章,称“All You Need Is Supervised Learning”,重申监督学习在突破 AI 瓶颈中扮演的重要角色。
勿论其他,那么,Meta AI 在自监督学习上有哪些研究实践?参数量翻了10倍的 SEER 模型又有哪些新花样?一起来看看~
01. SEER 从 1B 到 10B
去年3月初,Meta AI(原 Facebook AI)发布了10亿参数自监督模型 SEER,曾在 AI 领域引起广泛关注。
据 Meta 介绍,这是他们在计算机视觉领域所取得的第一个基于自监督学习方法的成果:它可以直接从互联网的任一随机图像集合中学习,无需详细的数据管理和标记,随后直接输出图像嵌入。
经过一年的提升,如今 Meta 的研究团队将 SEER 的参数量扩大了10倍,在原有的基础上取得了更出色的性能表现:
除了可以在无标记数据上直接学习,SEER 还可以提取更高质量的视觉特征,以及发现现实世界大规模图像数据集中的显著信息,方式与人类分析所观察事物之间的关系的方式来了解世界般相似。
注意:这些数据集的覆盖范围是全球数万亿张随机、未经处理的图像。
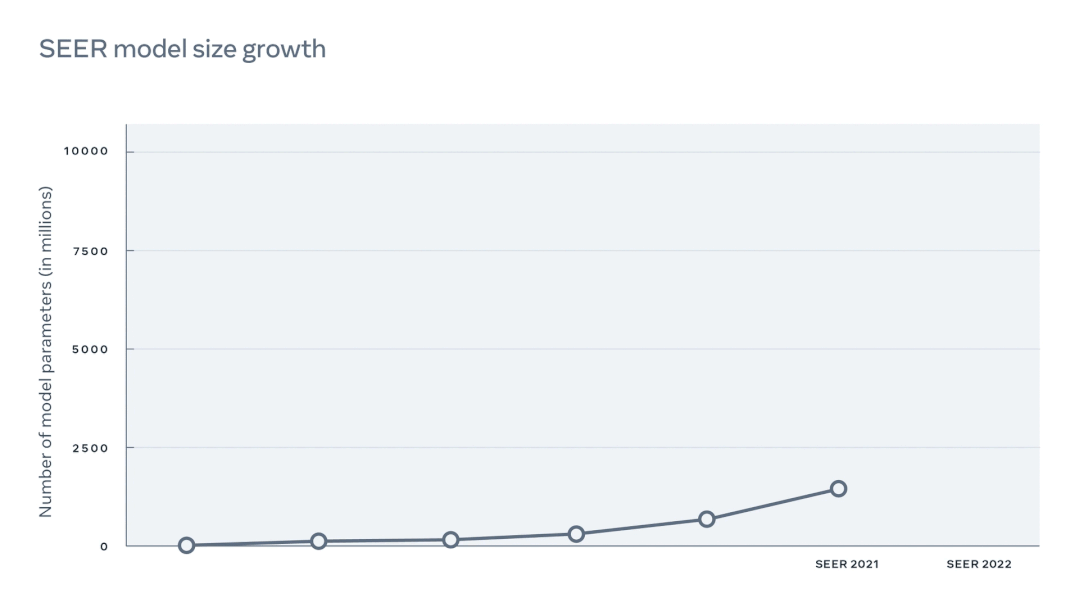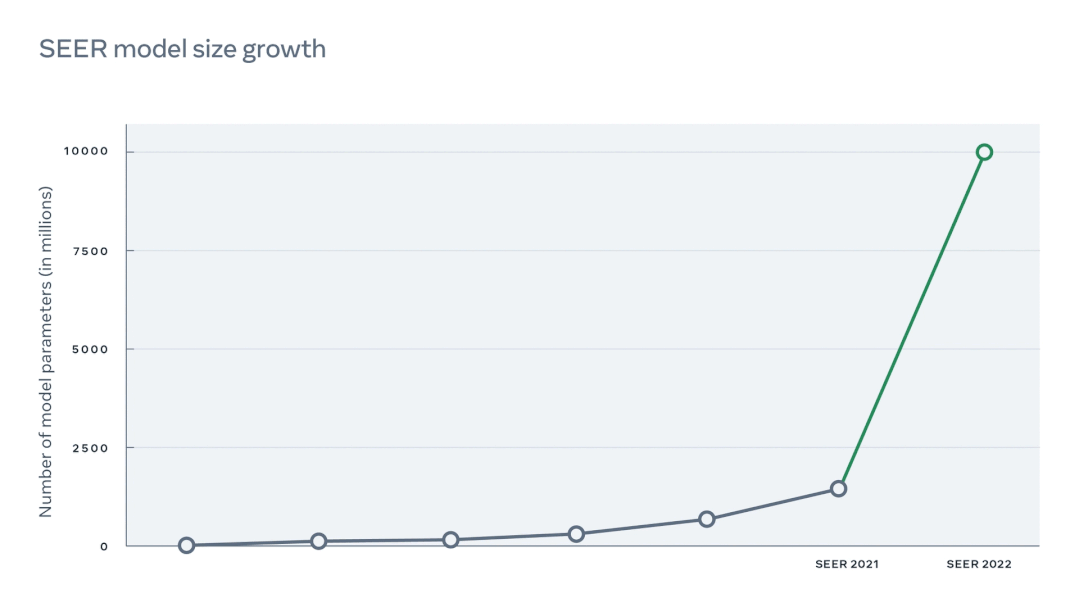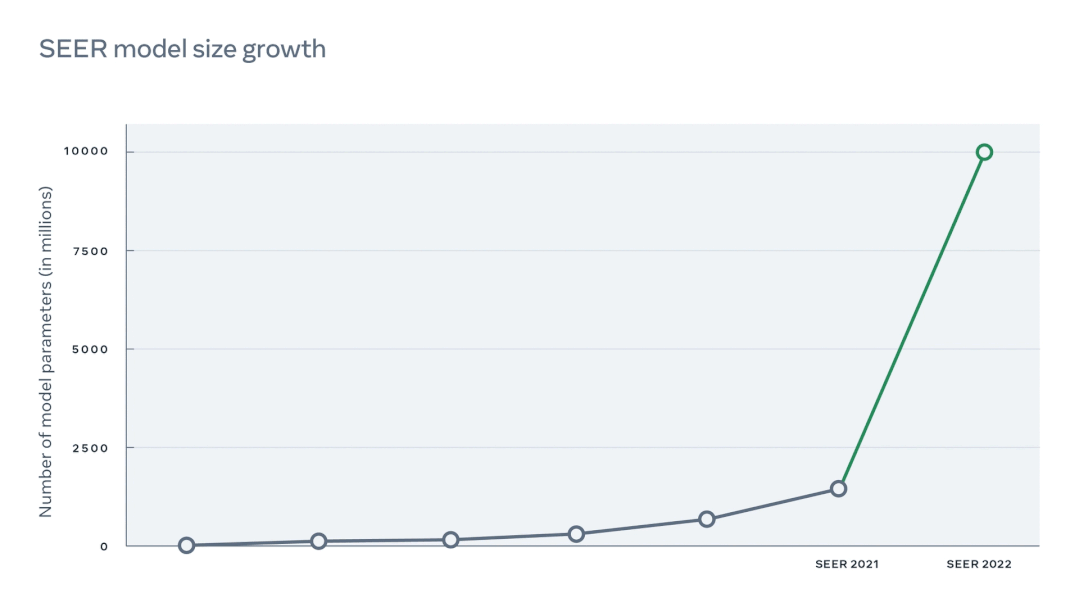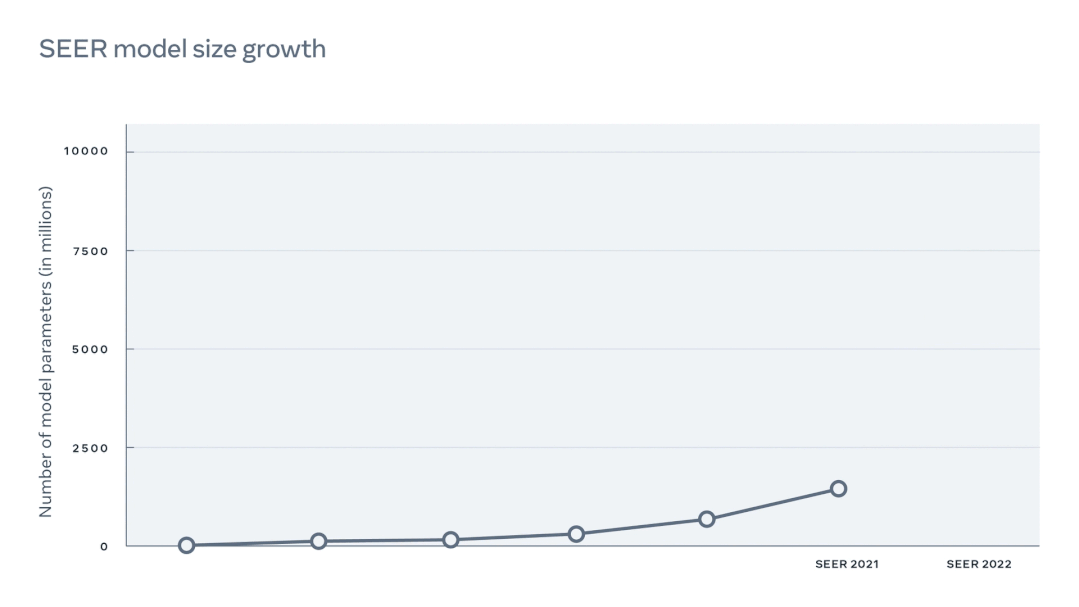
据悉,扩大了10倍密集参数后的 SEER 是当前规模最大的密集计算机视觉模型。
他们在 50 多个基准上检验了 SEER 模型的性能,包括公平性、鲁棒性、细粒度识别,还在医学成像、卫星图像和光学字符识别 (OCR) 等领域的多个图像分类数据集上进行了实验。
不难想象,参数量翻倍后的 SEER 10B模型在一些挑战性较高的任务上也取得了更优秀的表现。
首先,100亿 SEER 在 ImageNet 上获得了高达 85.8% 的准确率,排名第一!

除了在标准计算机视觉基准上的优秀表现外,SEER还擅长处理高难度任务,并提高了对域外泛化的鲁棒性。
例如,它可以正确识别素描图和艺术画中的动物,还可以搞定常见的图像问题,例如掩装、模糊、遮挡、运动和怪异视角拍摄等。
SEER 10B 模型还能够捕获大量随机的、未经过滤的互联网图像中存在的显着信息,甚至跨越不同的地理和语言概念。
例如,即使该模型仅在没有位置信息或其他元数据的图像上进行训练,它也能够将全球多种语言的相同概念组合在一起。例如,将来自世界各地的“婚礼”概念嵌入到模型的特征空间中。
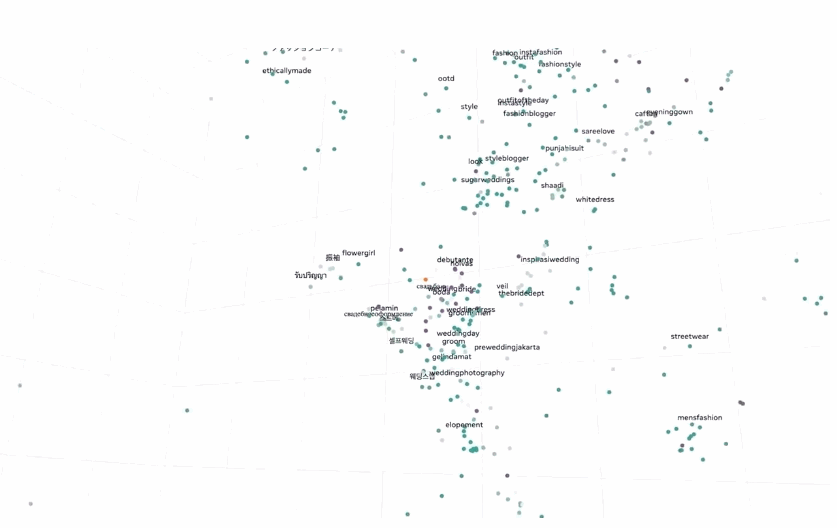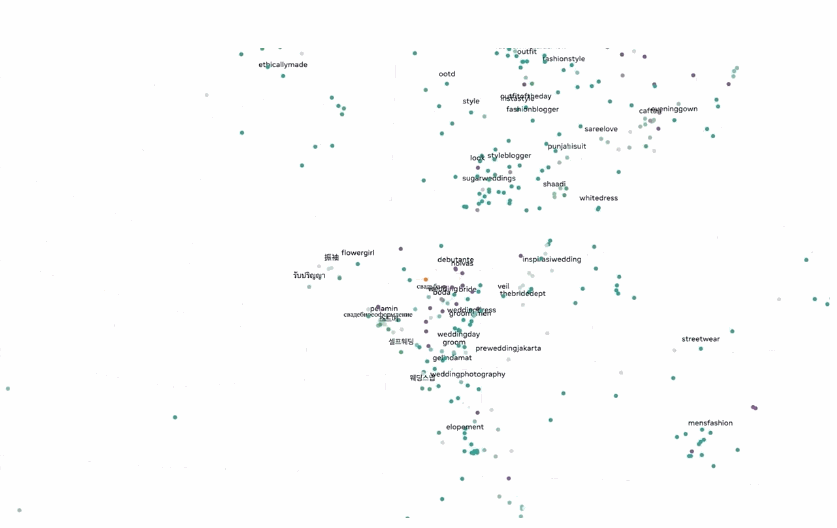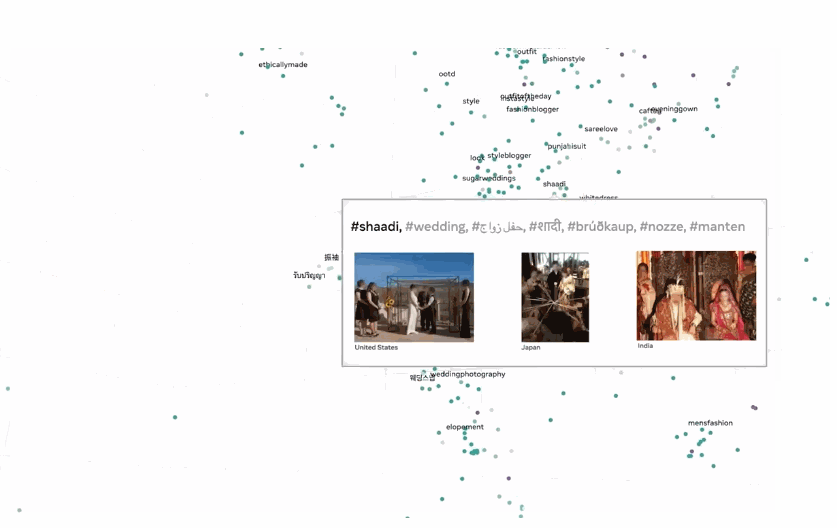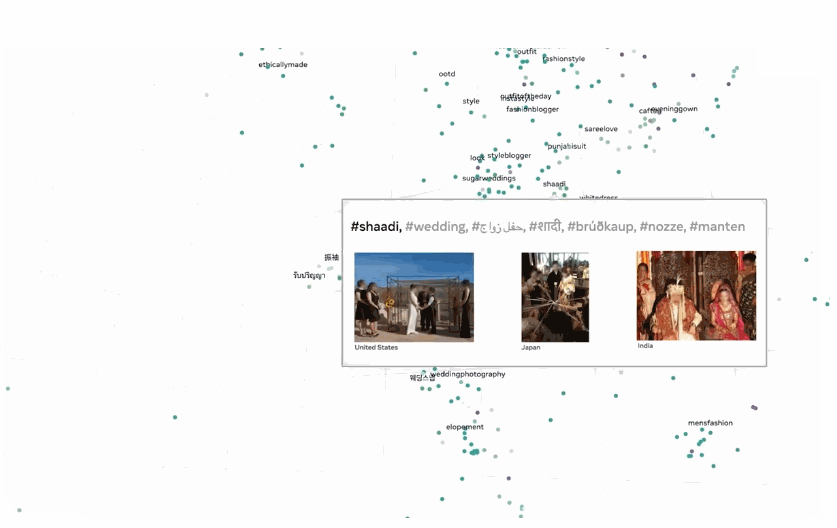
除了性能的突破,Meta AI 还称:SEER 10B 模型能取得更公平的效果。
他们使用 Meta 新开源的 Casual Conversations 数据集以及他们最近为CV模型提出的新公平基准对 SEER 进行测试,发现与较小的 SEER 模型以及 ImageNet 训练的监督和自监督模型相比,SEER 10B 模型能更准确地识别这些社会成员属性,适用于不同性别、肤色和年龄的人。
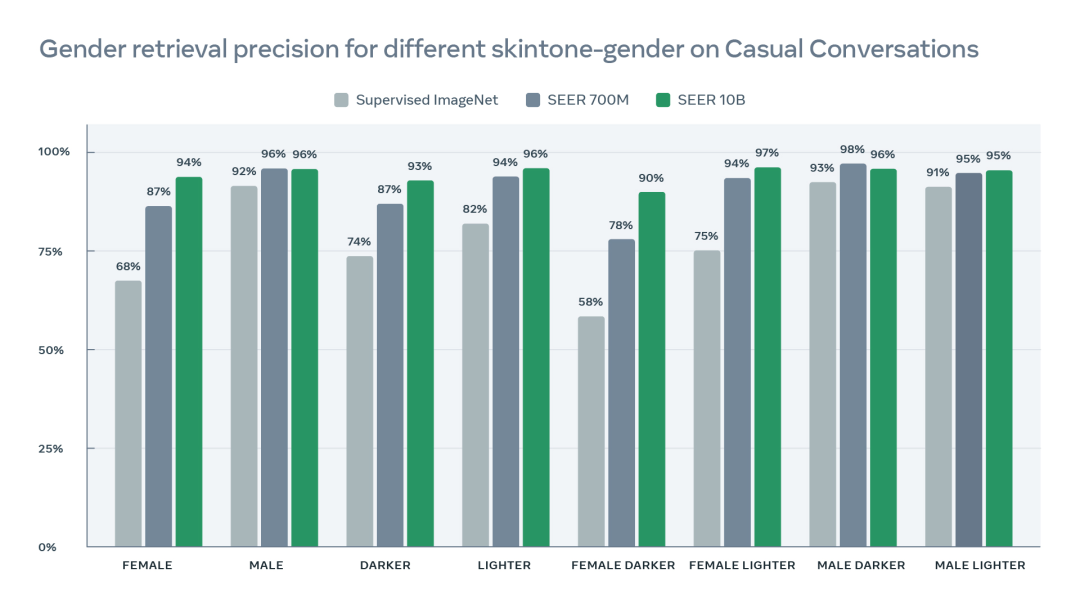
图注:该图使用 Casual Conversations 数据集显示了性别检索的准确性
此外,他们使用 Casual Conversations 数据集评估了模型标签的错误率,例如在给定特定的人像中预测“非人类”或“犯罪”等标签。研究表明,SEER 10B 问题不大,但在 ImageNet 上训练的监督模型却产生了大量的错误关联。
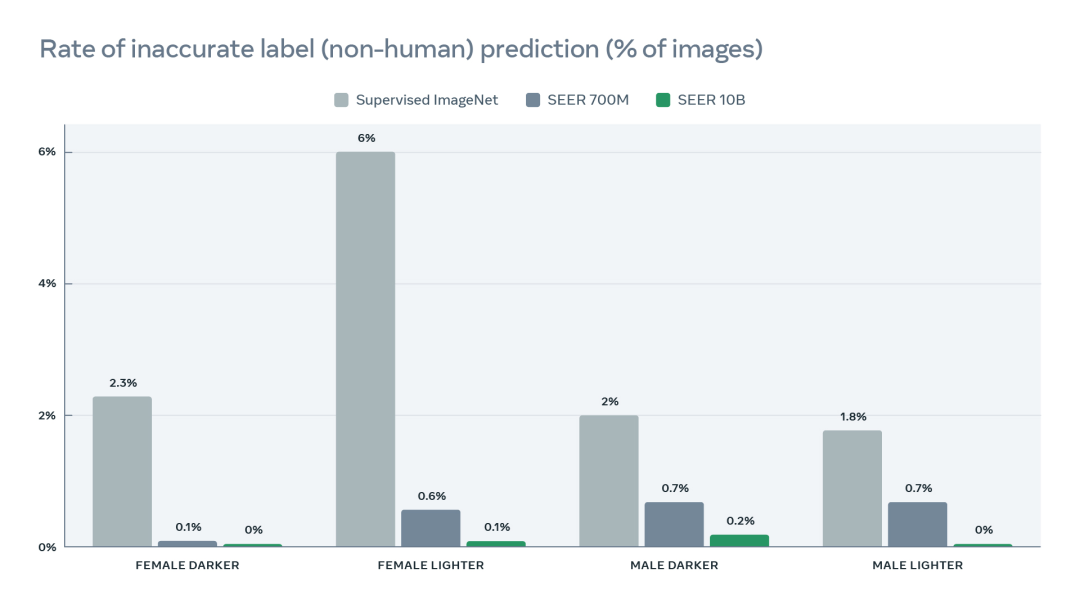
图注:该图显示了 SEER 模型对不同人群的关联预测错误率
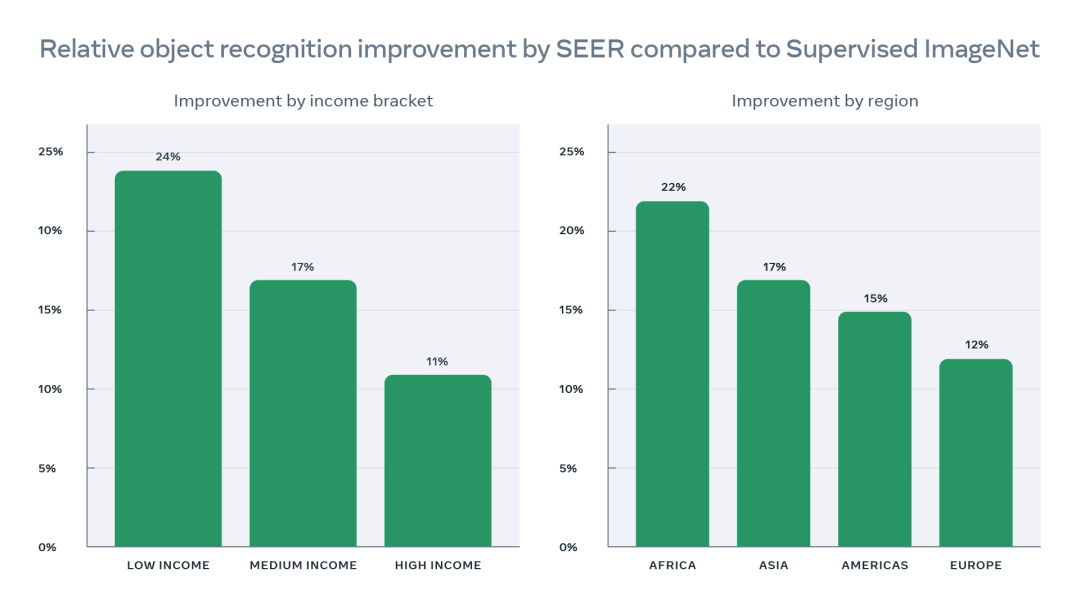
SEER 10B模型还不仅适用于欧美国家的图像示例,还适用于全球各地收入水平中下的地区,以前所未有的精度对图像进行地理定位。
通过在 Gapminder 的 Dollar Street 数据集(该数据集收集了世界各地家庭中的物体图像及家庭收入信息)上实验,他们还发现,SEER 10B模型对识别全球中低收入家庭与非西方地区家庭的性能有了大幅提升,且明显优于10亿参数的 SEER 与其他监督方法。
图注:在 Meta AI 于 2020 年创建的数据集 Hateful Memes 上检测多模态(图像 + 文本)仇恨言论时,SEER 10B 的表现也优于受监督的 ImageNet 训练模型 2 个百分点。
02. 对抗性攻击
Meta AI 的研究团队表示,秉着“负责任地开发 AI 系统”的原则,他们还对 SEER 10B模型进行了对抗性攻击,以保护训练数据的隐私安全。
他们在 Meta 的开源工具 Privacy Linter 上进行了测试,发现攻击的准确度(50.02%)仅略高于完全随机猜测,而随机攻击的准确度对于相同大小的训练集,准确度为 50%。
此外,他们计算了不同召回级别的精度,以确保没有训练图像在低召回级别中暴露——这种情况可能发生在所有得分最高的样本都属于训练集时;同时,精度低于 50.15% 适用于所有级别的召回(包括最低级别)。
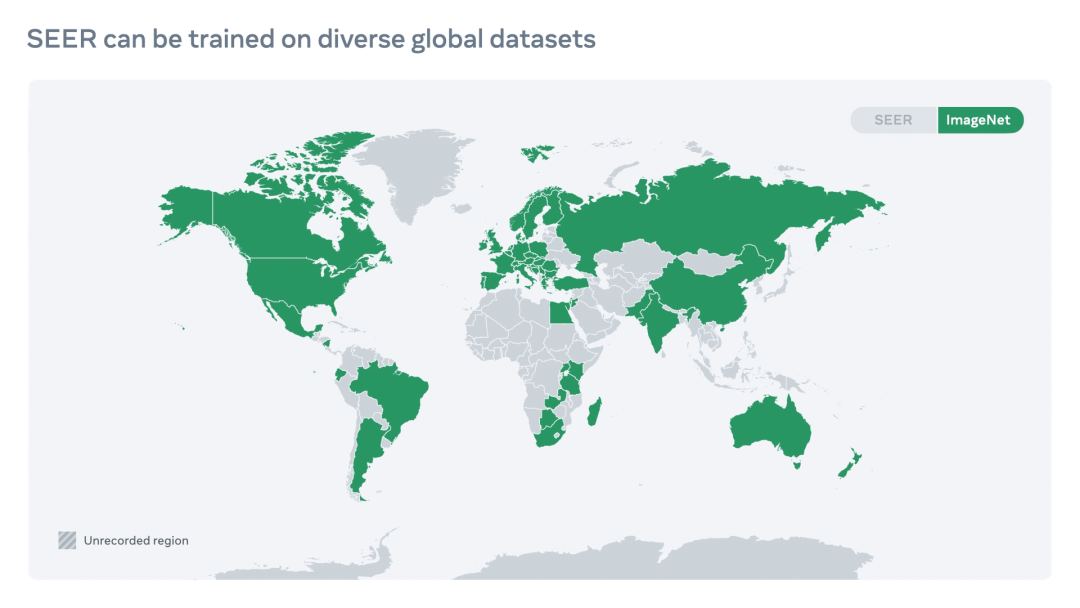
图注:由于 SEER 不依赖于标记数据集,所以它能够在一组比 ImageNet 的地理多样性更优的示例上训练模型
为了测试模型在对抗性攻击中的鲁棒性,他们将模型用于识别模糊、插入、已被裁剪或经过其他编辑的扭曲图像。其中,SEER 10B在 CopyDays 基准测试中实现了 90.6% 的平均精度,提高了 5.1%,超越了之前的最佳结果。
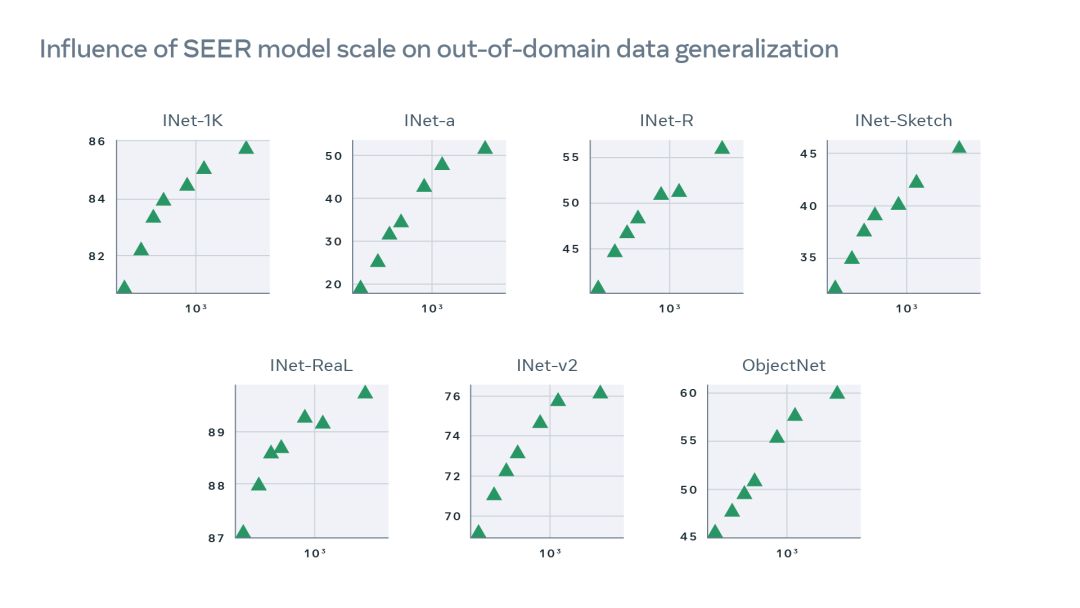
此外,SEER 在域外鲁棒性基准上优于在 ImageNet 上训练的最先进的自监督模型,并且随着规模的增大,鲁棒性也不断提高。
目前,SEER 10B 的模型权重、实现细节与技术文档都已开放:

项目地址:https://github.com/facebookresearch/vissl/blob/main/projects/SEER/README.md#pretrained-models-weights
03. 自监督学习与元宇宙
自监督学习是 Meta AI 首席科学家 Yann LeCun 近年来一直力推的研究方向。早在2018年Lecun就表示,人工智能的下一个发展方向可能是放弃深度学习的所有概率技巧,转而掌握一系列转移能量值的方法。与“常规”的深度学习标记训练方法相比,这一方式无需创建大量带标签的数据集,其基本设想是通过获取一些丰富的原始数据(如大量Facebook Live视频或Instagram照片)并“喂”给机器进行训练,训练的目标是达到能量值越小越好(即预测更为准确,与现实之间实现更好的兼容性)。

Lecun 2018年在UCSB做的“Self-Supervised Learning”演讲Slide
基于能量的学习早就有之。在AI研究中,“能量函数”是一个上世纪80年代一度流行的“上古”概念,由美国生物物理学家霍普菲尔德(John Hopfield)发明的“霍普菲尔德神经网络”(HNN)引入并普及。Lecun认为,监督学习无法获得像人类一样可以泛化的智能,当 AI 系统不再需要监督学习时,下一次 AI 革命就会到来,而基于能量的学习正是“减少监督”的有效实现方式。
Lecun的这一思路,在他上周接受 IEEE Spectrum 的访谈中也可见一斑。他认为AI想要突破现在的瓶颈,必须让机器学习世界模型,从而能够填补缺失的信息,预测将要发生的事情,并预测行动的影响。这种学习范式与预测架构的不同,或许也是不久前Lecun对OpenAI创始人Ilya Sutskever提出的“大型神经网络可能有意识”坚决说不的原因。
在Lecun的力推下,META围绕自监督模型取得了一系列的研究成果(例如最近推出的多模态自监督学习新架构deta2vec等)。这种通过自监督学习“观察世界并学习”、最终实现像人类一样泛化的智能的学习方式,一方面可以最大程度利用META丰富的数据资源,同时也是META抢先打造元宇宙世界、加速数字世界与现实世界融合的重要技术手段。
Meta AI Research 团队也表示,计算机视觉的发展是构建元宇宙的重要步骤,而自监督视觉模型 SEER 的增强无疑为元宇宙的更上一层楼作了铺垫。
举例来说,如果要打造一幅能够帮你导航寻找钥匙或教你如何做饭的 AR 眼镜,那么就需要机器能够像人类一样理解视觉世界。这些机器不单单要能在堪萨斯州和日本京都的厨房中工作,还要在吉隆坡、北京、纽约等等世界各地的厨房中工作,这就需要机器能识别常见物体的多种模样。而 SEER 10B 在多种不同数据集中的强大性能为实现突破提供了可能。
参考链接:



