一 前言
-
应用为主体:常见的数据架构都是以『应用』为主体,数据主要产生自应用。数据架构围绕业务来设计,通常是先定义业务模型后设计业务流程。由于业务之间区分度很大,每个业务都有截然不同的业务模型,所以数据系统需要具备高度『抽象』的能力,所以通常会选择关系型数据库这类抽象能力强的组件作为核心存储。 -
数据为主体:这类数据系统通常围绕『特定类型数据』进行构建,比如说围绕云原生监控数据设计的以 Prometheus 为核心的监控数据系统,再比如围绕日志数据分析设计的 ELK 数据系统。这类数据系统的设计过程通常是围绕数据的收集、存储、处理、查询和分析等环节来设计整套数据系统,数据具备统一的『具象』的模型。不同的场景有不同的数据系统,当某个场景具备通用性以及得到一定规模的应用,通常在开源界会诞生一套成熟的、完整的解决方案,比如说云原生 Prometheus、ELK、Hadoop 等。
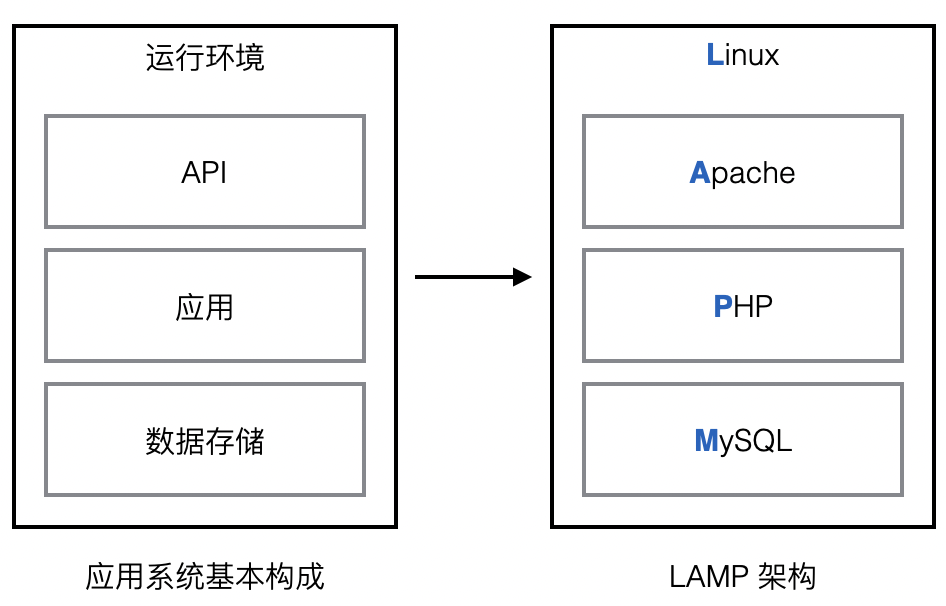
二 应用系统数据架构
1 传统数据架构(单一系统)
LAMP 架构
如何进行扩展
-
Scale-up vs Scale-out
-
Scale-up 即直接提升机器的配置规格,是最直接的扩展手段,计算和存储均可通过 Scale-up 的方式来进行扩展,但扩展空间有限,相对成本较高。Scale-out 即增加更多的机器进来,是相对成本更低、更灵活的手段,但需要相关组件具备能 Scale-out 的能力。
-
存储和计算分离
-
存储和计算是两个不同维度的资源,如果强绑定会极大限制扩展性。对数据系统来说,应用节点和存储节点分离就是应用了存储计算分离的设计思想,让应用和存储都能独立扩展。
-
存储 Scale-out
-
通常采用数据分片技术,将数据分散到多台机器上。
-
计算 Scale-out
-
基于状态路由计算:通常用于状态迁移代价大的数据架构,比如数据库的分库分表。分库分表的扩展需要进行数据复制,所以通常需要提前规划,根据数据所在分片来路由计算。
-
基于计算复制状态:如果状态能非常灵活的复制或者是共享,那可基于计算来复制状态,是一种更灵活的计算扩展架构。比如说基于共享存储的大数据计算架构,可灵活调度任意计算节点对数据进行处理。
-
无状态计算:计算不依赖任何状态,可以发生在任意节点上,所以计算节点可非常容易实现 Scale-out,但需要解决计算调度问题。常见 Web 应用中的 LoadBalancer 后置一堆 Web Server 就是一个简单的无状态计算扩展架构。
-
有状态计算:计算依赖状态,计算的扩展依赖状态的迁移。如果状态不可迁移,那计算的扩展只能采取 Scale-up 的方式。如果状态可迁移,那计算就可实现 Scale-out,此时计算的可扩展性依赖于状态迁移的灵活性。对于可 Scale-out 的计算我们分为两类实现方式,分别是:
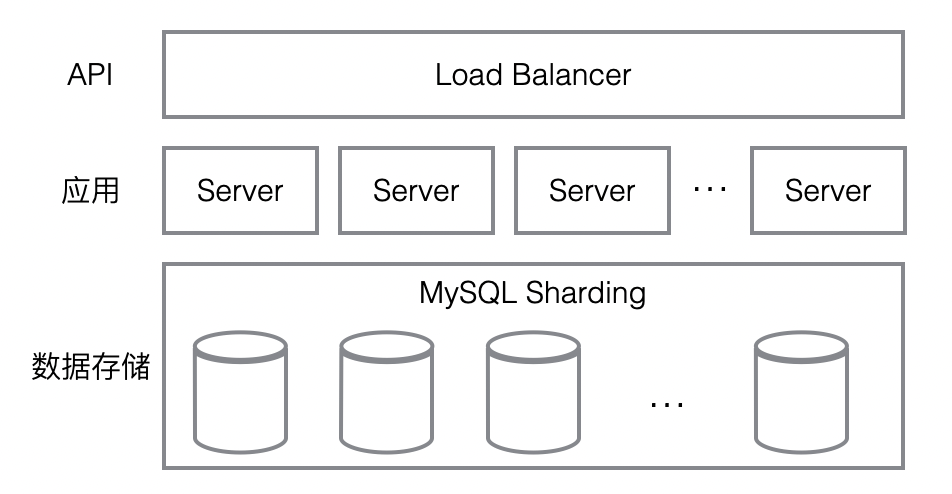
可扩展的传统数据架构
-
存储侧扩展灵活性差,扩展成本较高:计算侧通常是无状态计算节点,扩展相对灵活。但存储侧的扩展需要进行数据复制迁移,扩展周期长且灵活性差。同时 MySQL 的分库分表每次扩展需要双倍资源,成本也较高。
-
单一存储系统,提供的能力有限:MySQL 作为关系模型数据库,在业务模型抽象上提供极强的抽象能力,所以可以说是一个万能存储。在互联网早期应用负载不高的情况下,MySQL 是最优选择,且已经拥有了成熟的扩展方案。但是随着应用场景和负载不断变化,MySQL 还是难以承载。
-
存储成本高:简单来说,关系数据库是结构化数据存储单位成本最高的存储系统。
如何解决存储侧扩展问题
2 现代数据架构(多样化系统)
定义问题,分而治之
-
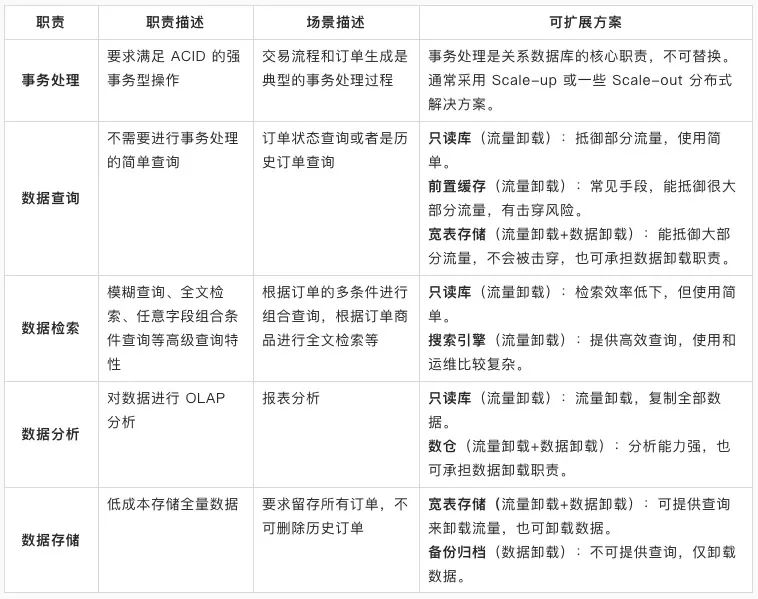
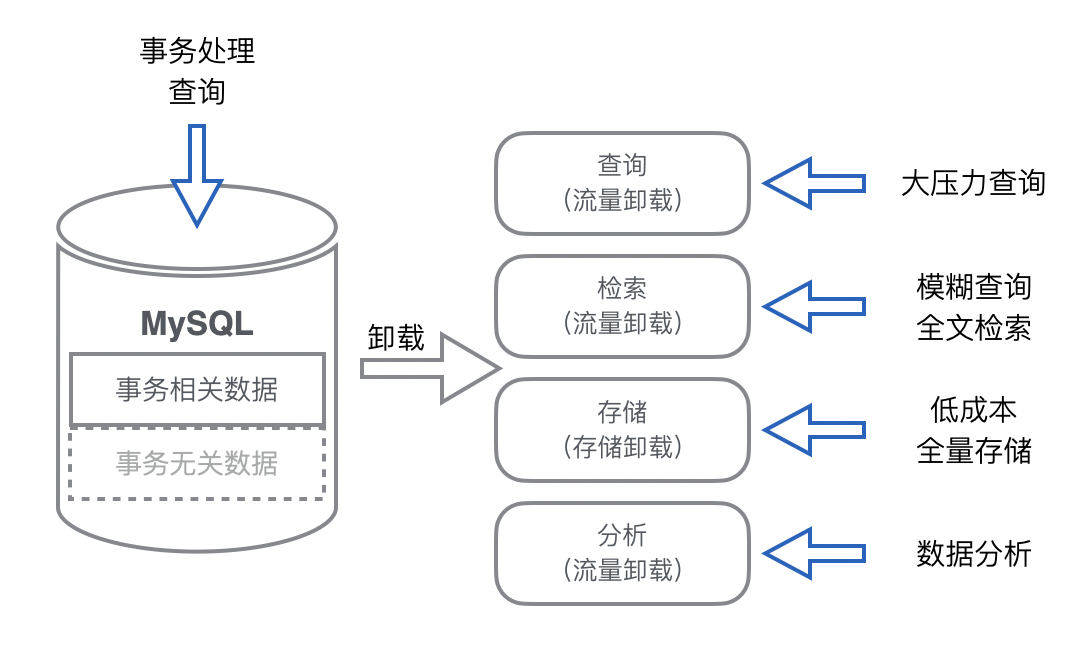
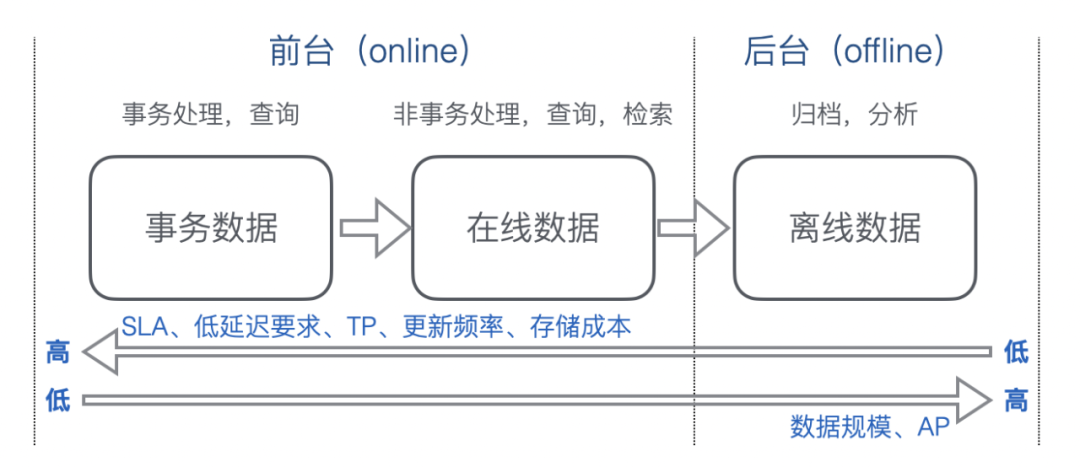
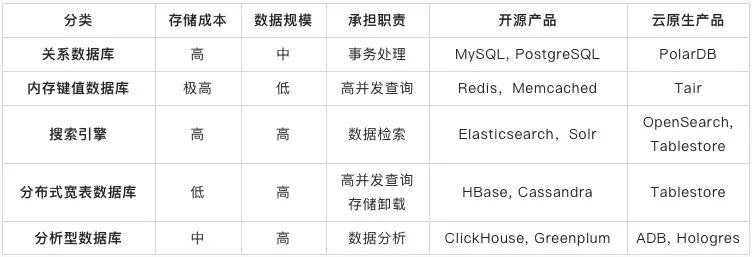
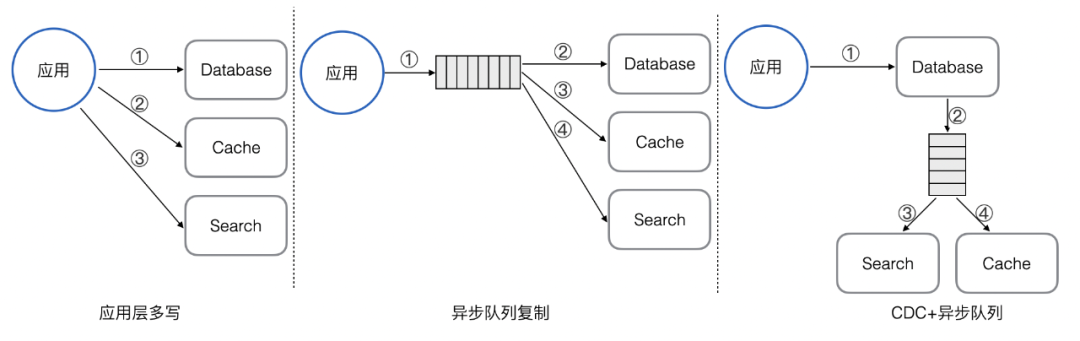
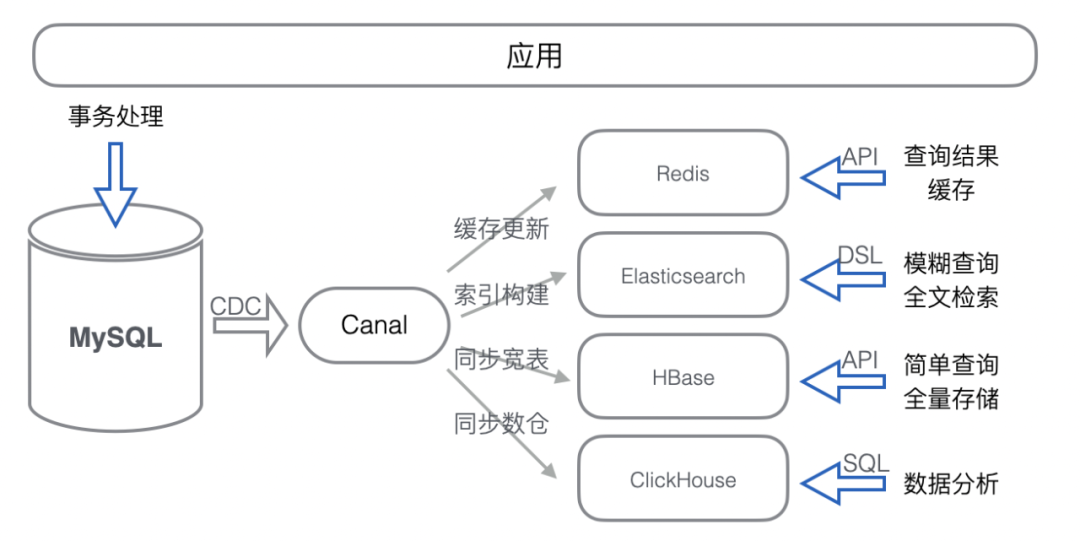
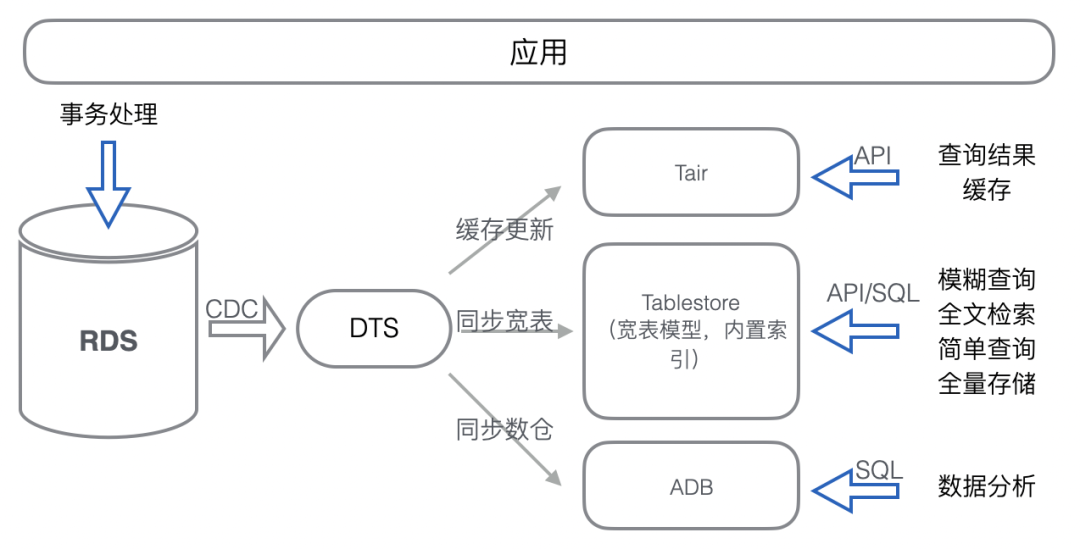
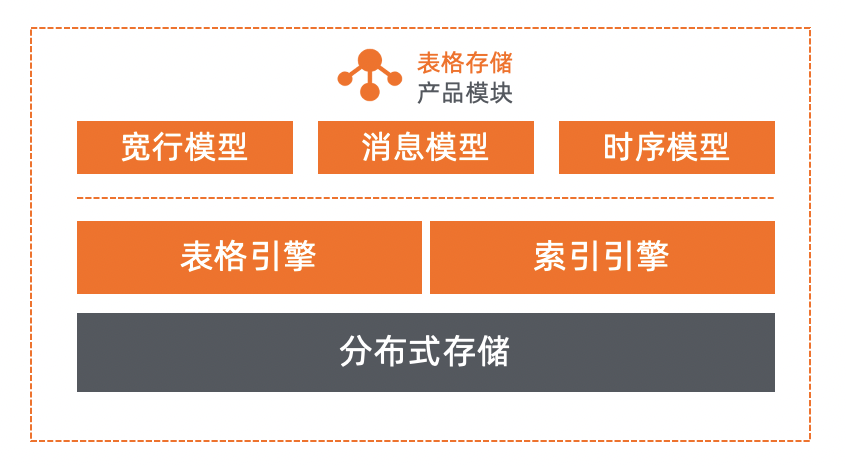
流量卸载:承载和抵御 MySQL 的部分读写流量,让 MySQL 有更多资源进行事务处理。由于读和写依赖 MySQL 内数据,所以在卸载流量的同时还会复制全部或者部分数据。 -
数据卸载:MySQL 内部分数据会用于事务处理,而部分数据仅存储和查询。不参与事务处理的数据可卸载,来降低表的存储量,对降成本和减负载都是有极大好处的。