Facebook视频「整容」滤镜助你逃避人脸识别:熟人认得出,但AI不能
选自research.fb
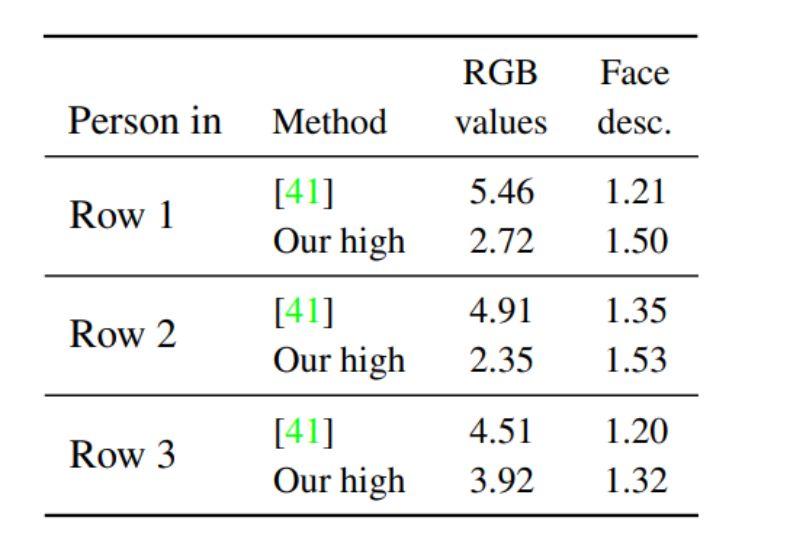
人脸识别正得到越来越广泛的应用,但有时我们希望在网上发布自己视频的同时又不被各种人脸识别软件识别出来。近日,Facebook AI 研究所提出了一种可以让你在人脸识别软件面前「隐身」的方法。这种方法会对视频中的人物面部特征进行修改,修改后的人脸与原人物看起来高度相似,但 AI 却识别不出修改后的视频人物,效果堪比整容。



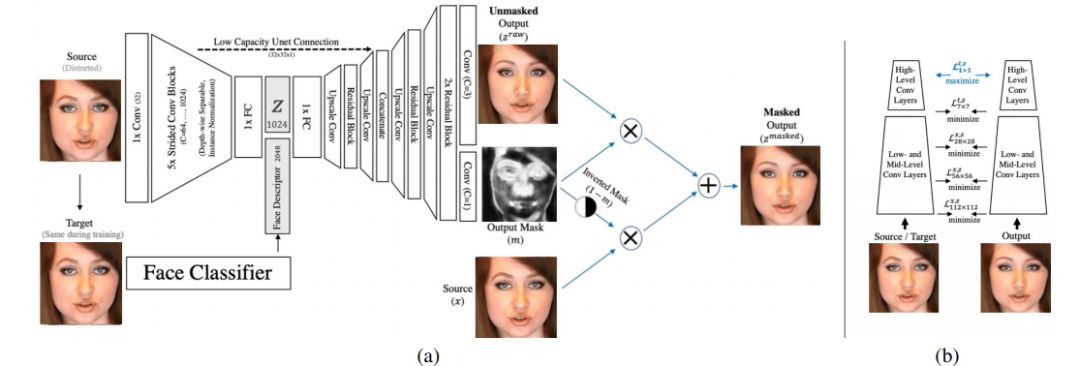

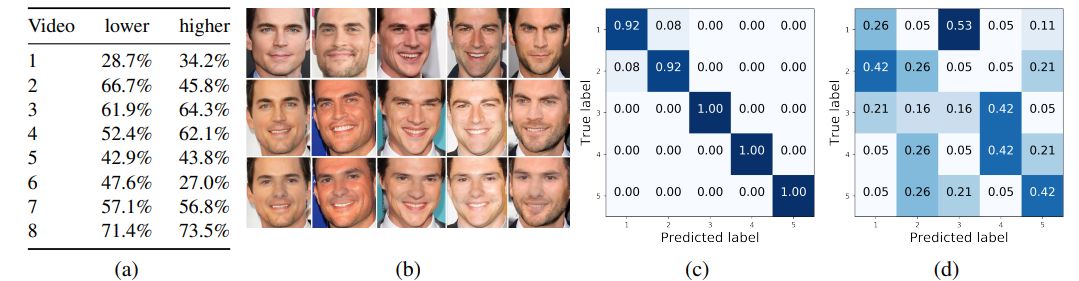
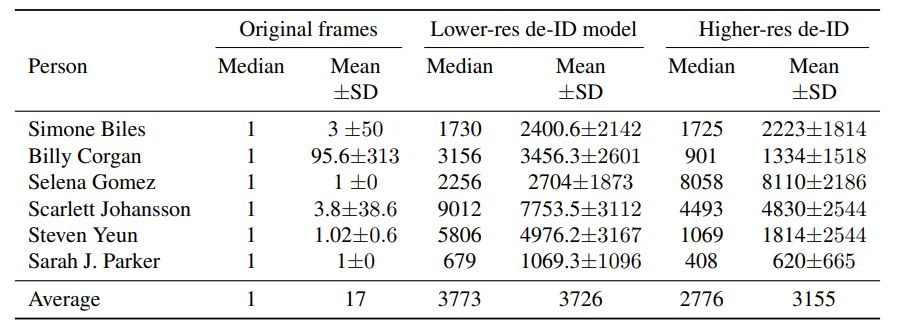
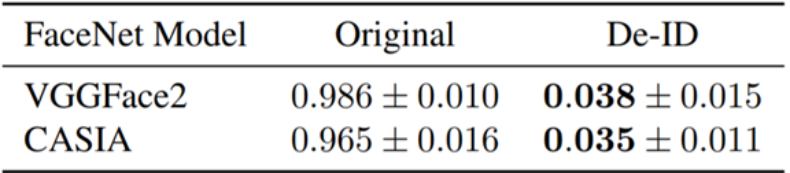





登录查看更多
相关内容

专知会员服务
38+阅读 · 2019年12月26日



相关VIP内容
专知会员服务
38+阅读 · 2019年12月26日
相关资讯
相关论文