数据集|更大的行人重识别测试集 Market-1501+500k
极市平台是专业的视觉算法开发和分发平台,加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者:交大第一carry
来源:知乎
Market-1501 是目前常用的行人重识别数据集,包含12,936张训练图像(来自751个不同的人),和 19,732张测试图像(来自另外750个不同的人)。
可以说,Market的训练和测试集没有overlap的类别(ID)。但是现有方法已经把performance刷的很高了,可以详见以下的state-of-the-art 方法链接。
liangzheng.org/Project/
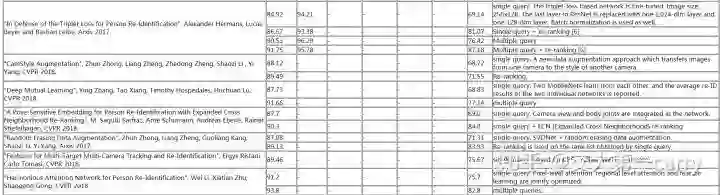
Market-1501的Rank-1 已经达到90+了,那么是不是测试集太小,难度太低了呢?
其实在Market-1501发表的时候,就还提出了 Market-1501+500k 来增大测试集。
什么是Market-1501+500k?
Market-1501+500k 的设计其实十分简单。增加候选的图像。
原始的候选图片库19,732(candidate image pool) 毕竟还是有限,所以加了500k的数据集。这500k的数据是采集自同一天下午清华大学。默认和test、train集都没有overlap的人。所以全部认为成干扰来加入候选图片库,来评估。
增加后的测试集有 519,732张图像。问题难度增加了。
目前的state-of-the-art methods:
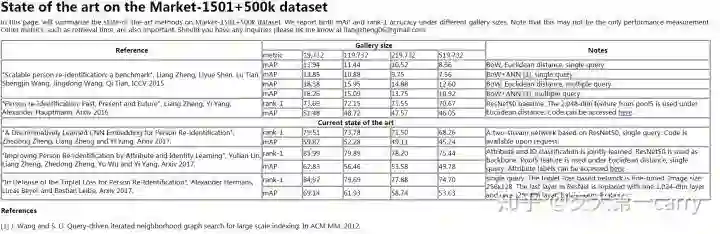
可以看到,随着测试数据的增加,reid的效果都显著下降了。
如triplet方法 rank-1 从84.92% 降到了 74.76%
其实现在大家都会议论 行人重识别的模型是不是过拟合Market了,不妨试试Market+500k。
Reference:
Zheng, Liang, et al. "Scalable person re-identification: A benchmark."Proceedings of the IEEE International Conference on Computer Vision. 2015.
文首图片来自arxiv.org/pdf/1611.0566
*推荐文章*
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~





