如何对非结构化文本数据进行特征工程操作?这里有妙招!

本文是英特尔数据科学家 Dipanjan Sarkar 在 Medium 上发布的「特征工程」博客续篇。在本系列的前两部分中,作者介绍了 连续数据的处理方法 和 离散数据的处理方法 。本文则开始了一个新的主题,非结构化文本数据的传统处理方法。 AI 研习社对原文(http://mrw.so/3OjXRn )进行了编译。
文本数据通常是由表示单词、句子,或者段落的文本流组成。由于文本数据非结构化(并不是整齐的格式化的数据表格)的特征和充满噪声的本质,很难直接将机器学习方法应用在原始文本数据中。在本文中,我们将通过实践的方法,探索从文本数据提取出有意义的特征的一些普遍且有效的策略,提取出的特征极易用来构建机器学习或深度学习模型。
研究动机
想要构建性能优良的机器学习模型,特征工程必不可少。有时候,可能只需要一个优秀的特征,你就能赢得 Kaggle 挑战赛的胜利!对于非结构化的文本数据来说,特征工程更加重要,因为我们需要将文本流转化为机器学习算法能理解的数字表示。即使现在有高级的自动化特征工程,在把它们当作「黑盒子」应用之前,我们仍有必要去了解不同特征工程策略背后的核心思想。永远记住,「如果有人给了你一套修房子的工具,你应该知道什么时候该用电钻,什么时候该用锤子!」
理解文本数据
我们虽然能够获得具有结构数据属性的文本数据,但它们为结构化数据,并不在今天的讨论范围之内。
在本文中,我们讨论以单词、短语、句子和整个文档的形式展现的文本流。从本质上讲,文本确实有一些句法结构,比如单词组成了短语,短语组成了句子,句子又组合成了段落。然而,与结构化数据集中固定的数据维度相比,文本文档没有固定的结构,因为单词有众多的选择,每个句子的长度也是可变的。本文就是一个很典型的案例。
特征工程的策略
下面是一些流行且有效的处理文本数据的策略,这些方法也能应用在下游的机器学习系统中,用于提取有用的特征。大家可以在 GitHub(http://mrw.so/1Kyr6M ) 中查看本文使用的所有代码。
首先加载一些基本的依赖关系和设置:
import pandas as pd
import numpy as np
import re
import nltk
import matplotlib.pyplot as pltpd.options.display.max_colwidth = 200
%matplotlib inline
下面是文档中的语料库,本文大部分内容都是基于该数据集的分析。语料库(http://mrw.so/3l3BUu )通常是属于一个或多个主题的文档的集合。
corpus = ['The sky is blue and beautiful.',
'Love this blue and beautiful sky!',
'The quick brown fox jumps over the lazy dog.',
"A king's breakfast has sausages, ham, bacon, eggs, toast and beans",
'I love green eggs, ham, sausages and bacon!',
'The brown fox is quick and the blue dog is lazy!',
'The sky is very blue and the sky is very beautiful today',
'The dog is lazy but the brown fox is quick!'
]
labels = ['weather', 'weather', 'animals', 'food', 'food', 'animals', 'weather', 'animals']
corpus = np.array(corpus)
corpus_df = pd.DataFrame({'Document': corpus,
'Category': labels})
corpus_df = corpus_df[['Document', 'Category']]
corpus_df
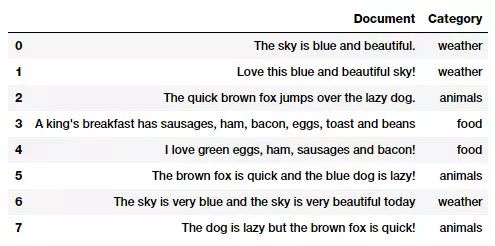
本文中应用的语料库案例
可以看到,我们已经从语料库中提取出几个不同类别的文档。在讨论特征工程之前,一如往常,首先得做数据预处理,删除一些不必要的字符、符号和标记。
文本预处理
有很多种对文本数据进行清洗和预处理的方法。下面我将重点介绍在自然语言处理(NLP)流程中大量使用的方法。
删除标签:文本中通常会包含一些不必要的内容,比如 HTML 标签,这在分析文本时并没有太多价值。BeautifulSoup 库提供了清理标签的函数。
清理重音字符:在许多文本语料库中,特别是在处理英文时,通常会遇到重音字符 / 字母。因此我们要确保将这些字符转换为标准的 ASCII 字符。一个简单的例子就是将 é 转换成 e。
拓展缩写:在英文中,缩写基本上是单词或者音节的缩减版。缩减版通常是删除某些单词或者短语中特定的字母和声音而来。举例来说,do not 和 don't , I would 和 I'd。将缩写单词转换为完整的原始形式有助于文本的标准化。
删除特殊字符:特殊字符和非字母数字的符号通常会增加额外噪声。通常,可以通过简单的正则表达式来实现这一点。
词干提取和词性还原:可以利用词干创造新的词汇,例如通过附加前缀和后缀等词缀来创造新的单词。这被称为词性变化。词干提取是将这个过程反过来。一个简单的例子是单词:WATCHES, WATCHING, 和 WATCHED,这些单词都把 WATCH 作为词根。词性还原与词干提取很相似,通过移除词缀以得到单词的基本形式。然而在词性还原里,单词的基本形式是词根(root word),而不是词干(root stem)。其不同之处在于词根(root word)总是字典上正确的词(即出现在词典中),但词干并不是这样。
去除无用词:在从文本中构建有意义的特征时,没有意义的词被称为无用词。如果你在一个语料库中做一个简单的词频分析,这些无用词通常会以最大的频率出现。像 a , an 这样的词被认为是无用词。但是实际上并没有明确通用的无用词表,我们通常使用 nltk 的标准英语无用词表。大家也可以根据特定的需要添加无用词。

除此之外,还可以使用其他的标准操作,比如标记化、删除多余的空格、文本大写转换为小写,以及其他更高级的操作,例如拼写更正、语法错误更正、删除重复字符等。
由于本文的重点是特征工程,我们将构建一个简单的文本预处理程序,其重点是删除特殊字符、多余的空格、数字、无用词以及语料库的大写转小写。
wpt = nltk.WordPunctTokenizer()
stop_words = nltk.corpus.stopwords.words('english')
def normalize_document(doc):
# lower case and remove special characters\whitespaces
doc = re.sub(r'[^a-zA-Z\s]', '', doc, re.I|re.A)
doc = doc.lower()
doc = doc.strip()
# tokenize document
tokens = wpt.tokenize(doc)
# filter stopwords out of document
filtered_tokens = [token for token in tokens if token not in stop_words]
# re-create document from filtered tokens
doc = ' '.join(filtered_tokens)
return doc
normalize_corpus = np.vectorize(normalize_document)
一旦搭建好基础的预处理流程,我们就可以将它应用在语料库中了。
norm_corpus = normalize_corpus(corpus)
norm_corpusOutput
------
array(['sky blue beautiful', 'love blue beautiful sky',
'quick brown fox jumps lazy dog',
'kings breakfast sausages ham bacon eggs toast beans',
'love green eggs ham sausages bacon',
'brown fox quick blue dog lazy',
'sky blue sky beautiful today',
'dog lazy brown fox quick'],
dtype='<U51')
上面的输出结果应该能让大家清楚的了解样本文档在预处理之后的样子。现在我们来开始特征工程吧!
词袋模型(Bag of Word)
这也许是非结构化文本中最简单的向量空间表示模型。向量空间是表示非结构化文本(或其他任何数据)的一种简单数学模型,向量的每个维度都是特定的特征 / 属性。词袋模型将每个文本文档表示为数值向量,其中维度是来自语料库的一个特定的词,而该维度的值可以用来表示这个词在文档中的出现频率、是否出现(由 0 和 1 表示),或者加权值。将这个模型叫做词袋模型,是因为每个文档可以看作是装着单词的袋子,而无须考虑单词的顺序和语法。
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(min_df=0., max_df=1.)
cv_matrix = cv.fit_transform(norm_corpus)
cv_matrix = cv_matrix.toarray()
cv_matrix

可以看到,文档已经被转换为数字向量,这样每个文档都由上述特征矩阵中的一个向量(行)表示。下面的代码有助于以一种更易理解的格式来表示这一点。
# get all unique words in the corpus
vocab = cv.get_feature_names()
# show document feature vectors
pd.DataFrame(cv_matrix, columns=vocab)
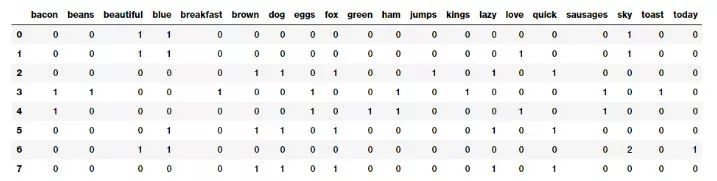
词袋模型的文档特征向量
上面的表格应该更能助于理解!可以清楚地看到,特征向量中每个列(维度)都代表一个来自语料库的单词,每一行代表一个文档。单元格中的值表示单词(由列表示)出现在特定文档(由行表示)中的次数。因此,如果一个文档语料库是由 N 个单词组成,那么这个文档可以由一个 N 维向量表示。
N 元词袋模型(Bag of N-Gram Model)
一个单词只是一个标记,通常被称为单元(unigram)或者一元(1-gram)。我们已经知道,词袋模型不考虑单词的顺序。但是如果我们也想要考虑序列中出现的短语或者词汇集合呢?N 元模型能够帮我们实现这一点。N-Gram 是来自文本文档的单词记号的集合,这些记号是连续的,并以序列的形式出现。二元表示阶数为二的 N-Gram,也就是两个单词。同理三元表示三个单词。N 元词袋模型是普通词袋模型的一种拓展,使得我们可以利用基于 N 元的特征。下面的示例展示了文档中二元的特征向量。
# you can set the n-gram range to 1,2 to get unigrams as well as bigrams
bv = CountVectorizer(ngram_range=(2,2))
bv_matrix = bv.fit_transform(norm_corpus)
bv_matrix = bv_matrix.toarray()
vocab = bv.get_feature_names()
pd.DataFrame(bv_matrix, columns=vocab)
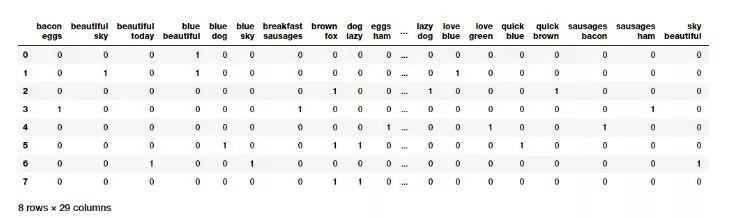
使用二元词袋模型的特征向量
在上面的例子中,每个二元特征由两个单词组成,其中的值表示这个二元词组在文档中出现的次数。
TF-IDF 模型
在大型语料库中使用词袋模型可能会出现一些潜在的问题。由于特征向量是基于词的频率,某些单词可能会在文档中频繁出现,这可能会在特征集上掩盖掉其他单词。TF-IDF 模型试图通过缩放或者在计算中使用归一化因子来解决这个问题。TF-IDF 即 Term Frequency-Inverse Document Frequency,在计算中结合了两种度量:词频(Term Frequency)和逆文档频率(Inverse Document Frequency)。这种技术是为搜索引擎中查询排序而开发的,现在它是信息检索和 NLP 领域中不可或缺的模型。
在数学上,TF-IDF 可以定义为:tfidf = tf x idf,也可以进一步拓展为下面的表示:
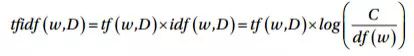
在这里,tfidf(w, D)表示单词 w 在文档 D 中的 TF-IDF 分数。Tf(w,D)项表示单词 w 在文档 D 中的词频,这个值可以从词袋模型中获得。idf(w,D)项是单词 w 的逆文档频率,可以由语料库中所有文档的总数量 C 除以单词 w 的文档频率 df(w)的 log 值得到,其中文档频率是指语料库中文档出现单词 w 的频率。这种模型有多种变种,但是给出的最终结果都很相似。下面在语料库中使用这个模型吧!
from sklearn.feature_extraction.text import TfidfVectorizer
tv = TfidfVectorizer(min_df=0., max_df=1., use_idf=True)
tv_matrix = tv.fit_transform(norm_corpus)
tv_matrix = tv_matrix.toarray()
vocab = tv.get_feature_names()
pd.DataFrame(np.round(tv_matrix, 2), columns=vocab)
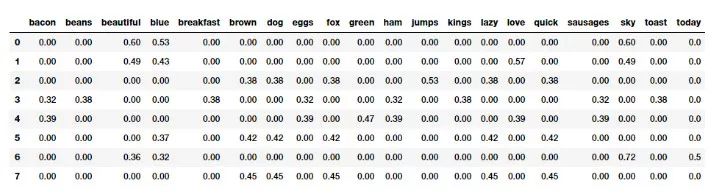
基于 TF-IDF 模型的文档特征向量
基于 TF-IDF 的特征向量与原始的词袋模型相比,展示出了缩放和归一化的特性。想要进一步深入了解该模型的读者可以参考 Text Analytics with Python(http://mrw.so/2bZDIe ) 的 181 页。
文档相似性
文档相似性是使用从词袋模型或者 tf-idf 模型中提取出的特征,基于距离或者相似度度量判断两个文档相似程度的过程。
因此,可以使用在上一部分中提到的 tf-idf 模型提取出的特征,用其来生成新的特征。这些特征在搜索引擎、文档聚类以及信息检索等领域发挥着重要作用。

语料库中的配对文档相似性需要计算语料库中每两个文档对的文档相似性。因此,如果一个语料库中有 C 个文档,那么最终会得到一个 C*C 的矩阵,矩阵中每个值代表了该行和该列的文档对的相似度分数。可以用几种相似度和距离度量计算文档相似度。其中包括余弦距离 / 相似度、欧式距离、曼哈顿距离、BM25 相似度、jaccard 距离等。在我们的分析中,我们将使用最流行和最广泛使用的相似度度量:余弦相似度,并根据 TF-IDF 特征向量比较文档对的相似度。
from sklearn.metrics.pairwise import cosine_similarity
similarity_matrix = cosine_similarity(tv_matrix)
similarity_df = pd.DataFrame(similarity_matrix)
similarity_df
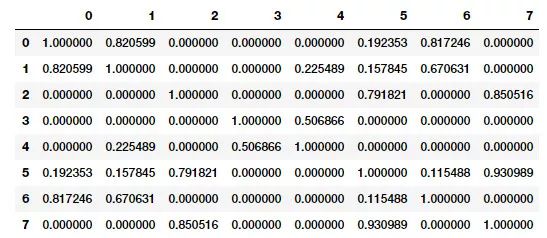
文档对的相似性矩阵 (余弦相似度)
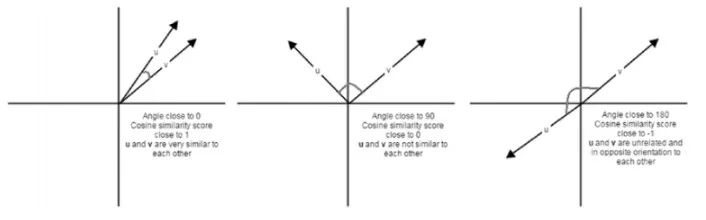
余弦相似度给出了表示两个文档特征向量之间角度的余弦值的度量。两个文档特征向量之间的角度越低,两个文档的相似度就越高,如下图所示:
仔细观察相似度矩阵可以清楚地看出,文档(0,1 和 6),(2,5 和 7)之间非常相似,文档 3 和 4 略微相似。这表明了这些相似的文档一定具有一些相似特征。这是分组或聚类的一个很好的案例,可以通过无监督的学习方法来解决,特别是当需要处理数百万文本文档的庞大语料库时。
具有相似特征的文档聚类
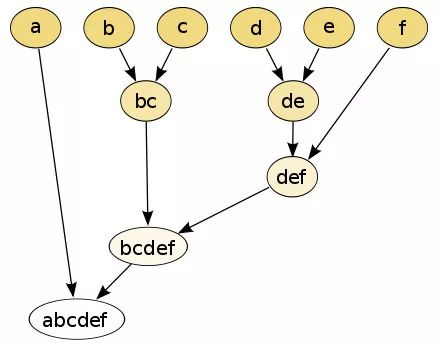
聚类是利用无监督学习的方法,将数据点 (本场景中即文档) 分类到组或者 cluster 中。我们将在这里利用一个无监督的层次聚类算法,通过利用我们之前生成的文档相似性特征,将我们的玩具语料库中的类似文档聚合到一起。有两种类型的层次聚类方法,分别是凝聚方法(agglomerative)和分裂方法(divisive)。这里将会使用凝聚聚类算法,这是一种自下而上(bottom up)的层次聚类算法,最开始每个文档的单词都在自己的类中,根据测量数据点之间的距离度量和连接准则(linkage criterion),将相似的类连续地合并在一起。下图展示了一个简单的描述。
连接准则决定了合并策略。常用的连接准则有 Ward, Complete linkage, Average linkage 等等。这些标准在将一对 cluster 合并在一起(文档中低层次的类聚类成高层次的)时是非常有用的,这是通过最优化目标函数实现的。我们选择 Ward 最小方差作为连接准则,以最小化总的内部聚类方差。由于已经有了相似特征,我们可以直接在样本文档上构建连接矩阵。
from scipy.cluster.hierarchy import dendrogram, linkage
Z = linkage(similarity_matrix, 'ward')
pd.DataFrame(Z, columns=['Document\Cluster 1', 'Document\Cluster 2',
'Distance', 'Cluster Size'], dtype='object')
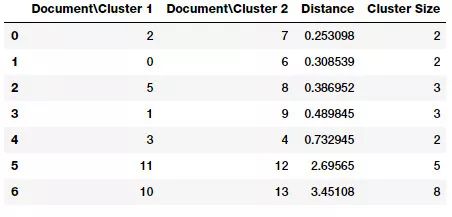
我们语料库的连接矩阵
如果仔细查看连接矩阵,可以看到连接矩阵的每个步骤(行)都告诉了我们哪些数据点(或者 cluster)被合并在一起。如果有 n 个数据点,那么连接矩阵 Z 将是(n-1)*4 的形状,其中 Z[i] 表示在步骤 i 合并了哪些 cluster。每行有四个元素,前两个元素是数据点或 cluster 的名称,第三个元素是前两个元素(数据点或 cluster)之间的距离,最后一个元素是合并完成后 cluster 中元素 / 数据点的总数。大家可以参考 scipy 文档(http://mrw.so/2wJn1V ),其中有详细解释。
下面,把这个矩阵看作一个树状图,以更好地理解元素!
plt.figure(figsize=(8, 3))
plt.title('Hierarchical Clustering Dendrogram')
plt.xlabel('Data point')
plt.ylabel('Distance')
dendrogram(Z)
plt.axhline(y=1.0, c='k', ls='--', lw=0.5)
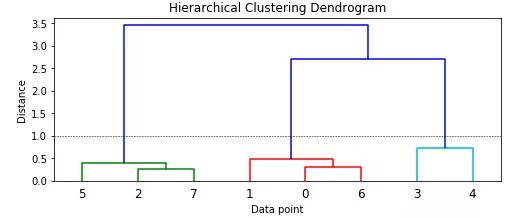
可以看到每个数据点是如何从一个单独的簇开始,慢慢与其他数据点合并形成集群的。从颜色和树状图的更高层次来看,如果考虑距离度量为 1.0(由虚线表示)或者更小,可以看出模型已经正确识别了三个主要的聚类。利用这个距离,我们可以得到集群的标签。
from scipy.cluster.hierarchy import fcluster
max_dist = 1.0
cluster_labels = fcluster(Z, max_dist, criterion='distance')
cluster_labels = pd.DataFrame(cluster_labels, columns=['ClusterLabel'])
pd.concat([corpus_df, cluster_labels], axis=1)

可以清楚地看到,我们的算法已经根据分配给它们的标签,正确识别了文档中的三个不同类别。这应该能够给大家一个关于如何使用 TF-IDF 特征来建立相似度特征的思路。大家可以用这种处理流程来进行聚类。
主题模型
也可以使用一些摘要技术从文本文档中提取主题或者基于概念的特征。主题模型围绕提取关键主题或者概念。每个主题可以表示为文档语料库中的一个词袋或者一组词。总之,这些术语表示特定的话题、主题或概念,凭借这些单词所表达的语义含义,可以轻松将每个主题与其他主题区分开来。这些概念可以从简单的事实、陈述到意见、前景。主题模型在总结大量文本来提取和描绘关键概念时非常有用。它们也可用于从文本数据中捕捉潜在的特征。
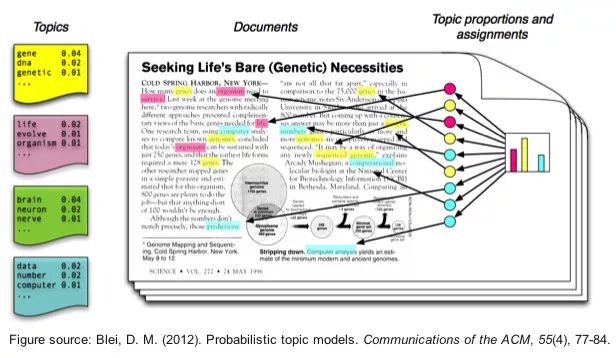
主题建模有很多种方法,其中大多涉及到某种形式的矩阵分解。比如隐含语义索引(Latent Semantic Indexing, LSI)就使用了奇异值分解。这里将使用另一种技术:隐含狄利克雷分布(Latent Dirichlet Allocation, LDA),它使用了生成概率模型,其中每个文档由几个主题组合而成,每个术语或单词可以分配给某个主题。这与基于 pLSI(probabilistic LSI)的模型很类似。在 LDA 的情况下,每个隐含主题都包含一个狄利克雷先验。
这项技术背后的数学原理相当复杂,所以我会试着总结一下,而不是罗列很多让人厌倦的细节。我建议读者可以看看 Christine Doig 的一个优秀的演讲(http://mrw.so/4vDtQL ),深入了解一下。
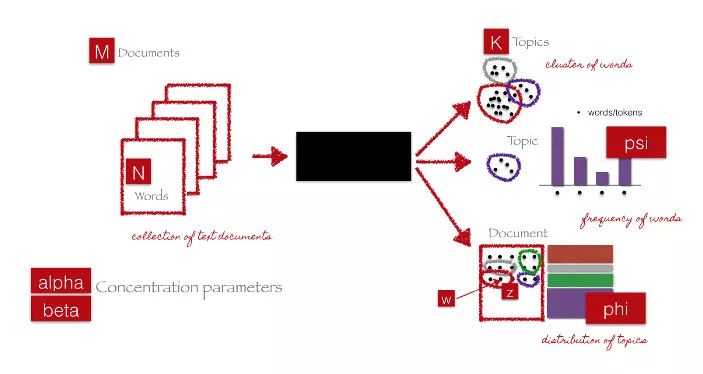
上图中的黑色框表示利用前面提到的参数,从 M 个文档中提取 K 个主题的核心算法。下面的步骤是对算法的解释。
初始化必要的参数。
随机初始化文档,将每个单词分配到 K 个主题中去。
按照如下方法迭代
对于每个文档 D:
a) 对于文档中的单词 W:
i. 对于主题 T:
计算 P(T|D), 表示文档 D 中单词分配给 T 主题的比例。
计算 P(W|T),表示在所有文档中,主题 T 包含单词 W 的比例。
ii. 通过计算概率 P(T|D)*P(W|T) 重新分配单词 W 的主题 T。
运行几个迭代之后,就能获得混合了每个文档的主题,然后就可以根据指向某个主题的单词生成文档的主题。像 gensim 或者 scikit-learn 这样的框架,使得我们能够利用 LDA 模型来生成主题。
大家应该记住,当 LDA 应用于文档 - 单词矩阵(TF-IDF 或者词袋特征矩阵)时,它会被分解为两个主要部分:
文档 - 主题矩阵,也就是我们要找的特征矩阵
主题 - 单词矩阵,能够帮助我们查看语料库中潜在的主题
使用 scikit-learn 可以得到如下的文档 - 主题矩阵。
from sklearn.decomposition import LatentDirichletAllocation
lda = LatentDirichletAllocation(n_topics=3, max_iter=10000, random_state=0)
dt_matrix = lda.fit_transform(cv_matrix)
features = pd.DataFrame(dt_matrix, columns=['T1', 'T2', 'T3'])
features
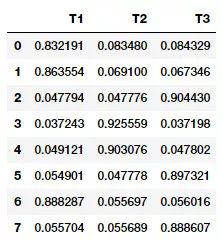
可以清楚地看到哪些文档对上述输出中的三个主题贡献最大,可以通过如下的方式查看主题及其组成部分。
tt_matrix = lda.components_
for topic_weights in tt_matrix:
topic = [(token, weight) for token, weight in zip(vocab, topic_weights)]
topic = sorted(topic, key=lambda x: -x[1])
topic = [item for item in topic if item[1] > 0.6]
print(topic)
print()

可以看到,由于组成术语不同,很容易区分这三个主题。第一个在讨论天气,第二个关于食物,最后一个关于动物。主题建模的主题数量选择是一门完整的课题,既是一门艺术,也是一门科学。获得最优主题数量的方法有很多,这些技术既复杂又繁琐,这里就不展开讨论了。
使用主题模型特征的文档聚类
这里使用 LDA 法从词袋模型特征构建主题模型特征。现在,我们可以利用获得的文档单词矩阵,使用无监督的聚类算法,对文档进行聚类,这与我们之前使用的相似度特征进行聚类类似。
这次我们使用非常流行的基于分区的聚类方法——K-means 聚类,根据文档主题模型特征表示,进行聚类或分组。在 K-means 聚类法中,有一个输入参数 K,它制定了使用文档特征输出的聚类数量。这种聚类方法是一种基于中心的聚类方法,试图将这些文档聚类为等方差的类。这种方法通过最小化类内平方和来创建聚类。选择出最优的 K 的方法有很多,比如误差平方和度量,轮廓系数(Silhouette Coefficients)和 Elbow method。
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3, random_state=0)
km.fit_transform(features)
cluster_labels = km.labels_
cluster_labels = pd.DataFrame(cluster_labels, columns=['ClusterLabel'])
pd.concat([corpus_df, cluster_labels], axis=1)

从上面的输出中可以看到,文档的聚类分配完全正确。
未来会涉及到的高级策略
在这篇文章没有涉及近期出现的一些关于文本数据特征工程的高级方法,包括利用深度学习模型来提取单词特征的方法。我们将在本系列的下一部分中深入探讨这些模型,并详细介绍 Word2Vec(http://mrw.so/1e3O2d ) 和 GloVe(http://mrw.so/1s38eg ) 等流行的单词嵌入模型,敬请期待!
总结
这些例子应该能有助于大家理解文本数据特征工程的一些通用策略。本文中介绍的是基于数学概念、信息检索和自然语言处理的传统策略,这些久经考验的方法在各种数据集和问题上都表现优异。在下一篇文章中,我将详细介绍如何利用深度学习模型进行文本数据特征工程。
对连续数据特征工程感兴趣的读者,请查看 本系列第一部分!
对离散数据特征工程感兴趣的读者,请查看 本系列第二部分!
本文中所使用的所有代码和数据集都可以从 GitHub(http://mrw.so/1Kyr6M ) 中访问。代码也可以作为 Jupyter(http://mrw.so/1iQMTh ) 笔记本使用。

NLP 工程师入门实践班:基于深度学习的自然语言处理
三大模块,五大应用,手把手快速入门 NLP
海外博士讲师,丰富项目经验
算法 + 实践,搭配典型行业应用
随到随学,专业社群,讲师在线答疑
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
深度学习在文本分类中的应用
▼▼▼



