弹性并行查询深度剖析

背景
概念

传统的MPP架构是计算与存储耦合的,查询的子任务要下发到数据所在的节点完成本地化计算,再通过后续分发,到上层节点中完成聚合计算
PolarDB基于云上基础设施实现了计存分离,任何节点都可以看到全量数据,这使极致的弹性和灵活的调度成为可能,例如实例的规格可以根据负载的需求即时或定时升/降,而无需做任何数据迁移,同时无状态的计算任务理论上可以分发到任意节点执行
优势
100%兼容性
极致性价比
性价比来源于四个方面:
数据:复用了底层同一套业务数据做in-place分析加速,而无需单独维护一套额外副本,没有附加的存储成本
计算:基于原生的执行引擎实现,购买实例后默认的读写集群即可开启多机并行功能,除非需要加入更多节点完成计算,否则并无额外计算成本。
调度:通过自适应调度来提高资源利用率,举个简单的例子:一个查询在单节点并行时需要4个线程完成,但当前节点只剩3个线程资源,而其他节点仍有空闲,则可以通过跨机调度分发一个计算任务,利用闲置资源保证加速效果。
弹性:随实例规格的弹性变化实时调整并行策略,在"降本"的同时仍然保证"增效"能力
极低运维成本
实时在线分析
灵活的应用模式
适用场景
海量数据分析场景
即使是最大88核的规格,处理能力仍是有上限的,而且如果数据量到达TB级别,这个规格应对分析查询仍是不够的,只有扩展出去才能利用更大的总体资源
即使单机资源没有遇到瓶颈(多核大内存),在数据库内核中会存在很多共享资源(page hash/readview/pages...),查询中的worker线程会并发访问这些资源,导致并发控制带来的消耗,查询性能无法很好的线性扩展。但如果worker线程分布到多个节点中,争抢会降低很多,仍然可以保证良好的加速比
资源负载不均衡场景
如果RO节点过热使得查询执行过慢,可能造成主节点无法purge undo log导致磁盘空间膨胀。
-
如果RO节点过热导致redo apply过慢,会导致rw节点无法刷脏降低主节点的写吞吐性能。
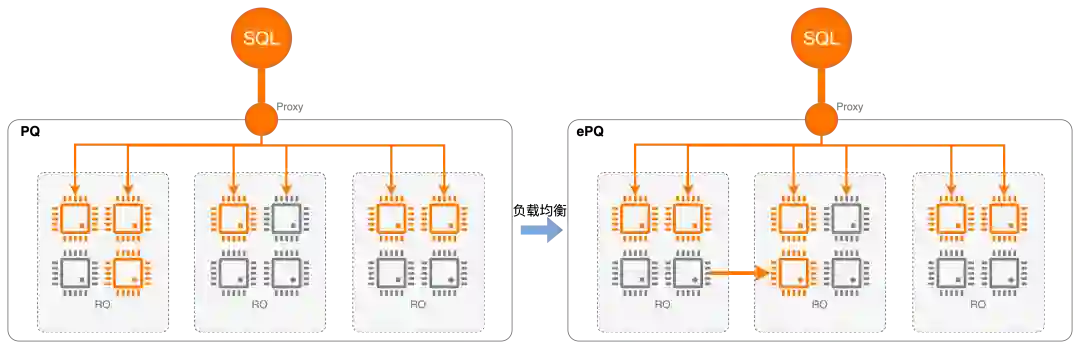
弹性计算场景

在离线业务混合场景

技术实现
内核架构
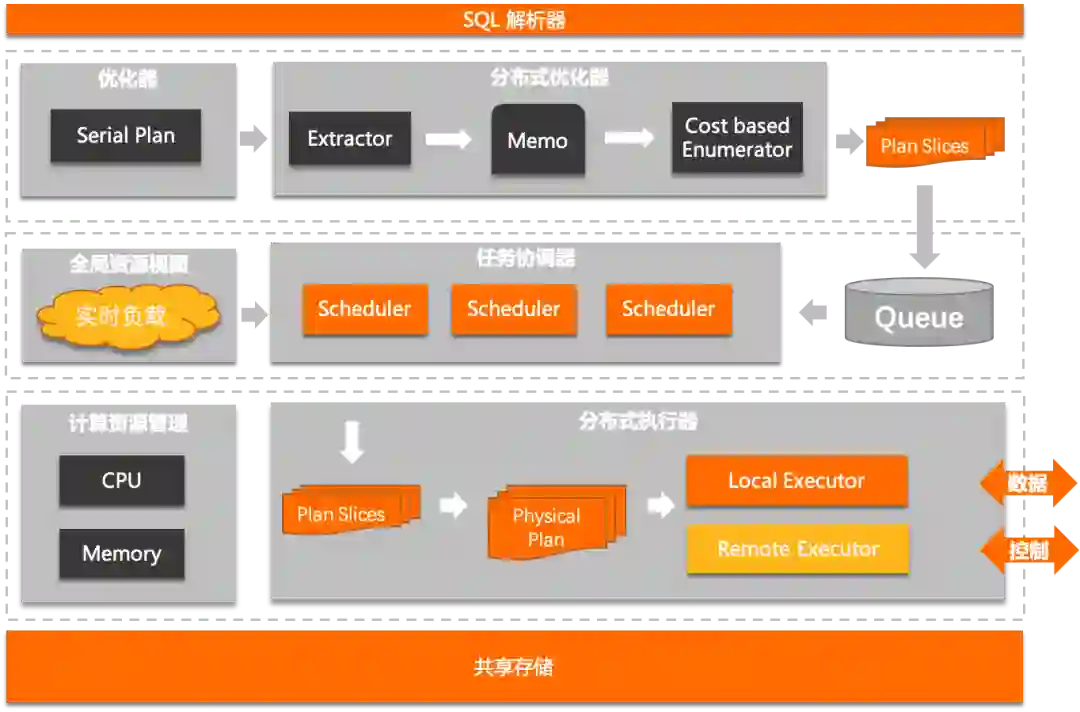
分布式优化器
如果全局资源均不充足,禁止使用并行
如果查询代价或表扫描行数超过阈值,等比例扩展单机并行度到多机,更充分利用多核资源加速计算
-
否则保持现有并行度不变,并在枚举计划空间中,考虑跨节点的数据分发代价
并行执行策略
semijoin-materialization并行物化
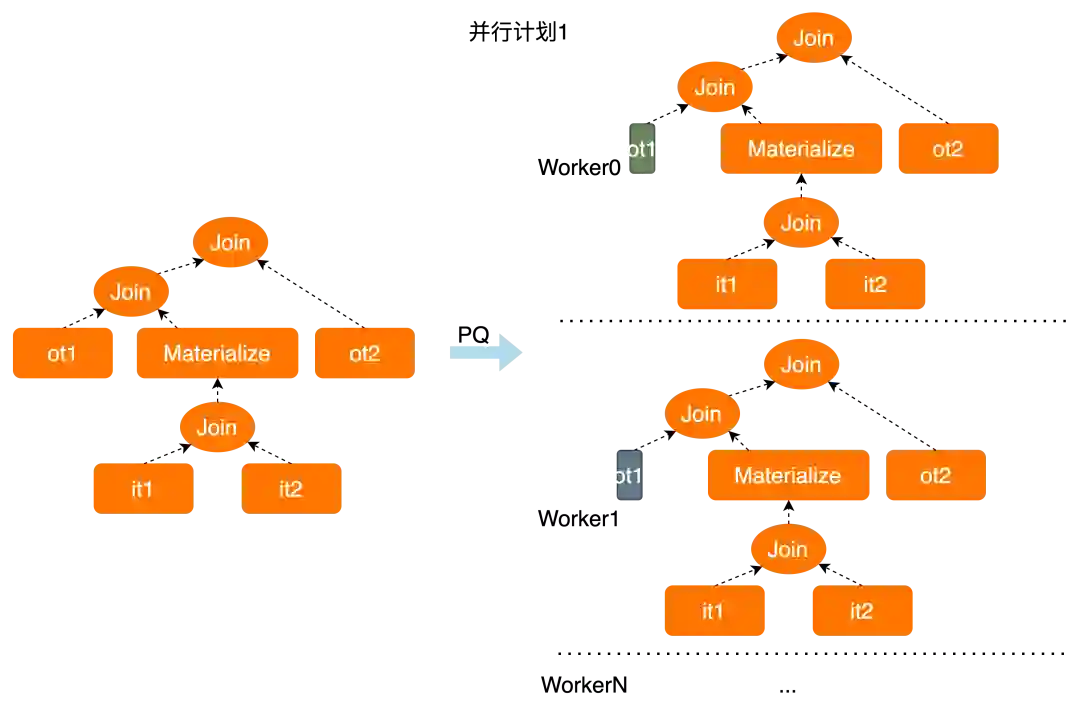
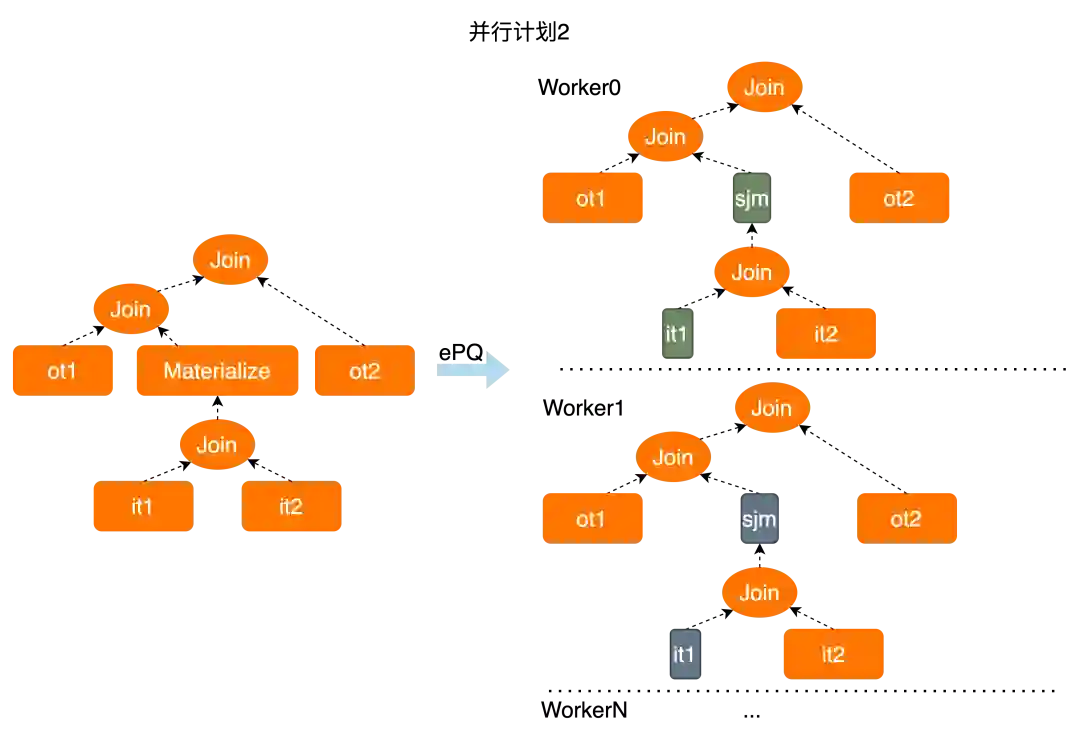
derived table/cte并行物化
节点间交互
控制通道
数据通道

端口复用
缓冲队列
异步设计
实现proxy模式的数据交互协议,多路数据复用同一连接,以应对更大规模的并行(e.g 参考Deepgreen)
使用RDMA实现数据传输协议,彻底bypass网络协议栈和kernel的处理开销,进一步提升性能
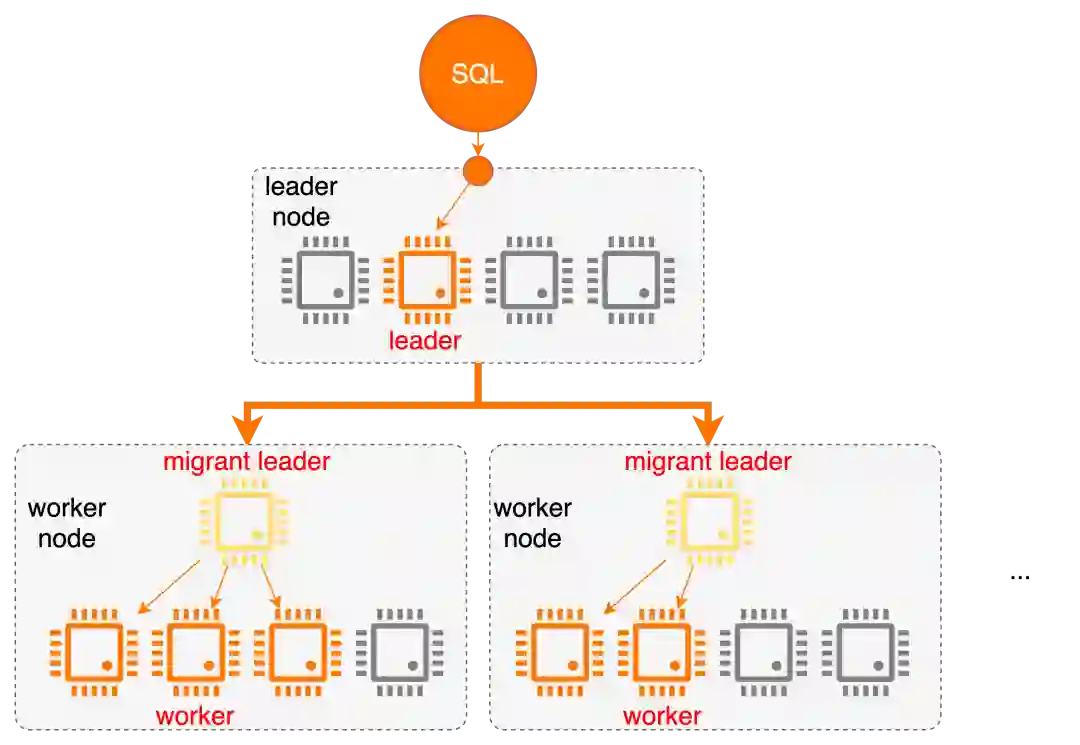
执行计划序列化

leader在完成分布式优化后生成物理计划片段的模板(类似MySQL的物理计划),然后序列化该模板
二进制的计划模板分发到各子节点的migrant leader上
migrant leader反序列化后,还原出本地计划模板和执行上下文信息(e.g variables/readview...)
各worker线程从本地模板中clone出自己的物理执行计划,实际执行
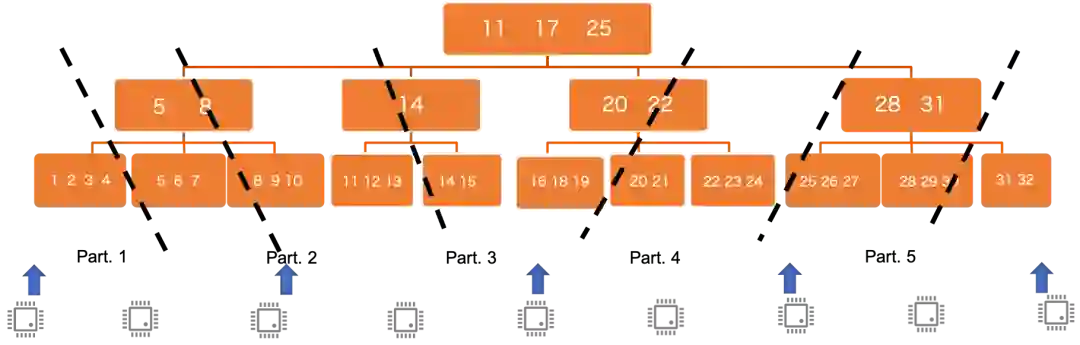
跨节点parallel scan
round-robin
pre-assign
查询内事务一致性
读写事务信息同步
全局一致位点的同步
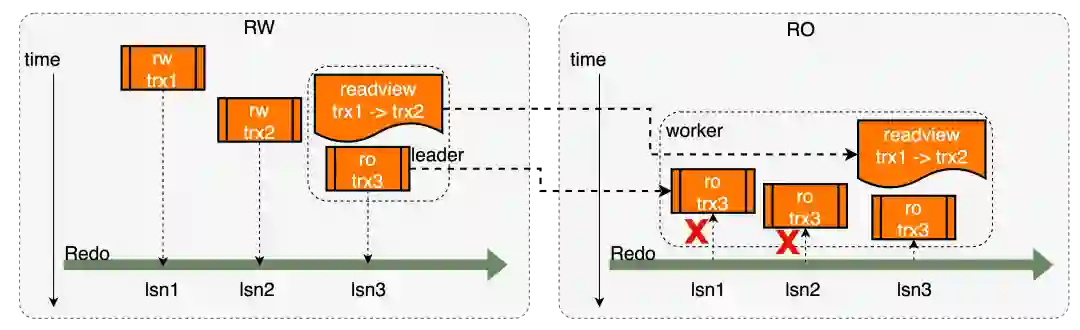
读视图的复制
基于资源的自适应调度
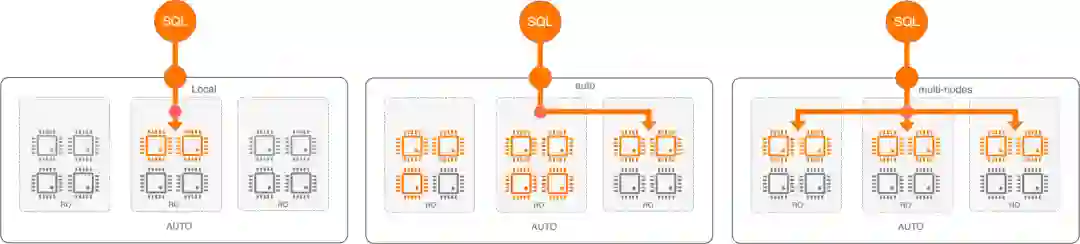
LOCAL
MULTI_NODES
AUTO(default)
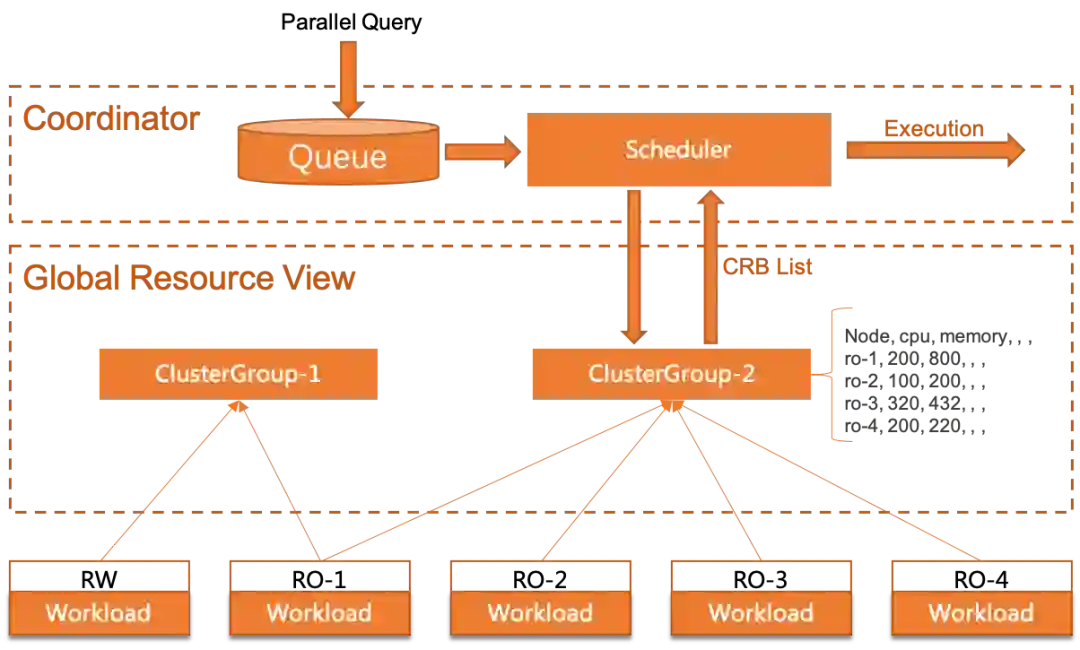
分布式任务调度器
全局资源视图
计算资源预算
计算资源预算(Compute Resource Bugdet. CRB)是对节点负载资源的一个评估值,代表该节点剩余的计算能力。由于资源信息广播是异步的,无法完全避免由于stall导致的不准确调度,为避免资源分配过载/不足,在计算单个节点的有效预算时我们引入了一个自适应因子,该因子会按如下策略调整:
连续N次负载信息无明显波动,factor上调10%;
连续N/2次负载信息有明显上升,factor下调20%;
目标节点并行资源耗尽,factor直接下调为0,禁止分配
worker分配CRB
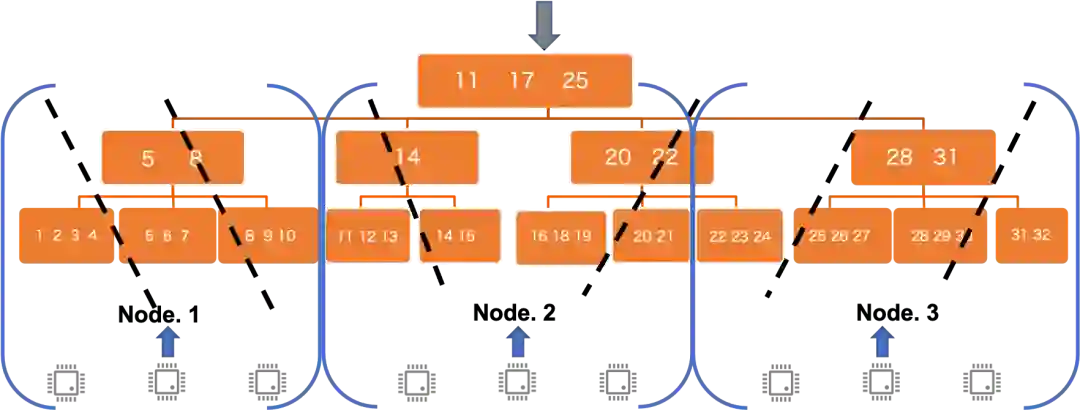
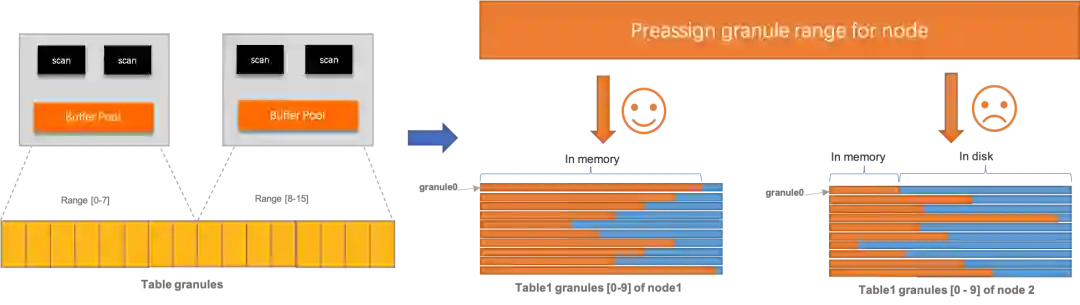
cache亲和度:针对最下层leaf workers生效,前面已提到,在为表切分granules时,会以pre-assign方式将各granules集合绑定到各节点上,每个worker会根据自己所属的granule range映射到目标节点,如果该节点有资源预算供该worker执行,则执行分发(复用节点中可能缓存的pages),否则只能调度到其他节点执行
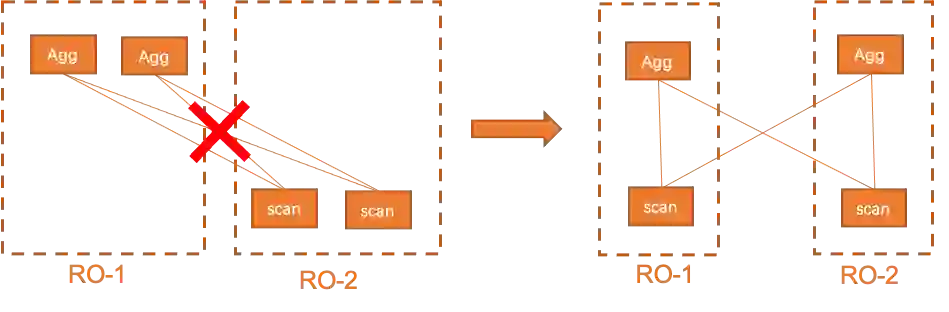
最小化跨机数据传输:针对非leaf workers生效,上层worker在分配时要参考下层worker尽量做"竖向"切分,减少跨机数据交互,例如下图左侧的数据分发总量会少于右侧
性能评估
set optimizer_switch="hash_join_cost_based=off";set cbqt_enabled=off;
单机 v.s 多机
CPU bound
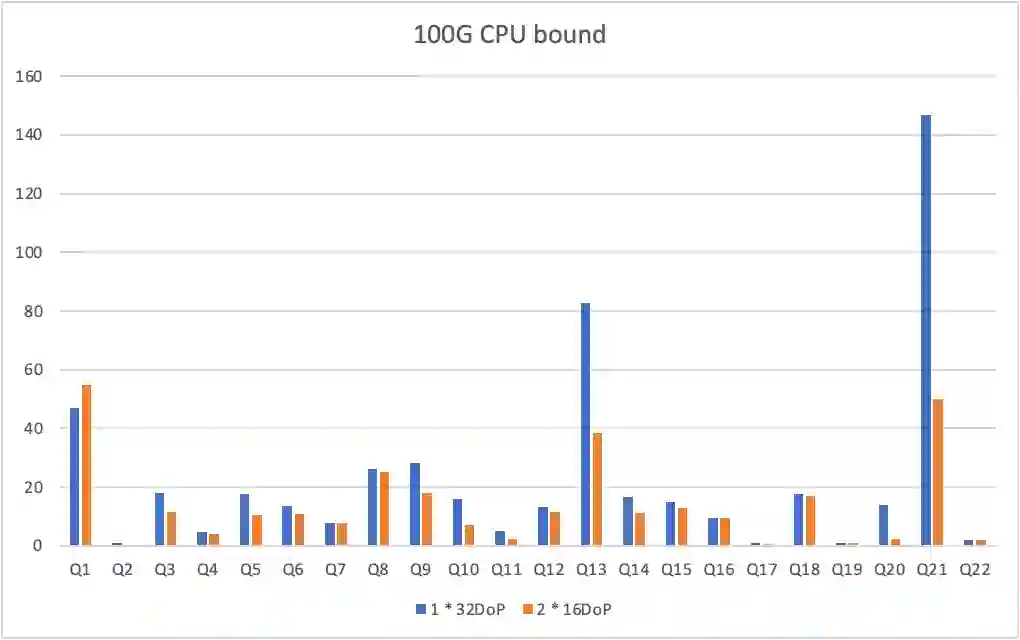
IO bound

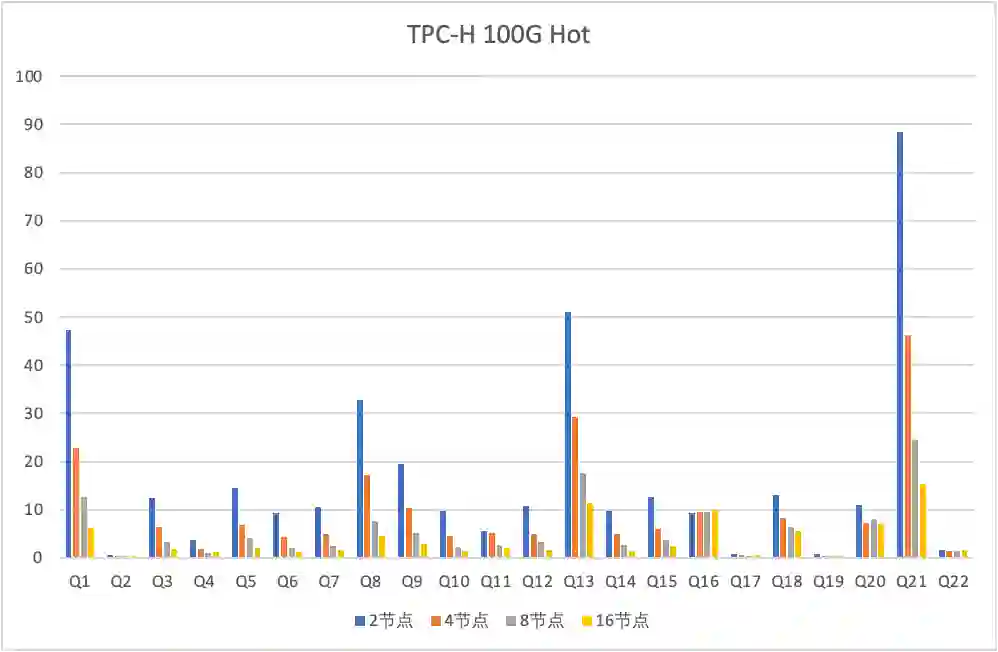
横向扩容
CPU bound
IO bound
在离线混合

Client-1连接oltp cluster,使用sysbench做短事务读写压测。
Client-1 暂停,模拟oltp业务空闲。
Client-2 开始直接连接ro3节点,观察qps。
Client-1恢复,将oltp cluster资源占满,此时观察Client-2的qps变化。
-
再次暂停Client-1的压力,观察Client-2的qps变化

在oltp cluster有压力时,Client-2的查询只在ro3节点内并行,吞吐也较低。
当tp业务空闲时,ap查询的负载分发到ro1/ro2节点,吞吐量立刻上升。
当tp业务再次繁忙时,ap的查询能力重新回落到单节点水平
TPCH
100G hot
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
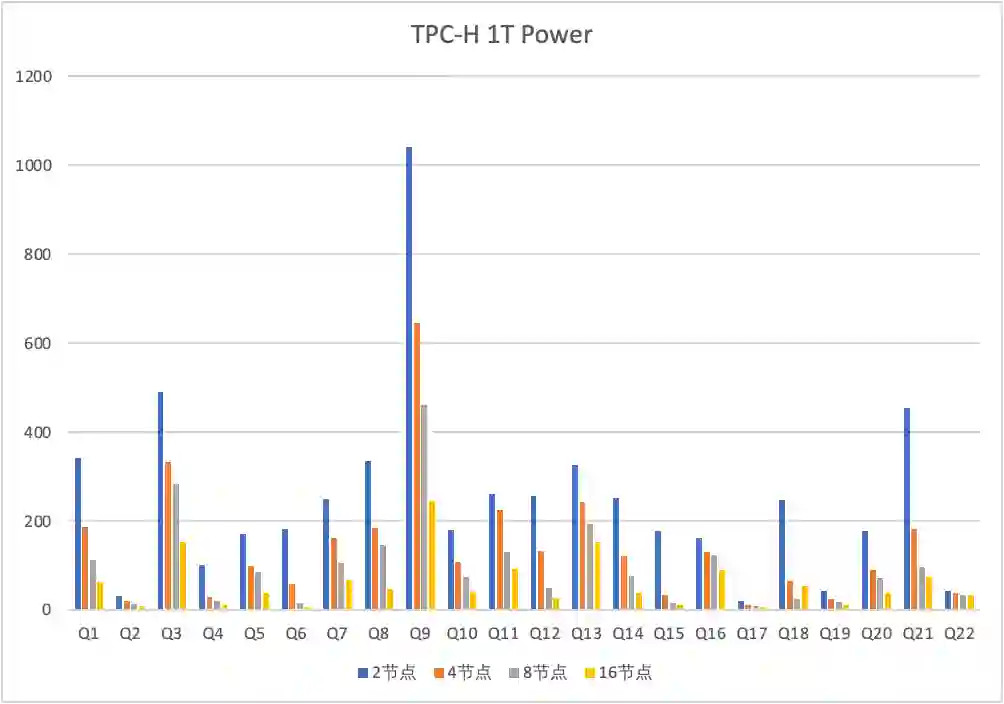
1T hot
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
总结与展望
增强MySQL原生优化器,给出更优的join tree形态(bushy join/hash join),解决大量nested loop index lookup产生的IO thrashing问题
进一步增强MySQL的统计信息能力,提升最优串行/分布式计划的准确性
使用RDMA作为数据通道底层协议
支持partition-wise join/cluster-aware partition-wise join
支持对导出到对象存储(oss)的冷数据做分布式查询
支持对各类外表的联邦查询
-
在分布式执行中引入自适应机制,提升执行效率
[1]https://help.aliyun.com/document_detail/128615.htm
[2]https://help.aliyun.com/document_detail/422032.html
[3]https://www.tpc.org/tpch/
推荐阅读
PolarDB for PostgreSQL 从入门到实战
PolarDB for PostgreSQL是阿里云自主研发的一款云原生关系型数据库产品,100%兼容PostgreSQL,采用基于Shared-Storage的存储计算分离架构,具有极致弹性、毫秒级延迟、HTAP、云原生、多模计算、金融级高可靠和高可用的能力,适用于高并发在线事务、实时复杂计算和查询分析、实时图文搜索、金融等业务场景。本书由阿里云及网易数帆、美创科技、CUUG、恒辉信达等开源生态合作伙伴共同出品,从安装部署到运维实践、开发工具,八大章节轻松入门 PolarDB for PostgreSQL 开源数据库。
点击阅读原文查看详情。
