【干货】理解特征工程Part 1——连续数值数据(附代码)
【导读】不管是机器学习、深度学习或统计方法,任何的智能系统都需要数据支持。而原始数据往往很难被算法直接利用,因此特征工程显得尤为重要。这是一篇完全手把手教你在实际应用中如何理解特征工程的教程,这是第一部分,作者研究了关于连续数值数据的特征工程的流行策略,通过实例和代码详细展示了连续数值数据特征工程的过程。
作者 | Dipanjan (DJ) Sarkar
编译 | 专知
翻译 | Xiaowen

Understanding Feature Engineering (Part 1) — Continuous Numeric Data
“金钱使世界运转”是你不能忽视的东西,不管是同意还是反对。在今天的数字革命时代,一个更贴切的说法是“数据使世界运转”。事实上,数据已经成为企业和组织的头等资产,不管它们的大小和规模如何。任何智能系统都不分大小。它们的复杂性需要由数据来驱动。作为任何智能系统的核心,我们有一个或多个基于机器学习、深度学习或统计方法的算法,它们消耗这些数据来收集知识并在一段时间内提供智能洞察力。算法本身非常天真,无法在原始数据上跳出方框。因此,从原始数据中获取有意义的特征是非常重要的,这些算法可以理解和使用这些特征。
机器学习管道(pipeline)的温和更新
任何智能系统基本上都由一个端到端的管道组成,从获取原始数据开始,利用数据处理技术从这些数据中获取、处理和设计有意义的特征和属性。然后我们通常利用统计模型或机器学习模型等技术对这些特征进行建模,如果有必要,根据手头要解决的问题部署此模型,以便将来使用。本文描述了一种典型的基于CRISP-DM工业标准过程模型的标准机器学习流水线。
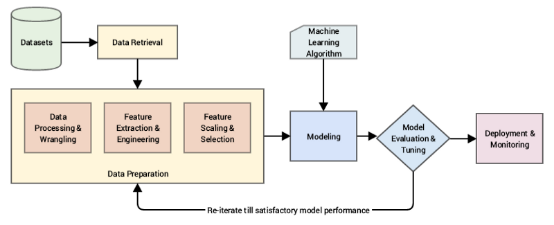
由于我们无法获得所需的结果或性能,并且算法还不够聪明,无法从原始数据中自动提取有意义的特征,因此在该数据的顶部直接摄取原始数据和构建模型是非常不明智的(有自动化的特征提取技术,这些技术在某种程度上是在深度学习方法中实现的)。
如图所示,我们主要关注的领域是数据准备方面,在原始数据经过必要的争论和预处理之后,我们利用各种方法从原始数据中提取有意义的属性或特征。
动机
特征工程是构建任何智能系统的重要组成部分。尽管你有许多新的方法,比如深度学习和元启发(meta-heuristics),它们都有助于自动机器学习,但每个问题都是特定领域的,而更好的特征(适合这个问题)往往是决定系统性能的因素。特征工程既是一门科学,也是一门艺术。在建模之前,数据科学家通常会把70%的时间花在数据准备阶段。让我们来看看数据科学领域的几位著名人士与特征工程相关的几句名言。
“提出特征是困难的,耗时的,需要专家知识。‘应用机器学习’基本上是特征工程。”——Andrew Ng.教授。
这基本上强调了我们前面提到的关于数据科学家花费近大部分时间在特征工程上的内容,这是一个困难且耗时的过程,需要丰富领域知识和数学计算能力。
“特征工程(Feature Engineering)是将原始数据转化为能更好地向预测模型表示潜在问题的特征的过程,从而提高了模型对未见数据的准确性。”——Jason Brownlee博士
这给了我们一个关于特征工程的想法,它是将数据转化为特征作为机器学习模型的输入的过程,这样高质量的特征有助于提高整个模型的性能。特征也很大程度上取决于潜在的问题。因此,即使机器学习任务在不同的场景中可能是相同的,比如将电子邮件分类为垃圾邮件和非垃圾邮件或对手写数字进行分类,在每一种场景中提取的功能将与其他场景非常不同。
华盛顿大学的Pedro Domingos教授在题为“关于机器学习的一些有用的知识”的论文中告诉我们:
“到最后,有些机器学习项目成功了,有些失败了。区别是什么?最重要的因素是使用的特征。”——Pedro Domingos教授
关于特征工程的最后一句话应该是来自著名的kaggler,Xavier Conor。你们中的大多数人已经知道,现实中很困难机器学习问题通常会定期发布在Kaggle上,这通常是对每个人开放的。
“我们使用的算法对于kagglers来说是非常标准的。我们在特征工程上花费了大部分精力。我们也非常小心地抛弃了可能会使我们面临模型过度拟合的风险的特征。”——Xavier Conort
理解特征
特征通常是原始数据顶部的特定表示,原始数据是一个单独的可测量属性,通常由数据集中的列表示。考虑一般的二维数据集,每个样本都由一行描述,每个特征都由一个列表示。
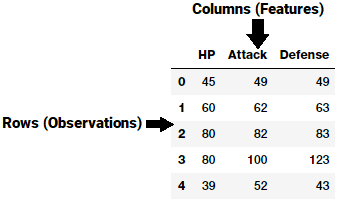
因此,在上面的图中的例子中,每一行通常表示特征向量,并且在所有样本中的整个特征集合形成一个二维特征矩阵,也称为特征集。这类似于表示二维数据的数据帧或电子表格。典型地,机器学习算法与这些数字矩阵或张量一起工作,因此大多数特征工程技术处理将原始数据转换成可以由这些算法容易理解的一些数字表示。
基于数据集的特征可以有两种主要类型。固有的原始特征直接从数据集中获得,没有额外的数据操作或工程。派生的特征(Derived features)通常是从特征工程中获得的,从现有的数据属性中提取特征。一个简单的例子是从包含“生日”的员工数据集中创建一个新的特征“年龄”,从当前日期减去他们的出生日期。
有多种类型和格式的数据,包括结构化数据和非结构化数据。在本文中,我们将讨论处理结构化连续数值数据的各种特征工程策略。所有这些示例都是我最近的一本书 ‘Practical Machine Learning with Python’的一部分,你可以访问本文在githube上使用的相关数据集和代码。
数值数据的特征工程
数值数据通常以标量值的形式表示数据,描述观测、记录或测量。在这里,数值数据是指连续数据,而不是通常表示为分类数据的离散数据。数值数据也可以表示为值的向量,其中向量中的每个值或实体都可以表示特定的特征。整数和浮点数是最常见和最广泛使用的数值。即使数值数据可以直接输入机器学习模型,但在构建模型之前,仍然需要设计与场景、问题相关的特征。因此特征工程的需求仍然存在。让我们利用python并研究一些关于数值数据的特征工程策略:首先,我们导入必要的模块:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import scipy.stats as spstats
%matplotlib inline
原始数据
正如我们前面提到的,原始数值数据通常可以根据上下文和数据格式直接输入机器学习模型。原始度量通常使用数值变量直接表示为没有任何形式的转换或工程的特征。通常这些特征可以表示值或计数。接下来加载数据集Pokémon dataset:
poke_df = pd.read_csv('datasets/Pokemon.csv', encoding='utf-8') poke_df.head()
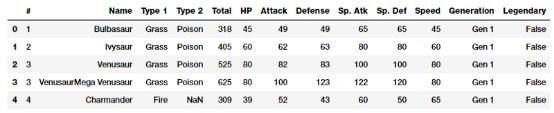
Pokémon是一部围绕虚构人物的媒体系列。简而言之,你可以把它们想象成具有超能力的虚构动物!这个数据集由这些人物组成,每个字符都有不同的统计数据。
值(Values)
如果在上面的图中仔细观察数据,可以看到有几个属性表示是可以直接使用的原始值。
poke_df[['HP', 'Attack', 'Defense']].head()
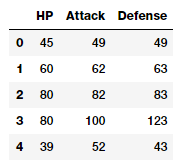
因此,你可以直接使用这些属性作为上述数据框架中描述的特征。这些特征包括每个Pokémon的hp(命中点)、攻击和防御状态。实际上,我们也可以计算这些领域的一些基本统计值。
poke_df[['HP', 'Attack', 'Defense']].describe()
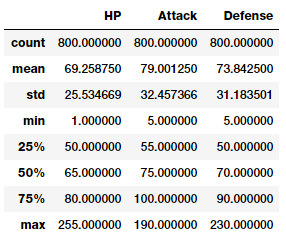
这样你就可以很好地了解这些特征中的统计度量,比如计数、平均值、标准差等。
计数(counts)
另一种形式的原始测量包括代表特定属性的频率、计数或出现的特征。让我们看一看来自百万歌曲数据集的数据样本,这些数据描述了不同用户听到的歌曲的数量或频率。
popsong_df = pd.read_csv('datasets/song_views.csv',
encoding='utf-8')
popsong_df.head(10)

从上面的快照可以清楚地看出,listen_count字段可以直接用作基于频率计数的数值特征。
二值化(Binarization)
通常,原始频率或计数可能与建立一个基于正在解决的问题的模型无关。例如,如果我正在为歌曲推荐构建一个推荐系统,我只想知道一个人是否感兴趣或是否听过一首特定的歌曲。这不需要听一首歌的次数,因为我更关心他听过的各种歌曲。在这种情况下,二进制特征比基于计数的功能更好。我们可以二进制化我们的listen_count字段,如下所示:
watched = np.array(popsong_df['listen_count'])
watched[watched >= 1] = 1
popsong_df['watched'] = watched
你可以利用scikit-learn's Binarizer类来代替numpy数组。
from sklearn.preprocessing import Binarizer
bn = Binarizer(threshold=0.9)
pd_watched = bn.transform([popsong_df['listen_count']])[0]
popsong_df['pd_watched'] = pd_watched
popsong_df.head(11)
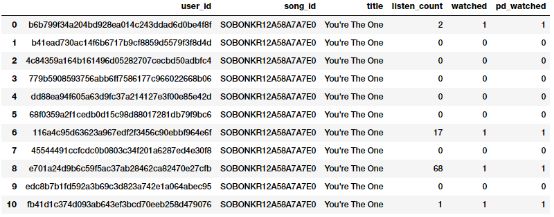
你可以从上面的图片中清楚地看到,这两种方法都产生了相同的结果。因此,我们获得了一个二进制特征,指示每个用户是否听过这首歌,然后可以在相关模型中进一步使用。
取整(Rounding)
通常在处理连续的数值属性如比例或百分比时,我们可能不需要原始值具有很高的精度。因此,将这些高精度百分比舍入数值整数通常是有意义的。然后,这些整数可以直接作为原始值,甚至可以用作绝对(基于离散类的)特征。让我们尝试将这一概念应用于描述存储项及其流行百分比的虚拟数据集中。
items_popularity = pd.read_csv('datasets/item_popularity.csv',
encoding='utf-8')
items_popularity['popularity_scale_10'] = np.array(
np.round((items_popularity['pop_percent'] * 10)),
dtype='int')
items_popularity['popularity_scale_100'] = np.array(
np.round((items_popularity['pop_percent'] * 100)),
dtype='int')
items_popularity
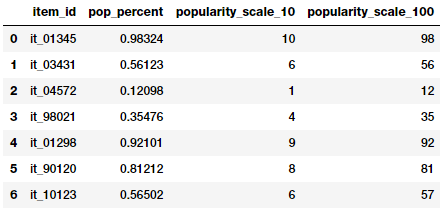
基于上面的输出,你可以猜到我们尝试了两种形式的取整。这些特征描述了项目的流行度,分别是1-10和1-100。你可以根据场景和问题使用这些值作为数值或分类特征。
交互(Interactions)
有监督的机器学习模型通常尝试将输出响应(离散类或连续值)建模为输入特征变量的函数。
其中,输入特征由变量描述,权重系数。
这种情况下,这个简单的线性模型描述了输出和输入之间的关系,完全基于单独的独立输入特征。
然而,在一些真实的场景中,也尝试将这些特征变量之间的交互作为输入特征集的一部分。简单地描述具有交互特征的上述线性回归公式如下:,其中特征表示为,表示交互特征。现在尝试在我们的Pokémon数据集上设计一些交互特征:
atk_def = poke_df[['Attack', 'Defense']]
atk_def.head()
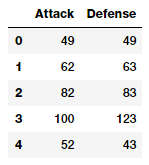
从输出数据框架中,我们可以看到我们有两个数值(连续)特征,attack和defense。
from sklearn.preprocessing import PolynomialFeatures
pf = PolynomialFeatures(degree=2, interaction_only=False,
include_bias=False)
res = pf.fit_transform(atk_def)
res
Output
------
array([[ 49., 49., 2401., 2401., 2401.],
[ 62., 63., 3844., 3906., 3969.],
[ 82., 83., 6724., 6806., 6889.],
...,
[ 110., 60., 12100., 6600., 3600.],
[ 160., 60., 25600., 9600., 3600.],
[ 110., 120., 12100., 13200., 14400.]])
上面的特征矩阵总共描述了五个特征,包括新的交互特征。我们可以在上面的矩阵中看到每个特征的程度。
pd.DataFrame(pf.powers_, columns=['Attack_degree',
'Defense_degree'])
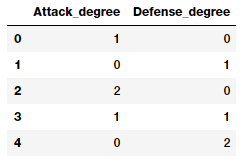
看看这个输出,我们现在从描述的程度中知道了每个特征实际上代表了什么。有了这些知识,我们现在可以为每个特征指定一个名称,如下所示。这只是为了便于理解,你应该用更好的、易于访问的和简单的名称来命名你的特征。
intr_features = pd.DataFrame(res, columns=['Attack', 'Defense',
'Attack^2',
'Attack x Defense',
'Defense^2'])
intr_features.head(5)
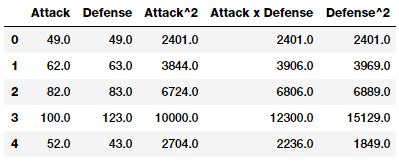
因此,上面的数据框架代表了我们的原始特征以及它们的交互特征。
量化(Binning)
使用原始的、连续的数值特征的问题是,这些特征中的值分布往往是倾斜的。这意味着一些值会非常频繁地出现,而有些值会非常罕见。此外,这些功能中的值的变化范围也有另一个问题,例如,特定音乐视频的视图数量可能会异常大,直接使用这些特征会引起很多问题,并对模型产生不利影响。因此,有一些策略可以解决这个问题,包括量化和转换。
Binning,也称为量化,用于将连续的数字特征转换为离散的特征(类别)。这些离散值或数字可以被认为是原始或连续的数值被分组。每个bin代表一个特定的强度程度,因此一个特定范围的连续数值落入其中。数据量化的具体策略包括固定宽度和自适应量化。让我们使用从2016 FreeCodeCamp Developer\Coder survey中提取的数据集中,其中讨论与编码器和软件开发人员相关的各种属性。
fcc_survey_df = pd.read_csv('datasets/fcc_2016_coder_survey_subset.csv',
encoding='utf-8')
fcc_survey_df[['ID.x', 'EmploymentField', 'Age', 'Income']].head()
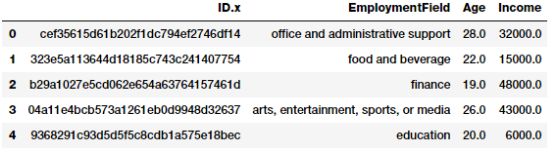
对于每个coder\developer来说,ID.x变量基本上是一个唯一的标识符,其他字段也非常清楚.
定宽量化(Fixed-Width Binning)
就像名称所示,在固定宽度的量化中,我们对每个bins都有特定的固定宽度,通常是由分析数据的用户预定义的。每个bin有一个预先固定的值范围,应该根据某些域知识、规则或约束分配给该bin。基于四舍五入的量化是其中一种方法,你可以使用前面讨论过的舍入操作来存放原始值。
现在让我们考虑编码器调查数据集中的年龄特征,并查看它的分布情况。
fig, ax = plt.subplots()
fcc_survey_df['Age'].hist(color='#A9C5D3', edgecolor='black',
grid=False)
ax.set_title('Developer Age Histogram', fontsize=12)
ax.set_xlabel('Age', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)
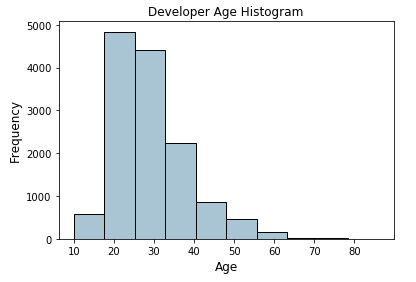
上面描述开发人员年龄的柱状图与预期的略有右偏(年龄较小的开发人员)。我们现在将根据以下方案将这些原始年龄值分配到特定的bin中。
Age Range: Bin
---------------
0 - 9 : 0
10 - 19 : 1
20 - 29 : 2
30 - 39 : 3
40 - 49 : 4
50 - 59 : 5
60 - 69 : 6
... and so on
我们可以很容易地使用我们在前面的四舍五入一节中学到的内容来实现这一点,在这里,我们将这些原始的年龄值除以10之后,取其作为基数。
fcc_survey_df['Age_bin_round'] = np.array(np.floor(
np.array(fcc_survey_df['Age']) / 10.))
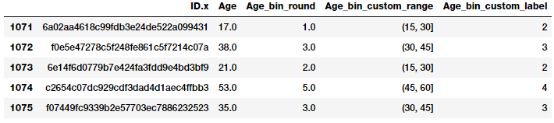
fcc_survey_df[['ID.x', 'Age', 'Age_bin_round']].iloc[1071:1076]

我们可以看到每个年龄的对应bin都是基于Rounding的。但是如果我们需要更多的灵活性呢?如果我们想要根据我们自己的规则逻辑来决定和修改bin宽度呢?基于自定义范围的Binning将帮助我们实现这一点。让我们使用下面的方案binning开发人员的年龄定义一些自定义年龄范围。
Age Range : Bin
---------------
0 - 15 : 1
16 - 30 : 2
31 - 45 : 3
46 - 60 : 4
61 - 75 : 5
75 - 100 : 6
基于此自定义合并方案,我们现在将为每个开发人员的年龄值标记bins,我们将同时存储bin范围和相应的标签。
bin_ranges = [0, 15, 30, 45, 60, 75, 100]
bin_names = [1, 2, 3, 4, 5, 6]
fcc_survey_df['Age_bin_custom_range'] = pd.cut(
np.array(
fcc_survey_df['Age']),
bins=bin_ranges)
fcc_survey_df['Age_bin_custom_label'] = pd.cut(
np.array(
fcc_survey_df['Age']),
bins=bin_ranges,
labels=bin_names)
# view the binned features
fcc_survey_df[['ID.x', 'Age', 'Age_bin_round',
'Age_bin_custom_range',
'Age_bin_custom_label']].iloc[10a71:1076]
自适应Binning
使用固定宽度binning的缺点是,由于我们手动确定bin范围,我们最终可能会出现不规则的bin,根据每个binning中的数据点或值的数目而不统一。其中一些bin可能人口稠密,有些甚至是空的!在这种情况下,自适应binning是一种更安全的策略。我们让数据自己说话!没错,我们使用数据分布本身来决定我们的bin范围。
基于分位数的binning是一种很好的自适应binning策略。分位数是特定值或切点,有助于将特定数字字段的连续值分布划分为离散的连续bins或区间。因此,q-分位数有助于将数字属性划分为q相等的分区。常用的分位数示例包括2-分位数,它将数据分布分为两个相等的bins,4-分位数将数据分成4个相等的bins,10-分位数创建了10个等宽的值。现在让我们来看看开发人员收入(Income)字段的数据分布。
fig, ax = plt.subplots()
fcc_survey_df['Income'].hist(bins=30, color='#A9C5D3',
edgecolor='black', grid=False)
ax.set_title('Developer Income Histogram', fontsize=12)
ax.set_xlabel('Developer Income', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)
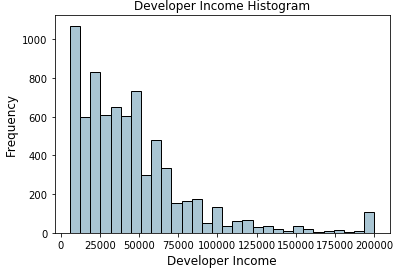
上面的分布描述了收入中的一个右偏,较少的开发人员赚了更多的钱,反之亦然。让我们采用基于4分位数的自适应二进制方案。我们可以很容易地获得四分位数,如下所示。
quantile_list = [0, .25, .5, .75, 1.]
quantiles = fcc_survey_df['Income'].quantile(quantile_list)
quantiles
Output
------
0.00
6000.0
0.25
20000.0
0.50
37000.0
0.75
60000.0
1.00
200000.0
Name: Income, dtype: float64
现在让我们在原始分布直方图中可视化这些分位数!
fig, ax = plt.subplots()
fcc_survey_df['Income'].hist(bins=30, color='#A9C5D3',
edgecolor='black', grid=False)
for quantile in quantiles:
qvl = plt.axvline(quantile, color='r')
ax.legend([qvl], ['Quantiles'], fontsize=10)
ax.set_title('Developer Income Histogram with Quantiles',
fontsize=12)
ax.set_xlabel('Developer Income', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)
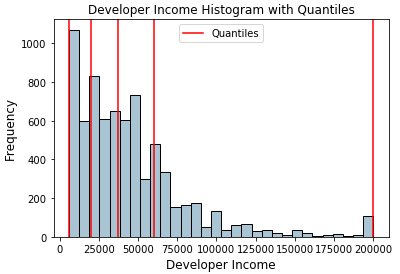
以上分布中的红线描述了四分位数值和我们的潜在bins。现在让我们利用这些知识来构建基于四分位数的二进制方案。
quantile_labels = ['0-25Q', '25-50Q', '50-75Q', '75-100Q']
fcc_survey_df['Income_quantile_range'] = pd.qcut(
fcc_survey_df['Income'],
q=quantile_list)
fcc_survey_df['Income_quantile_label'] = pd.qcut(
fcc_survey_df['Income'],
q=quantile_list,
labels=quantile_labels)
fcc_survey_df[['ID.x', 'Age', 'Income', 'Income_quantile_range',
'Income_quantile_label']].iloc[4:9]
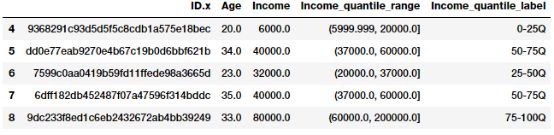
这应该让你对基于分位数的自适应二进制工作有一个很好的了解。这里需要记住的一点是,二进制的结果会导致离散值的分类特征,在使用任何模型之前,你可能需要对分类数据进行额外的特征工程步骤。我们将在下一部分中讨论分类数据的特征工程策略。
统计变换
我们刚才简要地讨论了倾斜数据分布的不利影响。我们现在通过使用统计或数学变换来看一种不同的特征工程策略。我们将研究log变换以及Box-Cox变换。这两个变换函数都属于幂变换函数族,通常用于创建单调的数据转换。它们的主要意义是有助于稳定方差,严格遵循正态分布,使数据独立于均值分布。
Log变换
log变换属于幂变换函数族,这个函数可以数学地表示为,然后可以将它转换为。自然对数使用b=e,其中e=2.71828,俗称欧拉数。你也可以使用在十进制中常用的基数b=10。
当应用于偏斜分布时,对数转换是有用的,因为它们倾向于扩展落在较低幅度范围内的值,并且倾向于压缩或减小落入更高幅度范围内的值。 这倾向于使倾斜分布尽可能地正常。 让我们先使用我们以前使用的开发人员收入特征做log变换。
fcc_survey_df['Income_log'] = np.log((1+ fcc_survey_df['Income']))
fcc_survey_df[['ID.x', 'Age', 'Income', 'Income_log']].iloc[4:9]
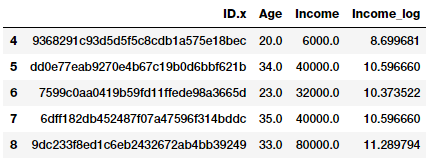
Income-log字段描述了经过log转换后的转换特征。现在让我们来看看这个转换字段上的数据分布。
income_log_mean = np.round(np.mean(fcc_survey_df['Income_log']), 2)
fig, ax = plt.subplots()
fcc_survey_df['Income_log'].hist(bins=30, color='#A9C5D3',
edgecolor='black', grid=False)
plt.axvline(income_log_mean, color='r')
ax.set_title('Developer Income Histogram after Log Transform',
fontsize=12)
ax.set_xlabel('Developer Income (log scale)', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)
ax.text(11.5, 450, r'$\mu$='+str(income_log_mean), fontsize=10)
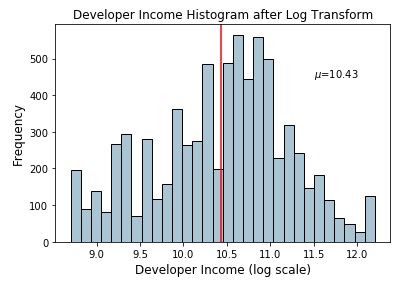
根据上面的图,我们可以清楚地看到,与原始数据上的倾斜分布相比,这种分布更像正态分布或高斯分布
Box-Cox 转换
Box-Cox变换是另一个属于幂变换函数族的流行函数。这个函数有一个先决条件,即要转换的数值必须是正的(类似于log变换所期望的值)。如果它们是负值,则使用常值帮助移动。从数学上讲,box-Cox变换函数可以表示如下。
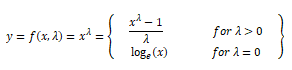
当λ=0时,得到的转换输出y是输入x的函数,当λ=0时,得到的变换是我们前面讨论过的自然对数变换。λ的最优值通常是用极大似然或对数似然估计来确定的。让我们现在将box-Cox变换应用于我们的开发人员收入特征。首先,我们得到了最优λ。通过删除非空值从数据分布中获取以下值。
income = np.array(fcc_survey_df['Income'])
income_clean = income[~np.isnan(income)]
l, opt_lambda = spstats.boxcox(income_clean)
print('Optimal lambda value:', opt_lambda)
Output
------
Optimal lambda value: 0.117991239456
现在我们已经得到了最优的λ值,让我们对λ的两个值使用box-Cox变换,使得λ=0和λ=λ(最优),并转换开发人员的收入特征。
fcc_survey_df['Income_boxcox_lambda_0'] = spstats.boxcox(
(1+fcc_survey_df['Income']),
lmbda=0)
fcc_survey_df['Income_boxcox_lambda_opt'] = spstats.boxcox(
fcc_survey_df['Income'],
lmbda=opt_lambda)
fcc_survey_df[['ID.x', 'Age', 'Income', 'Income_log',
'Income_boxcox_lambda_0',
'Income_boxcox_lambda_opt']].iloc[4:9]
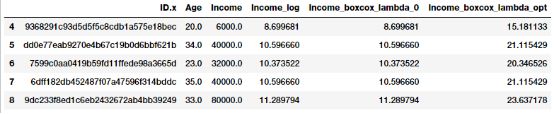
转换后的特征在上面的数据框架中得到了描述。正如我们所预期的,Income_log和Income_boxcox_lamba_0有相同的值。让我们来看看转换后收入特征与最优λ转换后的分布情况。
income_boxcox_mean = np.round(
np.mean(
fcc_survey_df['Income_boxcox_lambda_opt']),2)
fig, ax = plt.subplots()
fcc_survey_df['Income_boxcox_lambda_opt'].hist(bins=30,
color='#A9C5D3', edgecolor='black', grid=False)
plt.axvline(income_boxcox_mean, color='r')
ax.set_title('Developer Income Histogram after Box–Cox Transform',
fontsize=12)
ax.set_xlabel('Developer Income (Box–Cox transform)', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)
ax.text(24, 450, r'$\mu$='+str(income_boxcox_mean), fontsize=10)
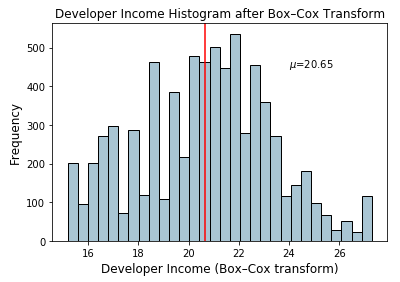
这种分布看起来更像对数变换后得到的分布。
结论
特征工程是机器学习和数据科学的一个非常重要的方面,不应该被忽视。虽然我们有自动化的特征工程方法,如深度学习,以及自动化的机器学习框架(这仍然强调它需要良好的特征才能正常工作!)。特征工程仍然存在,甚至有些自动化的方法往往需要基于数据类型、域和要解决的问题的特定的工程特征。
在下一部分中,我们将研究处理离散、分类数据的流行策略,然后在以后的文章中继续讨论非结构化数据类型。请继续关注!
本文中使用的所有代码和数据集都可以从下面链接中获取。
https://github.com/dipanjanS/practical-machine-learning-with-python/tree/master/notebooks/Ch04_Feature_Engineering_and_Selection
原文链接:
https://towardsdatascience.com/understanding-feature-engineering-part-1-continuous-numeric-data-da4e47099a7b
更多专业AI教程资料请加入专知人工智能知识星球群获取,扫描下面二维码即可!
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能知识星球服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知





