可以这样理解视觉Transformer模型中patch交互的关系
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
01
研究问题
随着计算机视觉领域的不断发展,基础视觉任务研究中受自然语言处理(NLP)的模型结构设计(Transformer-based model)的启发,视觉任务与Transformer网络模型结构相结合,通过引入自注意力机制等结构来探索和优化Transformer网络在视觉任务当中的应用,在目标检测、分割和跟踪等多项视觉任务中获得比较有竞争力的优势。同时,针对基础视觉任务的研究中,引入可解释性分析能够通过多个角度对现有模型形成更加深层的理解,能够促使研究人员进一步探索其中有效的建模过程。
然而,现有有关Vision Transformer的相关工作仍然存在三个问题:
模型缺乏可解释性。现有的方法(e.g., ViT)受自然语言处理领域工作的启发,只关注了如何把视觉任务和Transformer网络相结合,但忽略了模型计算中的可解释性问题。
冗余的Patch之间的交互关系。Self-attention 机制通过patch-wise之间的long-range关系构建注意力关系,形成了冗余的计算代价。
启发式手工预设Patch交互区域。目前相关工作利用先验信息的启发式设定限定patch交互范围(Window-based,Range-based和Region-based)。视觉任务中patch-wise的交互应该与图像语义有所关联,然而在patch交互中缺乏考虑patch所包含的语义信息;同时,现有技术缺乏考虑自适应区域设计问题,多以经验式参数作为窗口约束条件。
针对以上三个问题,这篇近期来源arxiv文章提出了针对ViT模型的可视化分析和理解工作(Visualizing and Understanding Patch Interactions in Vision Transformer)。

论文: https://arxiv.org/abs/2203.05922
02
方法
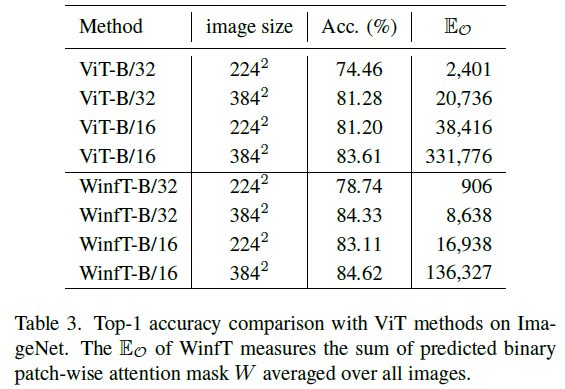
针对ViT模型,作者首先对patch-wise attention进行可视化观察、数值分析等方法量化patch之间的交互。接着,利用patch之间的交互量化转为patch交互关系,其中包括centain connections 和 indiscriminative connections。同时,基于patch之间的交互关系计算出当前patch的responsive field。最后,将当前patch的responsive field作为patch交互区域(Window)。此外,通过分析得到的Window区域作为监督信号设计了一个Window-free Transformer(WinfT)模型,通过实验(Table.3)进一步验证了可视化分析和理解的结论有效性。基于WinfT实验验证结果,可以有趣的发现模型在patch划分大小分别为16X16和32X32中,自适应window区域限制patch交互的分类任务结果几乎是相同的(84.33% vs 84.62%)。可视化分析和实验验证的结果对于未来Transformer-based 模型设计具有指导意义。
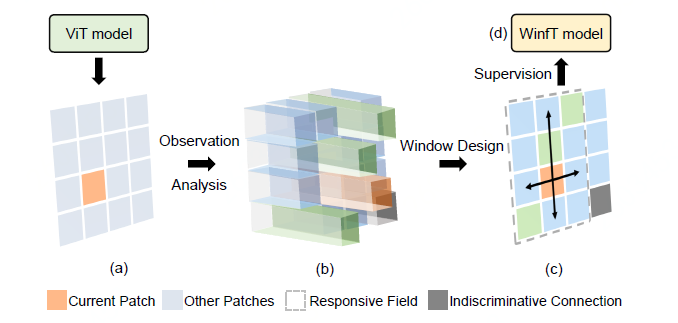
方法流程示意图
Patch交互关系的差异?
作者随机选择不同patch组合(inner-object 和 outer-object),量化不同的patch的交互关系,实验证明具有不同语义信息的patch在交互过程中是存在较大的差异。
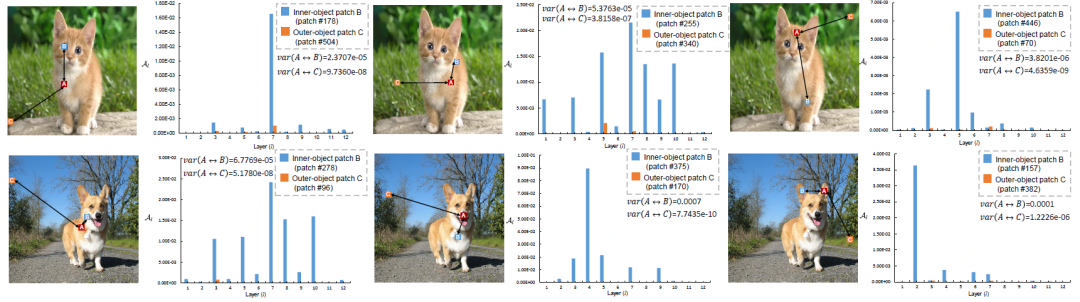
量化分析 inner-object patch 和 outer-object patch.
通过这样的差异现象,作者从不确定性分析的角度进一步表征patch交互的关系:
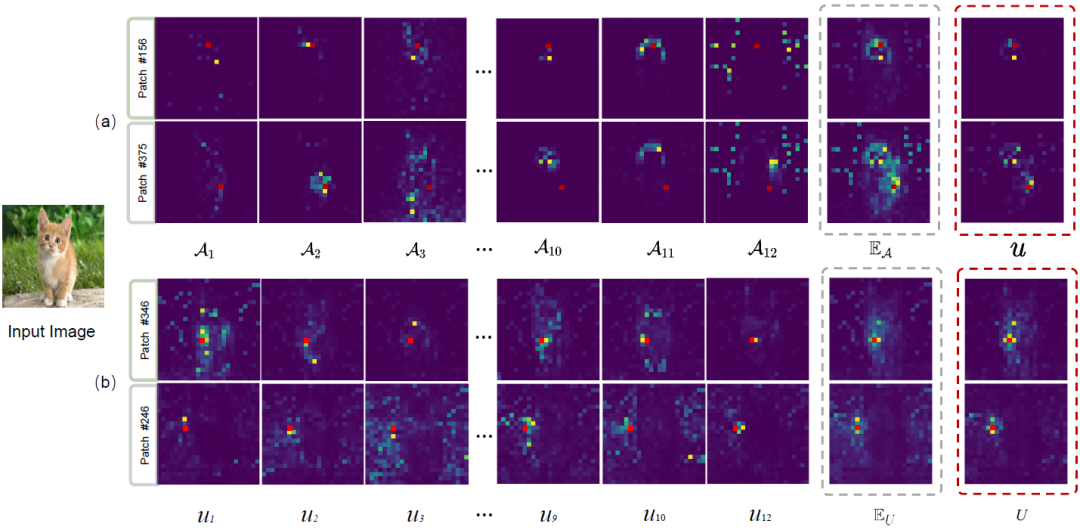
量化patch交互关系能做什么?
1) Adaptive attention window design
作者首先通过量化patch交互的不确定性关系,通过阈值选择的交互关系作为可靠性较强的patch连接。接着,利用筛选后的交互连接关系,计算当前patch与其交互可靠性较强的patch中在四个方向的极值,最终转换为当前patch的交互窗口区域。
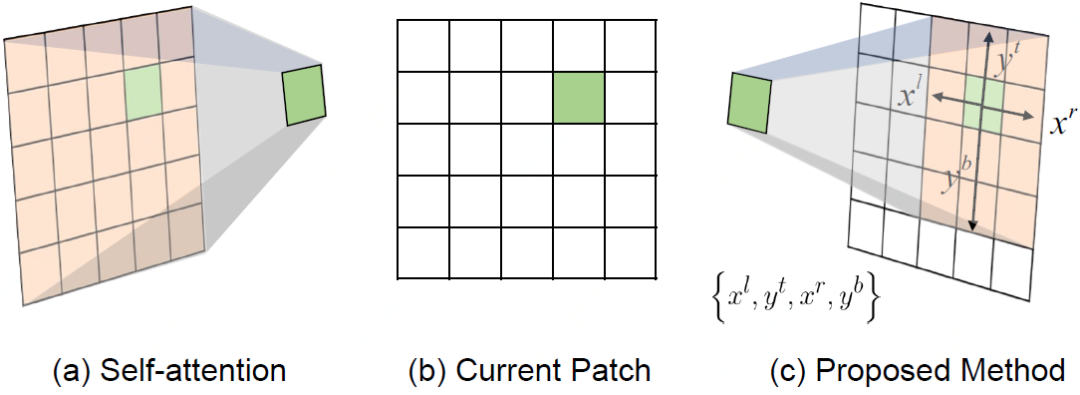
自适应窗口设计
2) Indiscriminative patch
在设计自适应窗口中,作者发现存在一些patch与几乎所有的patch之间都交互关系,通过数值分析后发现这样的patch多数存在于背景当中。此外,提供对应的实验验证去除掉Indiscriminative patch之间的连接,能够进一步提升分类任务中的性能。
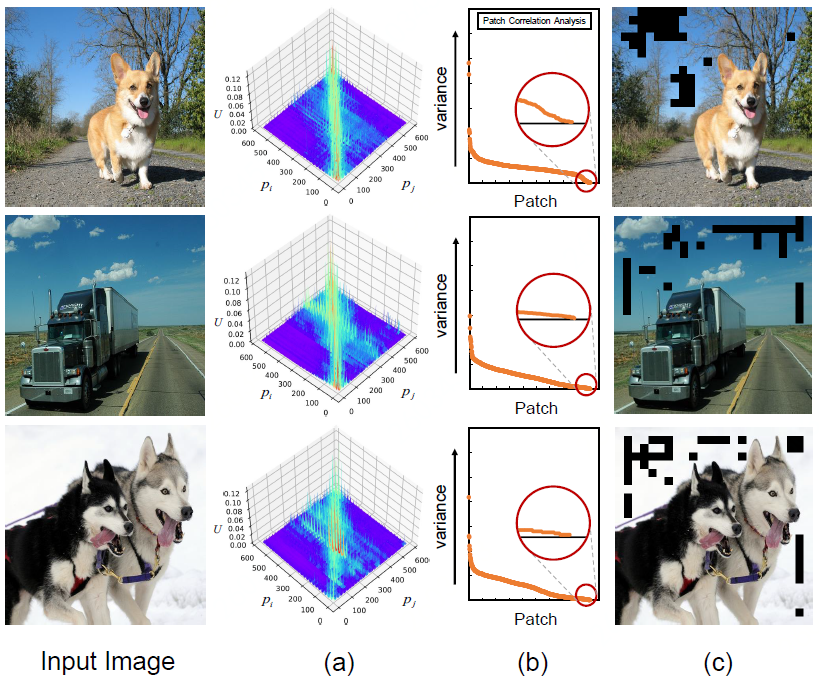
分析Indiscriminative patch
作者还提供了不同阈值来可视化Indiscriminative patch:

不同阈值去除Indiscriminative patch数量效果图
3) Responsive field analysis
通过前两个部分证明了自适应窗口设计的有效性,作者结合光流、窗口交互趋势等方法对交互窗口形成的responsive field的交互趋势和交互窗口的大小进行分析:
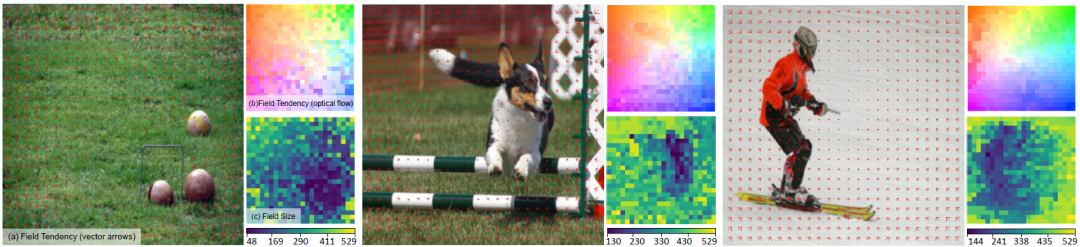
Responsive field analysis例子
其中趋势分析的计算流程为:
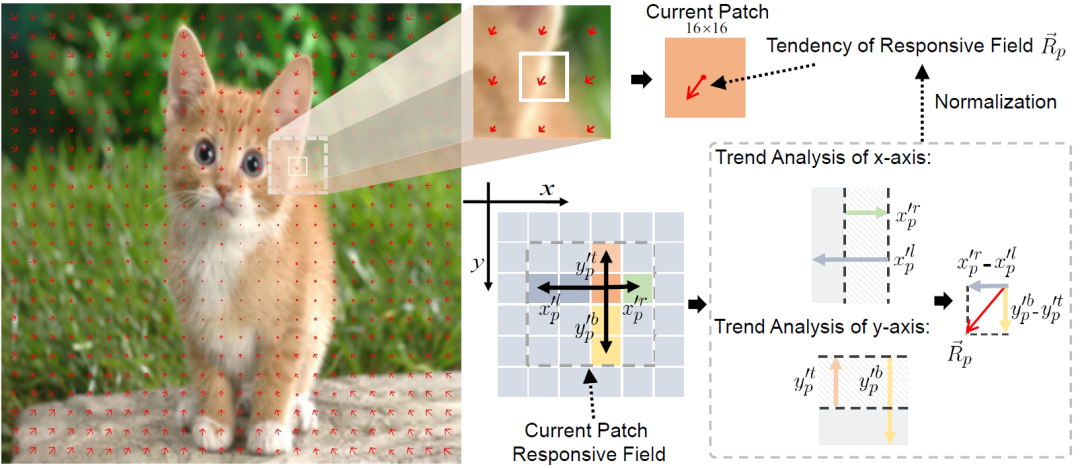
分析Responsive field的tendency示意图
Window-free Transformer (WinfT)
基于patch交互分析为理解Vision Transformer模型提供了一种新的补充视角。基于可视化观察和分析,作者提出了一个基于Window-free的Transformer结构,通过在训练期间引入patch-wise的responsive field作为交互窗口指导监督模型训练,相比ViT有较大幅度的提升。
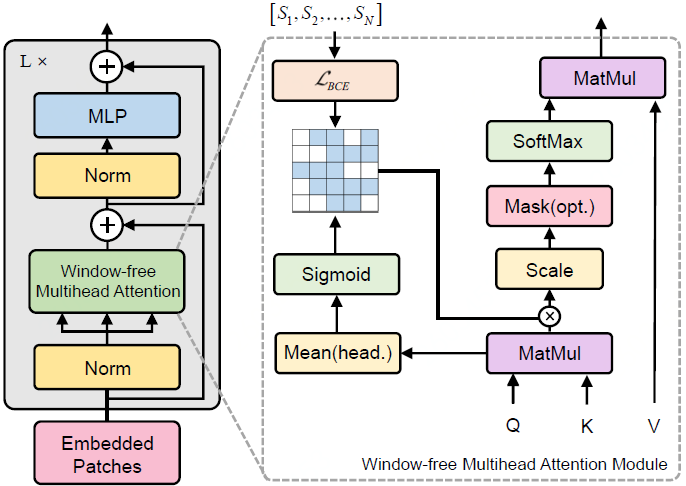
WIndow-free Multihead Attention示意图
WinfT实验在ImageNet分类任务和Fine-grained任务(CUB)中验证其方法的有效性,实验结果也进一步证明了可视化分析和对ViT模型的分析理解是有效的。
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看





