聚合:从表格和均值到最小二乘| 统计学七支柱
下文节选自《统计学七支柱》, 已获人邮图灵许可, [遇见数学] 特此表示感谢!
第一根支柱——聚合,不仅最古老,也最激进。在19世纪,它被称为“观测的组合”。这种说法表达的思想是:把数据集中的个体值进行统计汇总,概括出的信息可以超越个体。统计学的整体概括大于各部分的加总。样本均值就是这样一个例子,它是较早就被大家重视的一门技术,同样的思想也反映在其他一些汇总指标上,比如加权均值,甚至最小二乘在本质上也是一种基于个体数据值的特征进行加权或调整的平均值。
在分析中,对数据以任何形式取均值都是一个相当激进的步骤,因为取均值会丢弃数据中的信息,让每个观测值失去个性:测量的顺序和不同的产生环境,包括观测者的身份。

英国派往檀香山的观测队队长乔治·莱昂·塔普曼与他架设的望远镜
图自: wiki
1874年曾有一次万众瞩目的“金星凌日”,是1769年以来的第一次,因此许多国家都向最佳观测位置派遣了远征队。获知凌日开始与结束的确切时间,可以帮助精准确定太阳系的规模。不同城市的观测人员提供的观测报告能相似到使均值有意义吗?这些观测是由技术水平不同的人,使用不同的设备,在不同的地点和稍有不同的凌日发生时间做出的。就此而言,如果单个观测者连续观测一颗恒星的位置,切实感受每次抖动、停顿和心烦意乱,是否足以拿来取均值呢?在古代甚至现代,对每个观测环境过于熟悉会打消组合观测的意愿,人们忍不住要去选择那个认为是最好的观测,而不会用其他疑为较差的观测值来跟它求均值。
即便在取均值的方法变得司空见惯之后,人们也不见得总能接受“信息少即是多”的想法。19世纪60年代,威廉姆·斯坦利·杰文斯提出,通过价格指数来测量价格水平的变动,也就是采用不同商品价格变动的百分比的均值,就有批评人士认为,把生铁和胡椒的价格放在一起取均值非常荒谬。并且,一旦讨论到某个商品,这些历史知识渊博的研究者们总会认为,他们可以借助某个特定事件发生的缘由故事“解释”这个商品的每个变动和波动。1869年,杰文斯强烈谴责了这种理由:“如果每个波动都需要复杂的解释,那么不仅这个主题的所有相关探索都没有希望,而且还得放弃那些依赖数值事实的完整统计和社会科学。”这并不是说讲述数据的故事错了,而是说数据(以及单独观测的个体特点)需要置于背景之中。如果需要揭示一般性的趋势,那么必须将观测视为一个集合,必须把它们组合起来。
豪尔赫·路易斯·博尔赫斯理解这一点。他于1942年出版了奇幻短篇小说《博闻强识的富内斯》,其中描述了一个叫作伊雷内奥·富内斯的人。一次事故后,富内斯发现自己几乎能记住所有事情。他能以最微小的细节重新建构每一天,甚至以后能再重复这次重构,但他缺乏理解能力。博尔赫斯写道:“思维是忘却差异,是归纳,是抽象化。而富内斯的拥塞世界中仅仅充斥着触手可及的细节。”汇总产生的益处大于个体。富内斯正是没有经过统计处理的大数据。
算术均值是什么时候开始用于概括数据集的?又是在什么时候受到广泛采用的?这两个问题相当不同。第一个问题也许没有答案,理由随后会讲。第二个问题似乎在17世纪的某段时间得到了答案,但无法确定精准日期。为了更好地理解测量和涉及的这种报告问题,我们来看一个有趣的例子,它的内容包括了可能最早使用“算术平均”这种说法的出版例子。
1.1 指针的变化
到1500年,热爱冒险的水手日益增多,他们把磁罗盘或“指针”当作必备工具。无论在任何地方和任何天气情况下,指南针都可以读出“磁北”。更早的一个世纪以前,人们就已经公认“磁北”与真正的北方有差异;而1500年,人们还认识到,真正的北方和“磁北”之间的差异会随着地点变动。差异数量通常比较可观——10°,也许偏东,也许偏西。当时,人们相信原因是海边缺乏磁引力,所以指南针的偏差指向大陆而偏离海洋。因此,需要通过指南针的修正找到真正的北方,这称为“指针的变化”。那时,一些航行地图会在关键位置,比如通航的海峡或者海上可见的显著标志,标注这种修正的已知大小,水手们信任这些记录的偏差。威廉·吉尔伯特1600年出版了地磁学经典著作《论磁》,其中给出报告:只要地球稳定,就可以信赖每个位置的变化的恒定性,“因为磁针总是偏向东或者偏向西,所以即使在今天,无论在任何地点或区域,无论是海洋或陆地,变化弧度都保持相同。因此,除非发生大陆崩塌和国家湮灭,就像柏拉图和其他古代作家所讲的亚特兰蒂斯地区那样,否则它将永远不变”。
唉!水手们和吉尔伯特“痴心错付”了。1653年,亨利·盖里布兰德比较了伦敦同一地点、时间相隔50多年的一系列磁针变化的测定,他发现这些变化已经发生了相当大的变动。1580年,真正的北方需要向东修正11°;而在1634年,修正已经减少到大约向东4°。这些早期测量结果的每一个都是基于几个观测值进行的计算,仔细分析后可以发现,这些观测者们也都各自在朝着“使用算术平均”摸索前进,但从未明确说明要这么做。
1581年,威廉·布劳出版了一本题为《指南针或磁针变化的一个讨论》的小册子,是早期测定指针变化的一份最佳记录。在第三章中,他描述了测定变化值的一种方法,这种方法不需要预先知道真正北方在观测点的什么方位,他还实际演示了一次,在伦敦东部尽头的港口区莱姆豪斯,那地方距离格林尼治子午线不远。他提出使用一个星盘——其实就是一个标有刻度的铜盘,垂直悬挂的同时用一个取景器观测太阳并记下它的高度。每当太阳到达一个新的高度角(在中午之前上升,在中午之后下降),他就观察并记录罗盘表面一条阴影线的方向,这样可以取得太阳与磁北偏差的一个读数。太阳抵达子午线时,高度角会达到最大值,那时它在真正的北方(如图1-1所示)。
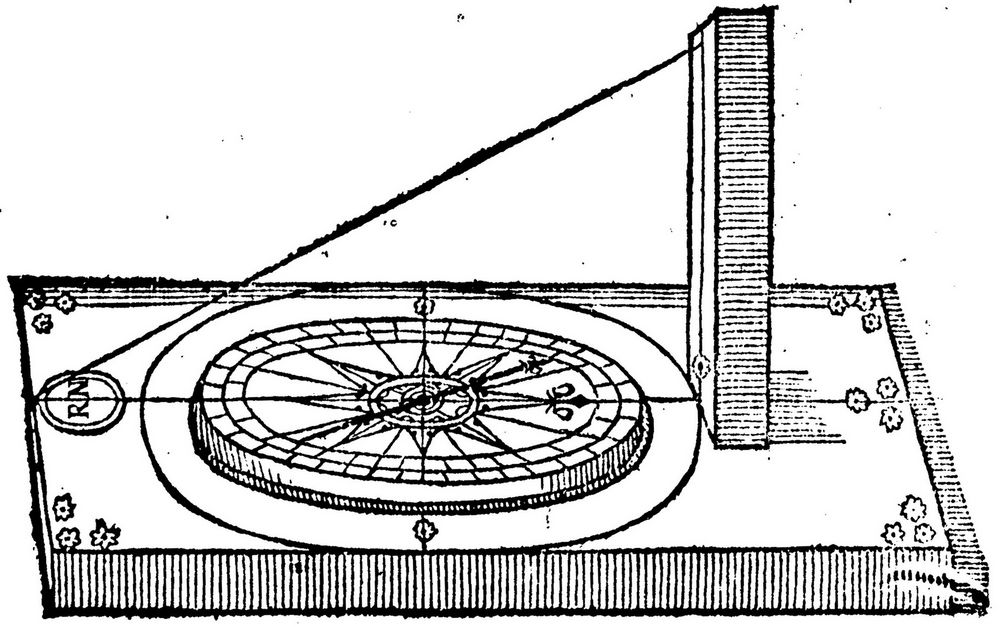
图1-1 布劳使用的罗盘。垂直的柱子在罗盘北端,标记着一朵鸢尾花。附加的首字母R. N. 指罗伯特·诺曼(Robert Norman),他预定了布劳的小册子。布劳在文中所指的罗盘上的“点”不是显示的8个点,而是由分割线将其间隔再分割为4部分,因此整个圆划分为32个部分,每个部分的大小为11°15'(参见Norman 1581)
布劳会考虑在同样的太阳高度角进行的每一对观测结果,一次在上午(图1-2中的Fornoone,以下命名为AM),另一次在下午(图1-2中的Afternoone,以下命名为PM)。一方面,如果莱姆豪斯的真正北方与磁北一致,那么共同值应该是(接近)两个测量的中点。因为太阳经过了一个对称弧度,在子午线(“正午”)的角度最大。另一方面,如果磁北位于真正北方以东10°,那么早晨的阴影应该向西偏10°,并且下午的影子也一样。无论哪种情况,成对观测的平均值应该就是磁针的变化。布劳1580年10月16日观测的数据表格如图1-2所示。
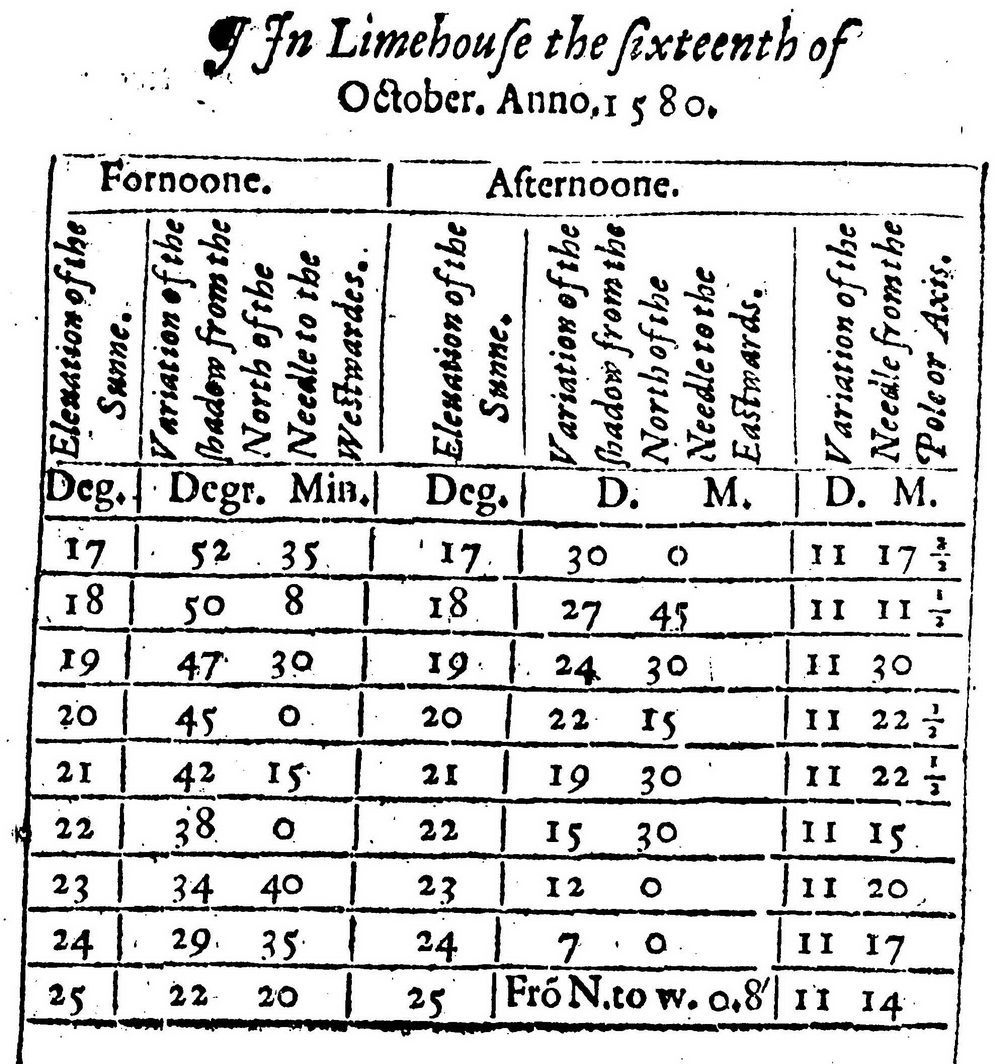
图1-2 布劳1580年在伦敦附近的莱姆豪斯对磁针变化的观测数据(参见Norman 1581)
他有9对数据,取自高度角从17°~25°的上午变化(偏西的角度)和下午变化(偏东的角度,因此和早晨的符号相反;除了25°的下午测量,它稍微有点偏西)。因为上午和下午的符号不同,可以发现,图1-2右侧栏中的变化是变化差除以2的结果。例如,对于在太阳高度角23°的观测对,我们有

计算出的这9个测定值相当接近,但又不完全相同。布劳是如何决定报哪一个数字的呢?在前统计时代,很明确是需要数据报告的,但又因为没有一致认可的一套概括方法,故而也就不需要描述什么概括方法,实际上也没有先例可循。布劳的答案很简单:参考右侧栏,他写道,“经过综合考虑,我确信莱姆豪斯真正的磁针或罗盘的变化是11又1/4°或11又1/3°,这刚好是罗盘上的一个点或稍多一点儿的值”。他给出的值是11°15',不能对应到任何现代的概括度量上——它小于均值、中位数、中点以及众数。它符合22°高度角的值,并有可能就是这么选出的。但为什么23°高度角的数字会给出11°20′呢?也或许和他四舍五入到与“罗盘上的一个点”相一致,即11°15',罗盘上每相邻2个点之间的距离。无论如何,布劳认为没有必要给出正式的折中。他可以取上午和下午同一个高度角的平均值,但他用了一种聪明的做法:使用观测的对比得到结果,而不使用基本相等的观测的组合。“平均”就是一种“前减后”的对比。
半个多世纪之后的1634年,格雷山姆学院天文学教授盖里布兰德重温了这个问题(如图1-3所示)。12年前,他在格雷山姆学院的前任埃德蒙·甘特在莱姆豪斯重复了布劳的实验,得到磁针变化的8个测定值。结果范围大约是6°,与布劳的11又1/4°相去甚远。甘特是一位杰出的观测者,但他缺乏将这个结果推广成一项发现的想象力,而将这个矛盾之处归结为布劳的错误。盖里布兰德对布劳极为尊敬,因此并不支持这种观点,他遗憾地写道:“这种巨大的差异使得我们当中某些人过早地中伤了布劳先生的观测(虽然某些仅仅是借口)。”盖里布兰德试着调整布劳关于太阳视差的数字,使用了第谷·布拉赫的一个方法,布劳时代还没有这个方法,但是发现影响可以忽略(比如,布劳对于20°高度角的值是11°22又1/2′,变成了大约11°32又1/2′)。于是,盖里布兰德开始使用昂贵的新设备(包括一个代替星盘的六英尺四分仪)在德特福德进行观测,这里是泰晤士河南岸,与莱姆豪斯隔河相望,并位于同一经度。

图1-3 盖里布兰德小册子的封面(参见Gellibrand 1635)
1634年6月12日,盖里布兰德采用基于第谷表格的方法,分别做出了磁针变化的11个测定:5个在上午,6个在下午(如图1-4所示)。最大的是4°12',最小的是3°55'。他总结说:
这些一致的观测产生的变化不会大于4°12′或小于3°55′,算术平均将其限制在大约4°4′。(此处的“度”的原文为gr.,简单地指代degree,是当时的一种“有刻度”的标尺单位。18世纪90年代法国大革命时期,标尺用gr.指代grad,表示直角的1/100。)
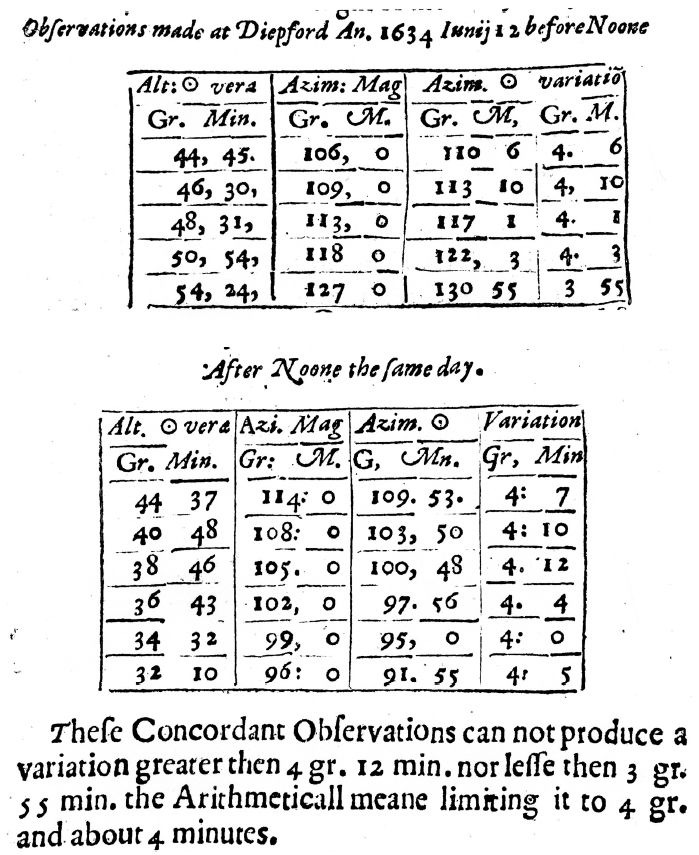
图1-4 盖里布兰德的数据和“算术平均值”的出现(参见Gellibrand 1635)
那么,盖里布兰德报告的“均值”并不是所有11个观测的算术平均值——4°5'。相反,他给出了最大值和最小值的平均值,也就是后世统计学家们所说的“中点”,所以并不引人注目。尽管这是两个观测值的算术平均,但好像也没有其他方式可以生成两个数中间的数值了。事实上,早年的天文学家们面对两个值只需要取一个时,已经使用了算术平均或者类似的计算。可以确定,第谷和开普勒在17世纪早期,甚至阿尔-比鲁尼可能在公元1000年前后就使用了算术平均或者类似的计算。不过,盖里布兰德给所用的方法起了一个名字,这个术语是他工作的新颖之处。古人其实也了解这个名词,但看来没有人认为真有必要把它用于自己的著作中。
观测的统计分析确已进入新阶段,一个标志是1668年英国《皇家学会会刊》中的一个简短注记,其内容还是与磁针的变化有关。编辑亨利·奥尔登伯格刊登了某位姓名简写为D. B. 的人的信件摘录,其中给出了布里斯托尔附近的某个位置磁针变化产生的5个值(如图1-5所示)。

图1-5 D. B. 信件公开的部分(参见D. B. 1668)
D. B. 报告了斯特米船长的总结:“采用这张表格的时候,他注意到最大距离或差异是14′。因此,他对真正的变化取均值,并推断在当时当地,即1666年6月13日的变化,仅为1°27′。”尽管真实的均值是1°27.8',并且斯特米船长(或者数学家斯特恩莱德)做了向下舍去,但无论如何都很明显,到17世纪的最后三十多年,算术平均值已经受到正式认可,成为组合观测的一种方法。它的诞生时间也许永远是个谜,但其诞生事实似乎无可辩驳。
1.2 古代的聚合
统计概括与书写一样拥有悠久的历史。图1-6是一块大约公元前3000年(与书写的起源时间很接近)的苏美尔人的泥板文书复原品,由芝加哥大学东方研究所的同事克里斯·伍兹向我展示。
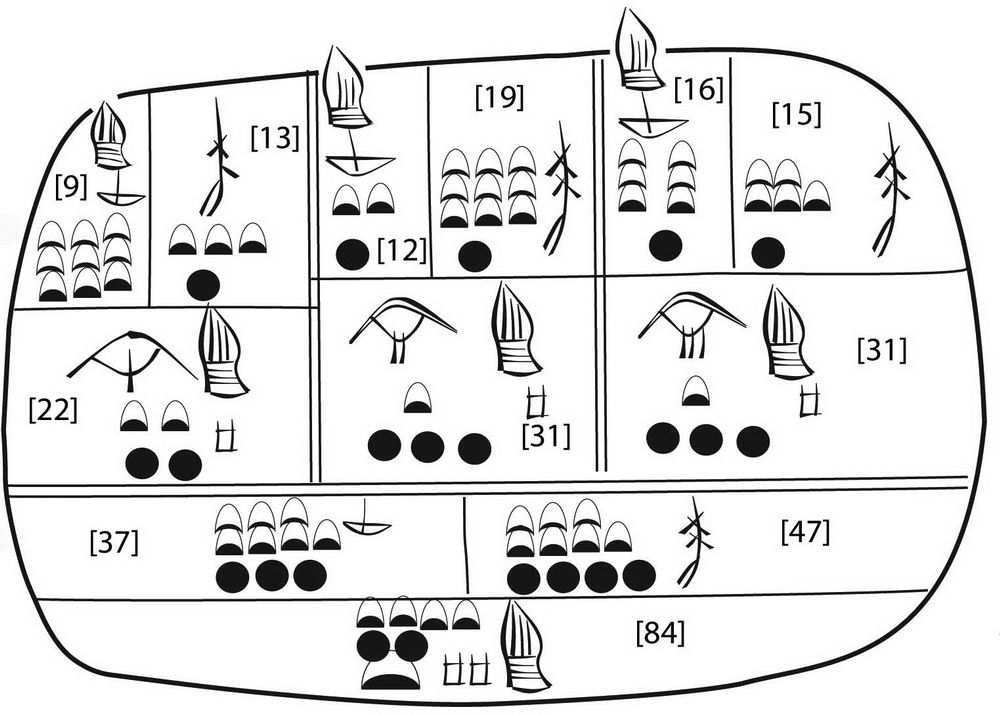
图1-6 一块大约公元前3000年的苏美尔人泥板文书重现,添加了现代的数字(由罗伯特·英格伦复原,参见Englund 1998, 第63页)
这块泥板代表的内容相当于一个2 × 3的列联表,显示了两种类型的商品计数,可能是两种作物3年内的产量(加上了现代的数字)。顶上一行显示了6个单元格,商品符号显示在相应的计数之上。第二行是年份或者列的总计,第三行是两种作物行的总计,底部是全体的合计值。今天我们会以不同方式重列这些数字,如表1-1所示。
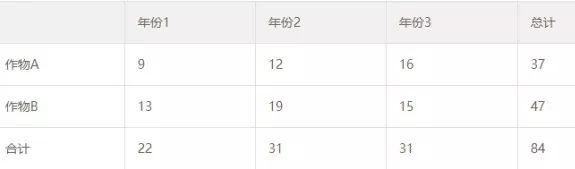
表1-1 苏美尔人泥板文书数字记录的列联表形式
统计分析没有保存下来,但可以确定其中不包括卡方检验。我们能说的是,这块泥板展现了那个时代的高水平统计智慧,但它没有离个别数据值走得太远:不仅表格主体展现了每年所有作物的计数,泥板背面还给出了这些计数依赖的原始数据、个体生产者的个数。甚至5000年前就有人认为公开原始数据是有用的!
数据统计的科学分析始于何时呢?算术平均值的使用是什么时候变为统计分析的一个正式组成部分的?真的没有在17世纪以前很久吗?为什么更早的时代没有用均值对天文、调查和经济进行组合观测?古代的均值数学是众所周知的。毕达哥拉斯学派在公元前280年已经了解均值的3种类型:算术平均值、几何平均值和调和平均值。公元1000年时,哲学家波伊修斯将均值数量提高到了至少10种,包括毕达哥拉斯的3种在内。不可否认,这些均值是在哲学意义下展开的,主要用于讨论线段的比例,以及音乐,而非用于数据总结。
我们当然可以期待,古希腊人、古罗马人或者古埃及人早在2000多年前日复一日的生活中,就已经摸索出对数据取均值。又或者他们并没有这样做,但可以肯定的是,早在1000年前的阿拉伯科学的杰出天文研究中,就可以找到均值。但是,哪怕只是想在这些来源中找到一个证据充分的例子,费尽心血广泛搜索之后,也总是免不了落空。
针对早期使用均值的历史,最坚定的搜索者是不屈不挠的研究者邱吉尔·艾森哈特,他在国家标准局度过了大部分职业生涯。数十年间,艾森哈特一直追踪均值的历史应用,并在1971年美国统计学会的主席演讲中总结了自己的研究。他热情洋溢地演讲了近2小时,但他发现的对于所有均值的相关使用工作、有证据表明使用均值的最早工作等,就是我前面提到过的由D. B. 和盖里布兰德做出的。艾森哈特发现,希帕克(大约公元前150年)以及托勒密(大约公元150年)对自己的统计方法默不作声,而阿尔-比鲁尼(大约公元1000年)则使用通过二分最小值和最大值之差产生的数——并不接近均值。均值很早就出现在印度的应用几何中,婆罗摩及多在公元628年写的一本关于测量的小册子中有这样的建议:处理挖掘问题时,要使用与挖掘平均规模相一致的长方体当作不规则挖掘量的近似值。
所有这些年代的历史证据表明,人们收集了许多类型的数据。某些情况下,不可避免需要概括。如果不使用平均值,人们需要做什么以进行总结呢?选定单个数字进行报告吗?我们先看几个例子,其中运用了类似于均值的概念,看完之后也许会更好地理解前统计时代人们是怎样看这些问题的。
修昔底德讲过一个关于攻城梯的故事,发生在公元前428年:
“一方为了达到敌人城墙的高度,需要制造一批梯子。因为城墙面向他们的一面粉刷不仔细,所以可以根据测量砖的层数计算城墙的高度。许多人同时数砖的层数,尽管有些人可能会数错,但大多数人会数对,尤其是多次计数之后。并且他们距离城墙也不远,完全可以看清楚。计算砖块的厚度后,就可以进一步推算梯子要求的长度了。”
修昔底德描述了所谓“众数”(mode,最频繁报告的值)的使用。因为计数过程缺失独立性的预期,众数并不非常精确。但如果报告非常接近,那它就和任何其他概括一样好。修昔底德并没有给出数据。
另一个很晚的例子来自16世纪早期,由雅各布·科贝尔在一本关于测量的图文并茂的书中提到。科贝尔说,那个时代土地测量的基本单位用一根16英尺长的木棒来确定。而且,当时的1英尺(foot)真的表示一只脚长,但是谁的脚呢?肯定不是国王的脚,也不是每次上台都会要求重新商定土地合约的新君主的脚。科贝尔说到的解决方案简单而优雅:在教堂礼拜之后留下16位市民代表(那时都是男性),他们鞋头对着鞋跟,站成一条线,这条线的长度就是那根16英尺木棒的长度。科贝尔的图片由他自己蚀刻,是一幅解释艺术的杰作(如图1-7所示)。

图1-7 科贝尔关于确定一根合法木棒的描述(Kobel 1522)
这真是一根“社区的”木棒!而且,这根木棒确定以后,又细分为16个相等的部分,每个部分都表示这根公共木棒中单只脚(即1英尺)的度量。从功能角度讲,这就是16个人的脚长的算术平均值,但“均值”这个术语在任何地方都未提及。
这两个例子相隔大约2000年,但它们都涉及一个共同问题:如何概括一组相似但不完全相同的测量。每种情况中,解决问题的方式反映了组合涉及的智力困难,这种困难到今天依然存在。在古代和中世纪,每当需要概括不同数据时,人们便选择个别的例子。修昔底德的故事中,被选中的个别例子是最主流的情形——众数。而在其他示例中,也可以选择那个最突出的例子;对数值数据而言,甚至可以选择最大的那个记录值。每个社会都希望宣扬它们最好的部分以代表整体社会,或者选择的情形也可以是基于不明确的理由而选择的“最佳”个体或值。天文学中,“最佳”值的选择可能反映了观测者的个人知识或观测的天文条件。但无论做了什么,这意味着要保持至少一个数据值的个别特征。科贝尔的记述中,重点是16只个体的脚,甚至可以在图片中认出那时的人们。无论如何,“由个体共同决定木棒长度”,这种思想是一个强有力的观点,因为这没有抛弃它们的个性。这是木棒合法性的关键,甚至也决定了单独的英尺标志是真正意义的平均。
1.3 平均人
到了19世纪,均值已经广泛运用于天文学与测地学。19世纪30年代,它还在社会中开辟了更广阔的应用空间。那时,比利时统计学家阿道夫·凯特勒开创了他所谓的“社会物理学”。为了可以在不同人群之间进行比较,他引入了“平均人”的概念。最初,凯特勒将这个概念当作人类种群之间的比较工具,或用来刻画单个种群随时间发生变化的情况。有了这一工具,便可以比较英国人和法国人的平均身高;也可以随着时间的变化记录某一年龄的平均身高,由此导出一条种群生长曲线。社会中不存在单个的“平均人”,每个种群都有自己的“平均人”。另外,凯特勒只关注男性,女性不在考虑之内。
19世纪40年代,一位批评家开始攻击这种思想。安东尼·奥古斯丁·库尔诺认为,“平均人”必然身体畸形:任何一个种群中,真正出现具有平均身高、体重和年龄的人的可能性非常低。库尔诺指出,对一组直角三角形相应的边进行平均再组成新的三角形,得到的图形不会是直角三角形(除非这些三角形都是彼此成比例的)。
另一位批评家是生理学家克劳德·伯纳德,他在1865年写下这样一段话:
“数学在生物学中的另一个频繁应用是平均值的使用,可以说这在医学和生理学中必然导致错误……如果我们收集一个人24小时内的尿液,混合起来分析平均值,那么得到的是对一种根本不存在的尿液的分析。禁食时的尿液不同于消化时的尿液。一位生理学家发明了诸如此类的一个惊人实例,他选择了一座各国人都会经过的火车站,从小便池取出尿液,并相信自己能据此提出一份针对普通欧洲人的尿液分析!”
这种批评没有吓倒凯特勒,他坚称“平均人”可以作为一组人中的一个“典型”样本。这个样本抓住了“类型”,可以作为一组人的代表用于比较分析。因此,这个概念高度成功并经常受到滥用。“平均人”及其衍生概念发展出一套理论体系,使一些物理科学方法得以运用于社会科学。
19世纪70年代,弗朗西斯·高尔顿分析非定量数据时进一步采用了均值的思想。他花费大把时间和精力,根据肖像的组合构建所谓的“一般性肖像”。其中,通过叠加一组中若干成员的图像,本质上生成了这一组中男士或女士的平均图像(如图1-8所示)。高尔顿发现,从姐妹和其他家庭成员之间的面容相似之处可以提取家族特征。他也用了其他群组进行实验,生成了亚历山大大帝的勋章组合(希望能揭示出更逼真的画像),以及罪犯群组和相同疾病的患者群组。

图1-8 高尔顿的一些复合肖像(Galton 1883)
高尔顿合成照片时施加了一些约束,他很清楚这种一般性肖像的局限性。正如他自己的解释:“没有哪位统计学家会梦想着组合那些同属一个种群但没有共同的中心聚集目标的对象。我们不应再用异质元素组合一般性肖像,如果这样做,结果会很可怕而且毫无意义。”他的一些追随者并没有这样谨慎。一位名叫拉斐尔·庞佩利的美国科学家于1884年4月参加美国国家科学院会议时为一些与会者拍摄了照片,第二年,他发表了图片合成的结果。图1-9是其中一个例子,这是由12位数学家(这个称呼在当时还包括天文学家和物理学家)的肖像叠加生成的“平均”数学家的合成图片。除了这张图片里的人看起来和高尔顿合成的那些罪犯一样阴险之外,我们还会注意到,将胡子剃干净的人、一些络腮胡子的人以及更多一些蓄小胡子的人的肖像组合后,产生的类型看起来更像是某个一周没刮胡子的人。

图1-9 庞佩利的12位数学家的复合肖像(Pumpelly 1885)
1.4 聚合与地球的形状
到18世纪中期,统计聚合的运用已经扩展至许多场合,其测量是在迥异环境中做出的。事实上,这也是环境使然。一个最简单的例子是18世纪关于地球形状的研究。初步估计,地球是一个球体;但随着航海和天文学精度的增加,问题随之而来。艾萨克·牛顿出于动态角度的考虑,提出地球是个略扁的球体(在两极处压缩,在赤道处膨胀)。法国天文学家多美尼科·卡西尼则认为,地球是一个扁长的球体——在两极拉长。要想解决这个问题,可以比较在不同纬度的地面做出的测量。从赤道到北极的几个不同地点,可以测量出一个相对较短的弧长——A。这条弧的方向垂直于赤道,是由北极到赤道的所谓子午线1/4圆的一段。可以先测量沿着地面的弧长,再除以两个端点的纬度差,结果是单位纬度的弧长。纬度可通过仪器观测北极星与水平线的夹角测得。观察这个1°的弧是如何随着到赤道的距离变动的,即可解决这个问题。
椭圆积分给出了球体的弧长与纬度之间的关系,但一个简单公式就足以计算短距离(而且实际上,只有比较短的距离才可以测量)。令A = 沿着地面测量的1°弧长,L = 弧中点的纬度——这也是通过观测北极星决定的,则赤道有L = 0°,北极有L = 90°。因此,A = z + ysin2L可以良好地近似每个测量的短弧度:
如果地球是一个完美的球体,那么y = 0并且所有的1°弧具有相同的长度z。
如果地球是扁平的(牛顿),那么y > 0并且弧长在赤道为z(sin20° = 0),而在北极点变为z + y(sin290° = 1)。
如果地球是扁长的(卡西尼),那么y < 0。
y 的值可以认为是一种极地超额(如果值为负,那就是不足)。“椭圆率”(从球形形状出发的偏离测量)可以近似地计算为e = y/3z,一个稍微改进的近似计算式是e = y/(3z + 2y)(有时会用到)。
计算需要数据。这个问题听起来很容易:测量任意两个度数,也许一个在赤道,另一个在罗马附近。那个年代的长度采用“突阿斯”(Toise)计量,是“米”制单位出现之前的单位,一突阿斯约合6.39英尺1。1°的纬度大约有70英里2那么长,实地测量太长、太难,因此需要测量一个短的距离再做推断。1736年,皮埃尔·布格率领一个法国考察队,在今天厄瓜多尔的基多附近进行测量,那里可以在南北方向上测量接近赤道的较长距离。他测出的长度是A = 56 751突阿斯以及sin2 L = 0。1750年,耶稣会学者鲁杰罗·朱塞佩·博斯科维奇发现罗马附近的测量值是A = 56 979突阿斯以及sin2 L = 0.4648。这给出了两个方程:
1约为1.95米。——译者注
2约112.7千米。——译者注
这些方程很容易解出,得到z = 56 751和y = 228/0.4648 = 490.5,以及e = 490.5/(3·56 751) = 1/347,那时人们喜欢这么写计算结果。
但在18世纪50年代末,到博斯科维奇写出关于这个问题的报告为止,已经存在5个而不是2个获得肯定的弧长记录:基多(In America)、罗马(In Italia)、巴黎(In Gallia)、拉普兰(In Lapponia)以及一路南下直到非洲最南端的好望角(Ad Prom. B. S.)。其中任何两个都会给出一个结果,因此博斯科维奇面临数据的窘境:共有10个解,且它们各不相同(如图1-10和图1-11所示)。
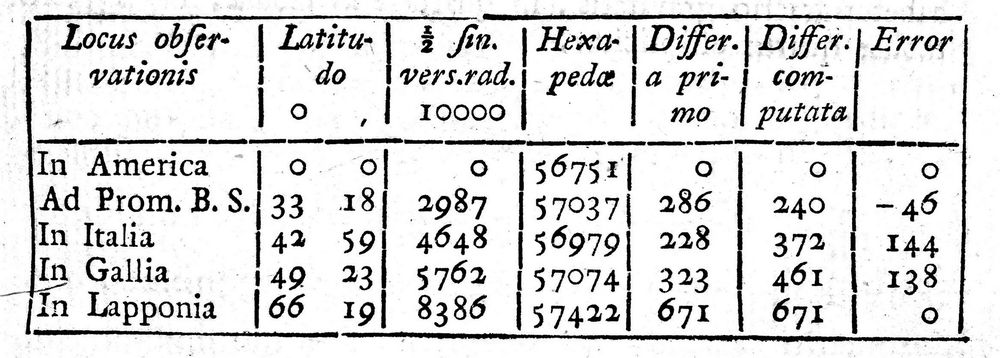
图1-10 博斯科维奇的5个弧长数据。各列(用我们的记号)对 i = 1~5的每个弧给出了维度Li(用°表示)、sin2 Li [ = 1/2·(1 - cosLi ) = 1/2·versin Li ]、Ai(hexapedae,用突阿斯表示的长度)、Ai - A1的差、使用弧1和5的解的差,以及这些差之间的差。好望角的sin2 L值应该是3014,而不是2987(参见Boscovich 1757)
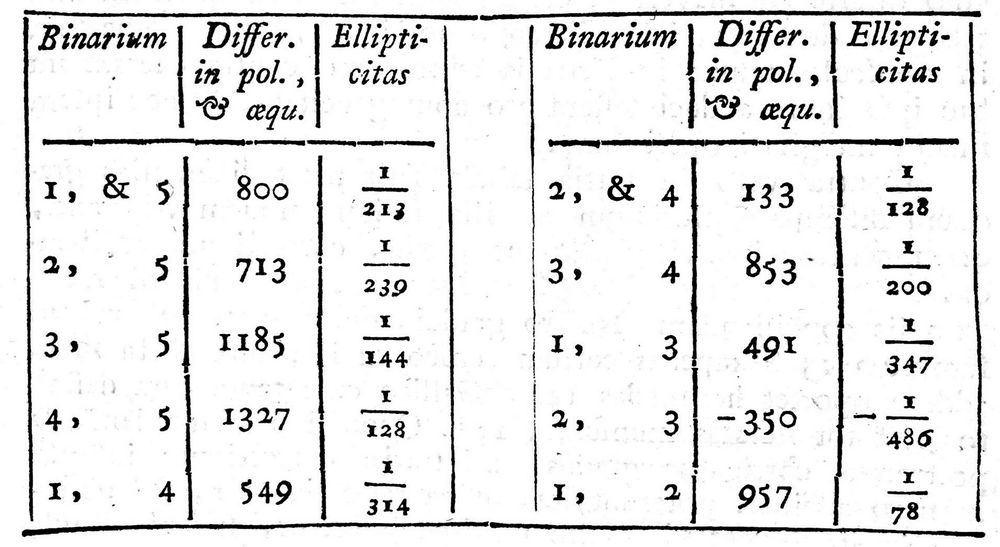
图1-11 博斯科维奇计算的10对弧,对应每对弧都给出极地超额y以及椭圆率e = 3y/z。(2, 4)和(1, 3)的椭圆率印刷有误,应该是1/1282和1/178。(1, 4)的数字有误,应该是560和1/304(Boscovich 1757)
博斯科维奇现在进退两难。5个测量的弧不一致,他应该随便选择其中一对并接受这个结果吗?恰恰相反,他创造了一种真正新颖的聚合方法,给出了综合5种结果后的客观答案。博斯科维奇认为,数据中最不可靠的要素就是弧的测量。这些弧需要在极端困难的环境下仔细测量,从巴黎和罗马附近的森林到非洲之角,再到拉普兰的冰冻苔原,以及世界另一端的厄瓜多尔平原。而且,几乎不可能为了进行检查而重复这些测量。根据方程A = z + ysin2L,博斯科维奇进行了如下推理:z 和y 的每个选择都隐含着A的一个对应值,并且这个值和观测值的差可以认为是一种调整,需要对观测的A进行这种调整以使测量匹配方程。所有可能的z 和y中,隐含着“寻找调整绝对值总和的最小值”的目的,还假定选出的z 和y 与各个A的均值和各个L 的均值相一致。博斯科维奇给出了一种聪明的算法求解最佳值,就是现在所谓“线性规划问题”的早期实例。对于这5个弧,根据他的方法求出的答案为:z = 56 751、y = 692、e = 1/246。
接下来的半个世纪,人们提出了多种方法,通过某种聚合形式整合不同条件下不一致的测量。最成功的方法是最小二乘法,它在形式上是观测的加权平均,而优势是很容易扩展为其他更复杂的形式,从而决定多个未知量。1805年,阿德里安-玛丽·勒让德首次公布了这种方法——在一本解释如何确定彗星轨道的书中。勒让德给出了说明测定地球椭圆率的例子,采用的测量是法国大革命之后定义“米”的长度的方法。这些数据给出的椭圆率是1/148,这个数值很大。但由于弧的范围更短(只有10°的纬度,全在法国之内),并且与其他值不一致,因此人们认为它还不如早期从赤道到拉普兰范围内的测量。所以,最终的“米”是基于不同考察的混合值而决定的。
聚合具有多种形式——从简单的加总到不透明抽检的现代算法。但是,使用概括取代完全枚举个体观测的原则,和通过选择性地丢弃信息以获取信息的原则,都是一脉相承的。
统计学七支柱

遇见数学, 遇见更精彩的自己
非常感谢您的关注和支持!



