行人再识别ReID论文阅读-SPGAN
来源:https://zhuanlan.zhihu.com/p/31681715
CVPR 2018 Submission deadline之后,发现一大波ReID相关论文放出来,意料之内的惊喜与随之而来的压力和动力!其中有不少有趣的工作,这里先介绍一下个人比较喜欢的一篇文章SPGAN —“Image-Image Domain Adaptation with Preserved Self-Similarity and Domain-Dissimilarity for Person Re-identification”[1]。
开篇明义,首先表明本人比较欣赏这篇文章的点:
想法新颖——改进CycleGAN把source domain的图片转换成target domain的风格,可视化效果合理;
做法简单直接——针对ReID 的在转换过程中ID不变的特性,巧妙地增加了Similarity Preserving Loss,使生成的图片更加合理(可见文中Figure4),即SPGAN = CycleGAN + L(ide)+L(con);
效果明显——有效提升了unsupervised ReID的效果。
纲要
本人将根据如下四个问题来解读这篇文章:
问题一:该文章是为了解决什么问题,并且提出怎样的解决方法?
问题二:如何实现source-target translation?——提出SPGAN
本文提出similarity preserving loss function
CycleGAN baseline[2]
CycleGAN +L(ide)[3]
CycleGAN [2]
针对ReID问题,提升generator效果
问题三:生成的图片如何利用?
特征学习:参考ID-discriminative Embedding [4]。
转换的图片存在noise:提出Local Max Pooling。
问题四:效果如何?
我的疑问
问题一:该文章是为了解决什么问题,并且提出怎样的解决方法?
本文主要是为了解决ReID中的两个痛点
痛点1:在一个dataset/domain训练好的模型,在另外一个dataset上基本就是废了,其实这不仅是ReID存在的问题,很多任务也有类似的现象。
痛点2:unsupervised image-image translation过程中,source-domain labels 信息会丢失。
针对这两个问题,本文提出了相应的解决方法
解决痛点1:domain adaptation
之前的方法有通过学source target mapping等等,这里不阐述了。
而该文方法是提出一个“learning via translation”framework,使用GAN把source domain的图片转换到target domain中,并使用这些translated images训练ReID model。流程如下图Figure2。
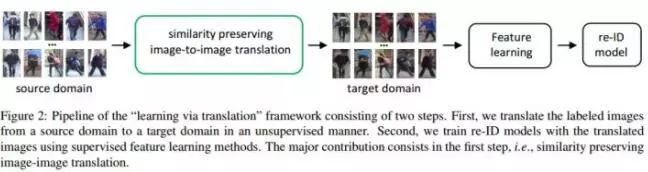
解决痛点2:结合ReID问题的特性,充分利用source domain的信息,也是文章说到的两个motivation
(1)对于每张图片,ID信息对于识别有重要意义,需要保留 --> self-similarity。可见下图Figure1,转换前后的图片要尽量相似。
(2)source 和 target domain中包含的人员是没有overlap的,因此,转换得到的图片应该要和target domain的任何一张图片都不相似--> domain-dissimilarity。
因此,作者提出Similarity Preserving GAN (SPGAN)来实现他的两个motivation。

问题二:如何实现source-target translation?——SPGAN
这一块是文章的重点,这里将分以下思路来解析:
CycleGAN 简介
CycleGAN baseline[2]
CycleGAN +L(ide)[3]
针对ReID特性(self-similarity, domain-dissimilarity):本文提出similarity preserving loss function
首先,我们看看为什么SPGAN有这几个步骤。见下图Figure4,第一行是原图,第二行是通过CycleGAN生成出来的图片,看起来有点可怕,不符合实际情况。第三行是增加了L(ide)的效果,比CycleGAN稍微好了点,但是仍然有一定的失真,风格也不符合实际情况。第四行是做做SPGAN生成的,效果比前面的都真实多了。

CycleGAN baseline
CycleGAN 是这篇文章的基础,我们需要先了解它,有兴趣深究的同学可以看看文章[2],很赞的工作,还有开源代码。这里我们只是简单介绍一下。
CycleGAN用于无配对图片之间的生成,它有两对generator-discriminator pairs,分别用于source->target, target-source的转换。并且,由于没有配对图片,两个domain之间的映射函数是无穷的,因此CycleGAN还有一个cycle-consistent loss来降低映射空间的可能性,如下
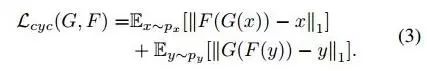
这个loss通过控制source domain的图片x,通过source to target的生成器G后,生成的图片G(x),可以根据target to source生成器F,得到新的图片F(G(x))尽量和x相似。y也是同理。
作者使用CycleGAN生成了上图Figure4(b)的图片,这个当然不是我们想要的图片啦,图片颜色变得好严重,不真实。因此需要引入更多的限制,从而生成更合理的图片,因此,引入target domain identity constraint[3]。
CycleGAN+L(ide)
提升generator效果通用方法:L(ide), target domain identity constraint [3]
为了提升生成效果,作者还用了[3]的方法,L(ide) loss,如下:
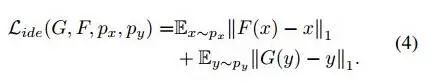
这个loss的含义是:对于target to source生成器F,如果输入是source domain的图片x(而不是target domain的y),那么也要生成出于x相似的图片。加了这个限制之后,图片颜色就相对稳定了些,不至于很夸张。
但是这对于ReID任务来说还不够,我们还有更多的信息可以利用呢!也就是开头提的self-similarity 和 domain-dissimilarity,这里就正式进入了SPGAN。
SPGAN
针对ReID特性(self-similarity, domain-dissimilarity),文章就提出了similarity preserving GAN (SPGAN)。
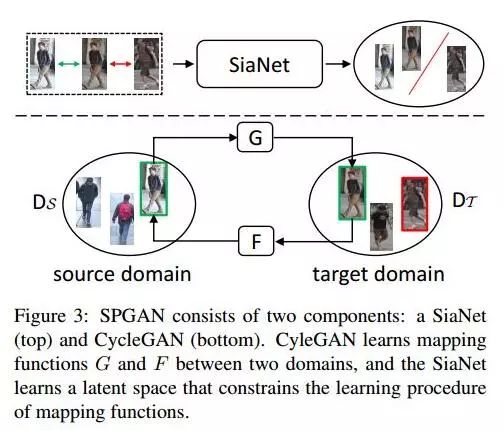
SPGAN包含两个部分,一个是上面说的CycleGAN+L(ide),另一个是SiaNet。其中,SiaNet就是用于实现self-similarity 和 domain-dissimilarity的。
这节主要介绍SiaNet。如下图Figure3,SiaNet是通过一对对image pair实现的,绿色箭头指向positive pair(一张是source domain的原图,一张是生成的图片),红色箭头指向negative pair(一张是生成的图片,一张是target domain的图片)。这里的学习目标也是要让正对的距离小(即,self-similarity ),负对的距离大(即,domain-dissimilarity)。因此,作者提出了Similarity preserving loss 来实现这个功能。
Similarity preserving loss function 如下:

这个loss的意思上图也解析得很清楚啦,就是说正对的距离越小越好,负对距离越大越好,当然还有个margin m来控制一定范围啦。
这里重点要说的是image pair selection!
假设x_s为source domain的图片,x_t为target domain的图片,G是source->target的生成器,F是target->source的生成器。
正对:反映self-similarity,有两种类型—— (x_s, G(x_s)) 和 (x_t, F(x_t))——表示同一张图片,转换前后需要尽量相似。
负对:反映domain-dissimilarity,也有两种类型——(x_t, G(x_s)) 和 (x_s, F(x_t))——表示来自不同domain的图片,即使转换到相同domain,也不能相似。
综上,SPGAN = CycleGAN + L(ide) + L(con),总体的loss function如下:
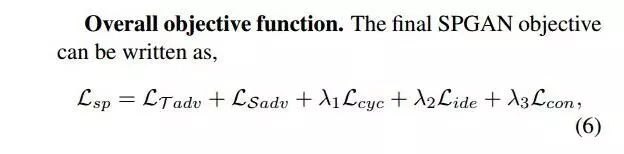
问题三:生成的图片如何利用?
step1: feature learning
生成的图片可以当作是target domain的data,直接训练模型。关于这一步文章没有深究,直接使用了[4]中的方法来学习特征提取模型。
step2: Local Max Pooling (LMP)
由于生成的图片存在一定的noise,作者引入了LMP来降低noise的影响,并提升识别效果。这一步是使用在testing中的,具体方法如下图,把feature map横着分成有overlap的P块,并concat起来,从而得到更好的feature。
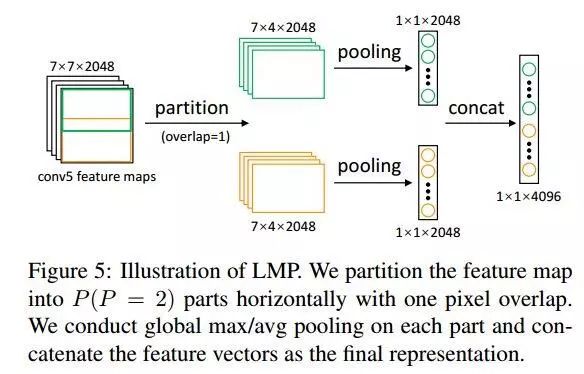
问题四:效果如何?
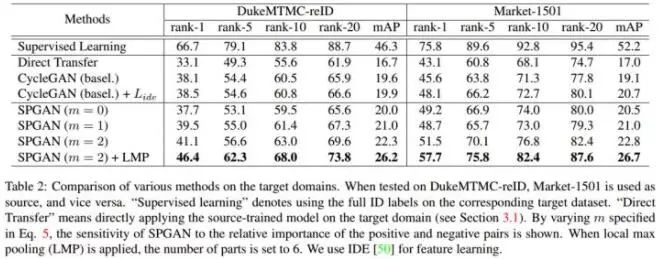
全文最重要的一个实验:验证SPGAN的每一个component的效果。
如下Table2,可见每一个component都能有效地提升识别的效果。另外,看Figure4,视觉效果也有提升。
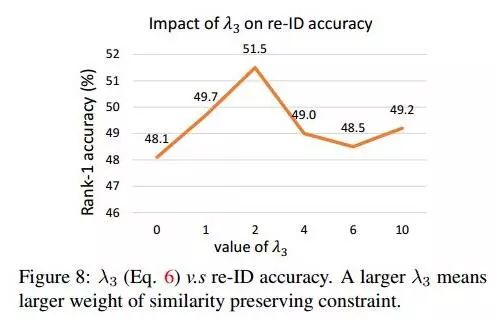
每个loss之间的权重如何选择,见如下实验
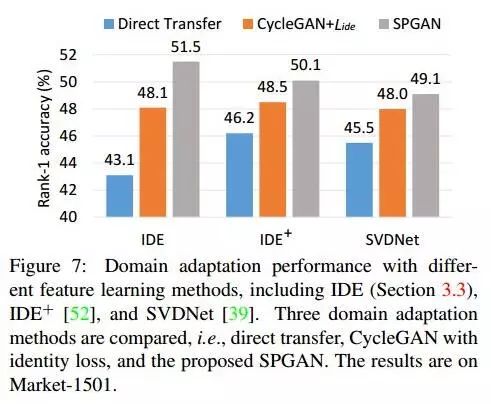
更换不同的feature learning methods,该方法也同样适用,见下图Figure7
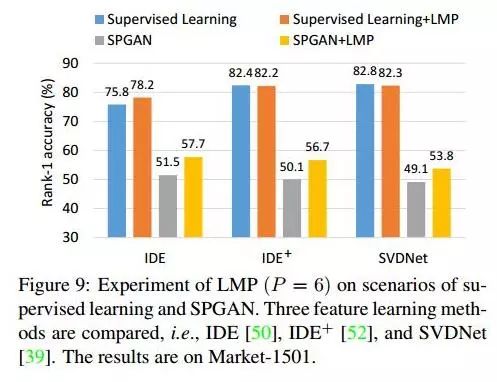
验证LMP有效
(1)见每个table中+LMP的,都有一定提升
(2)LMP比较适用于用生成图片训练的模型,用supervised learning方法的,LMP并不是每次都有提升,见如下Figure9。
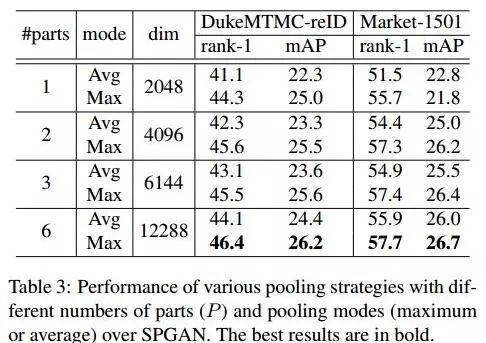
(3)怎么选用了LMP,见如下Table3,实验定的。
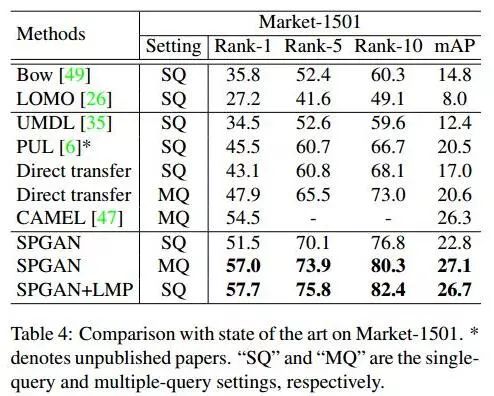
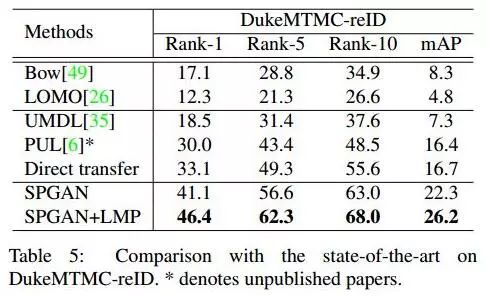
与state-of-the-art methods比较
对比效果也是不错的,但是有个疑问:Market-1501怎么没有给出SPGAN+LMP MQ的效果呢?
我的疑问
如果用 label data from target domain + source-target translated data 同时训练,效果会比 supervised learning的好吗?
Market-1501为什么没有比较SPGAN+LMP,MQ?
如何设置λ_2 ?
[1] Deng et al. Image-Image Domain Adaptation with Preserved Self-Similarity and Domain-Dissimilarity for Person Re-identification. arXiv, 2017.
[2] J. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired imageto-image translation using cycle-consistent adversarial networks. ICCV, 2017.
[3] Y. Taigman, A. Polyak, and L. Wolf. Unsupervised crossdomain image generation. ICLR, 2016.
[4] L. Zheng, Y. Yang, and A. G. Hauptmann. Person reidentification: Past, present and future. arXiv preprint arXiv:1610.02984, 2016
PS.极市平台正寻求与开发者视觉算法的合作,欢迎联系小助手(微信:Extreme-Vision)沟通合作~ 2018一起旺起来


