陈丹琦组掩蔽语言模型研究引争议:15%掩蔽率不是最佳,但40%站得住脚吗?

来源:机器之心
本文约3133字,建议阅读6分钟
本文介
绍了陈丹琦团队就公布的一项备受质疑的新研究。

自BERT以来,大多数人坚持的模型训练15% mask rate惯例被打破了?
前段时间,斯隆基金会公布了2022 年度斯隆研究奖的获奖者,陈丹琦、方飞、顾全全、李博等多位研究者获得了计算机科学领域的奖项。
在获奖后不久,陈丹琦所在的团队就公布了一项新研究。但和陈丹琦之前广受赞誉的各项工作不同,这一新作受到了诸多质疑。
这个工作是关于掩蔽语言建模( masked language modeling,MLM)的。掩蔽语言模型通常使用15%的掩蔽率,因为大家发现,更高的掩蔽率将不能提供足够的上下文来学习良好的表示,而更低的掩蔽率将大幅提高训练成本。但陈丹琦等人却发现,如果将掩蔽率提高到40%,性能可以超过15%的基线;如果提高到80%,大部分性能仍能得以保留,这是在下游任务上进行微调测得的结果。
由于和不少人自身实验的结果并不符合,而且没有开源代码,所以这一研究在推特、知乎等平台上引起了很大的争议。
有人认为,这就是一个调参的结果,没有理论依据,「黑盒的层面很多」,能不能复现也不好说。但也有人认为,如果严格按照论文的设置,论文的结果能够复现,就相当于「有人事先把最优参数调出来了」,这也没什么不好。而且,这篇论文还能「启发大家重新反思MLM的使用」,所以算得上是一个有价值的工作。
接下来,我们就一起来看下这项工作。
这篇文章写了什么
几个月前,何恺明的Masked Autoencoders成为了计算机视觉的热门,其遮蔽80%还能脑补原图的重建能力惊为天人。何恺明等人在其论文中展望了预训练大模型在CV领域的前景,而在NLP领域里,人们训练算法通常使用的遮蔽比例是15%。在陈丹琦的新研究中,这一数字被显著提高了。

论文链接:https://arxiv.org/abs/2202.08005
预训练语言模型已经改变了自然语言处理领域的格局。大型语言模型经过巨量文本数据的训练,可获得丰富多样的语言表示能力。与总是预测序列中下一个token的自回归模型相比,像 BERT 这样的掩蔽语言模型(MLM)会根据上下文预测输入token的掩蔽子集,由于具有双向性质,此方法效果通常更佳。
此种方法是把模型限制为只掩蔽一小部分token内容开始进行学习的,通常为每序列15%。15%的数字反映这样一个假设——若掩蔽太多文本,则模型无法很好地学习表示,这一思路被BERT之后的研究普遍采用。同时,仅对 15% 的序列进行预测已被视为对 MLM 进行有效预训练的限制。
在普林斯顿大学陈丹琦等人的研究中,作者发现了与此前结论完全不同的情况:在有效的预训练方案下,他们可以掩蔽 40-50% 的输入文本,并获得比默认的 15% 更好的下游性能。
下表展示了掩蔽 80%、40%和15% 的情况下,预训练模型的下游性能。在掩蔽率为80%的条件下,大多数上下文内容已变得不可见,但相比15%掩蔽,模型仍能学习到接近的预训练表示效果。这挑战了人们关于掩蔽率的直觉,并提出了模型如何从高掩蔽率中受益的问题。

沿着这一方向,作者建议将掩蔽率分解为两个因素:损坏率(corruption rate,有多少上下文被掩蔽)和预测率(prediction rate,模型预测的token有多少)。在 MLM 中,损坏率和预测率都与掩蔽率相同。然而,这两个因素具有相反的效果:虽然较高的预测率会产生更多的训练信号并有利于优化,但较高的损坏率会使学习问题在较少上下文的情况下更具挑战性。
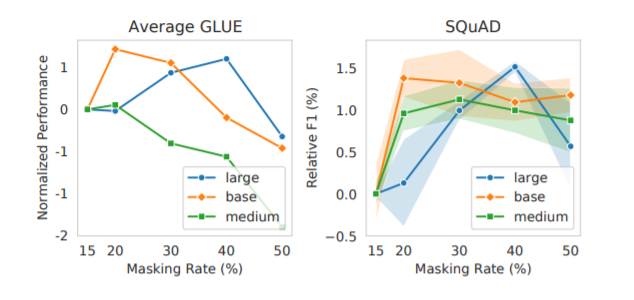
为独立研究这两个因素,作者设计了消融实验来分离损坏和预测。实验证明,模型可受益于更高的预测率,更高的损坏率则不然。更高的预测率所带来的好处能否掩盖更高的损坏率所带来的负面影响,决定了模型能否在更高的掩蔽率下表现得更好。研究者还发现,拥有处理更高损坏率的更大的模型表现出了更高的最佳掩蔽率。
受这一结果启发,作者在复杂情况下考虑了更高的掩蔽率,例如span掩蔽和 PMI 掩蔽。当以 15% 的掩蔽率进行评估时,这些方法被证明优于简单的均匀掩蔽(uniform masking),但均匀掩蔽在其各自的最佳掩蔽率下与复杂的掩蔽基线相比具有竞争力。本文作者表示,他们提出的新的预测率-损坏率框架也为 BERT 基于原始或随机token(80-10-10 策略)的预测实践提供了新的思路——如果没有它,模型通常会表现得更好。
作者在讨论中表示,在 MLM 中采用更高的掩蔽率会带来更好的性能,尤其是在资源有限的环境中。从输入中移除掩蔽token,或解耦损坏率和预测率,有望进一步加速预训练。
具体来说,这项研究的贡献包括:
研究证明,训练具有较高掩蔽率的掩蔽语言模型是可以成功的。例如,具有高效预训练方法的大模型在掩蔽率为40%的情况下比15%的情况下表现更好;
研究者建议将掩蔽率分解为损坏率和预测率,这两个相反的要素分别影响任务难度和训练信号,研究者使用该框架表明,较大的模型有更高的最优掩蔽率,并且只使用[ MASK ]token掩蔽优于80-10-10策略;
研究证明,在高掩蔽率下,与span掩蔽和PMI掩蔽等更高级的掩蔽方案相比,均匀掩蔽更具竞争力。
掩蔽语言模型通常使用15%的掩蔽率,研究者一般认为更高的掩蔽率会导致用来学习良好表征的上下文不足,而更低的掩蔽率则会导致训练成本太高。
在这项研究中,研究者发现高达40%的掩蔽率可以超过15%的baseline,即使是80%的掩蔽率也可以保持大部分性能,这可以通过对下游任务进行微调来衡量。
实验结果
在消融实验中研究者发现,增加掩蔽率有两方面影响:1、更高比例的输入token被损坏,减少了上下文的大小并创建了一个更困难的任务;2、模型会执行更多的预测,这有利于训练。研究者观察到,较大的模型特别适合更高的掩蔽率,因为大模型本身具备更高的能力来执行困难任务。进一步地,研究者将该发现与复杂的掩蔽方案结合起来,比如span掩蔽和PMI掩蔽,以及BERT的80-10-10策略,并发现使用[MASK]替代的简单均匀掩蔽在更高的掩蔽率下具备竞争力。



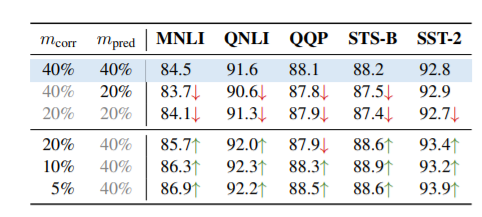
表3:损坏率 vs. 预测率。以40%的掩蔽作为基线,分离m_corr和m_pred,并分别对它们进行操作。趋势是明确的:更高的预测率是有益的,但更高的损坏率是有害的。
未来
研究者进一步讨论了其他语言模型中的掩蔽率问题,除MLM之外,还有其他被广泛用于NLP任务的预训练方案,包括自回归语言模型(Radford et al., 2018; Brown et al., 2020) 和sequence-to-sequence语言模型(Raffel et al., 2020; Lewis et al., 2020)。类似地,sequence-to-sequence语言模型以一定的掩蔽率损坏文本,并用自回归的方式预测掩蔽文本。T5(Raffel et al., 2020)也采用了15%的掩蔽率。研究者准备扩大研究,比如研究文本到文本模型,并探讨掩蔽率和不同类型解码器之间的相互作用。





